No data for you!
Has this happened to you?
- "We need a copy of production data"
- "Why?"
- "For {staging | testing | baselining | repro-ing | exploring big data on Azure | doing my job }"
- "No."
Getting data can be done by taking a snapshot or copy of production data - like a transactional database backup or copying a set of data files - and bringing this data to the needed environment. But production data may contain sensitive information, such as Personally Identifiable Information (PII) or Protected Health Information (PHI). To protect customer privacy and comply with applicable regulations and compliance frameworks, such data is usually stored in secured environments, and subject to access and movement controls.
Such controls may prohibit providing the data - even to internal teams that need "real-world" data.
... Which means the answer to "We need production data" may be a completely justifiable - but very inconvenient - "No".
But we need that data. Now what?
We need data to move our project ahead. What are some strategies to consider?
Use public data
In some cases, data that is structured identically to production data is not needed. Many public data sets (like these and these) are available for development, testing, and training. The downside, of course, is that public data sets come with a pre-existing structure, so they will not be useful if your work requires your existing data structure, or any control over the data structure.
Scrub or mask
To mitigate concerns about inappropriate disclosure of sensitive data, "scrubbing" or "masking" approaches can obscure, alter, or remove sensitive data from copies or snapshots of the data (for example, see my post on Dynamic Data Masking). The specific approaches vary depending on the nature and sensitivity of the data, ranging from manual, to automated, to using tools like Delphix. In general, an understanding of the data - especially which elements are sensitive - is needed, though more sophisticated approaches or tools can infer what parts of the data need protection by looking for patterns like email address, social security or insurance number, and so on.
However, in highly regulated or very risk-averse environments, scrubbing or masking approaches may not be acceptable due to the concern of "what if we miss something, and inappropriate disclosure happens despite our scrubbing or masking measures?". Something as simple as finding (and scrubbing or masking) permutations of personal identifiers in large text fields, for example, can be challenging to automate with very high accuracy across many records.
Synthesize
When pre-defined data sets are not suitable, and when scrubbing or masking is not appropriate, we can consider synthetic data. This means artificially generating data that resemble our production data, and can be substituted for it. In this way, there is no risk of inappropriately disclosing sensitive data, since production data is not accessed or copied.
Initially, we need to mimic our production data structure. This is straightforward, as long as production file or database schemas (i.e. structures) are available.
Next, we need to think about how to generate the synthetic data. The right approach to generating synthetic data that is "close enough" to production data could start simple - for example, duplicate the same record thousands of times, perhaps with an auto-incrementing identifier field.
However, we will probably want to adopt a more nuanced approach to data synthesis that emulates, on a field-by-field basis, the characteristics of our production data as closely as possible.
For numeric fields, this may mean generating values in a set that has similar statistics to the production data: for example, a similar mean and standard deviation for normally distributed data, the same min and max for uniformly distributed data, and so on.
We may have fields constrained to one of a specific list of allowable values - in data science, known as a categorical feature or variable (for example, days of the week, or colors of the rainbow, or other closed sets). We may even want to weight individual values differently, so that one value appears more often than another.
We may also have fields that fall within a specified range - such as dates that fall within a start and an end date - or fields that we want to generate dynamically, perhaps via some sort of code fragment or anonymous function.
The more dynamic, real-world, and closer to production data we want our synthetic data to be, the more effort we will need to invest in analyzing our production data's characteristics and finding ways to emulate these characteristics at scale. There are many ways of doing this; the details will depend on our environment and controls. (Azure Machine Learning and Azure Data Catalog provide excellent data summary statistics.)
Generator Tool
I wrote a file data generator tool for a recent project where a new environment was being architected in Azure. Validation of this environment required system and load testing with real-world (volume and variety) data. Production data was highly sensitive, there was no non-production data available, and implementing scrubbing/masking was not realistic in our timeframe. The synthetic data generated with this tool enabled environment validation - and the project - to continue.
The rest of this post discusses the tool I wrote, what it does, how it does it, how you can use it, and what else is planned for it. I called it the Synthetic Data File Generator (or sdfg below) because sdfg is easy to type and because I don't have an MBA in catchy product naming.
How can you use sdfg?
First, let's get off to a quick start. We'll get sdfg onto your machine and ensure it runs. Then, we'll dive deeper into a technical discussion.
Quick Start
| You will need a machine running Windows 10 x64, or Windows Server 2016 x64. (Why? See Technical Details, below.) | |
Go to https://github.com/pelazem/syndatafilegen/tree/master/run and download sdfg-win10-x64.zip. |
|
| Extract the zip file contents on your machine. | |
| Open a command prompt in the folder where you extracted the zip file. | |
Start by typing just sdfg. You'll see a prompt that you need to specify the path to a runfile. |
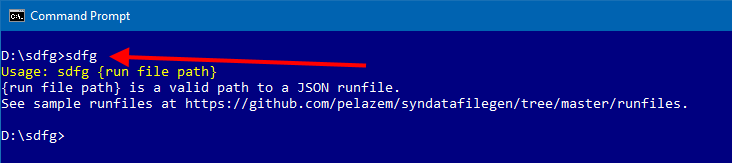 |
What is a runfile? Briefly - a runfile contains your instructions that tell sdfg what synthetic data files to generate. See below for a detailed discussion.The zip file you downloaded includes a /runfiles folder that contains several example runfiles; these are also available at https://github.com/pelazem/syndatafilegen/tree/master/runfiles. We'll start by using one of those. |
|
I used the csv.json runfile, which instructs sdfg to generate comma-separated values (.csv), at hourly increments over 30 days, with 100-200 records per file. As you can see, that took a little over three seconds. |
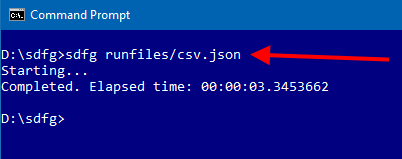 |
| File Explorer shows that sdfg generated 744 .csv files. These are small files and a small amount of data, but if you have gotten this far, you have run sdfg and our Quick Start is successful. | 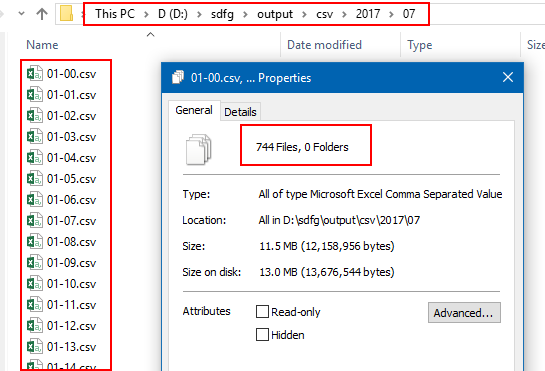 |
| A quick look inside one of the generated .csv files shows, yes, comma-separated data. | 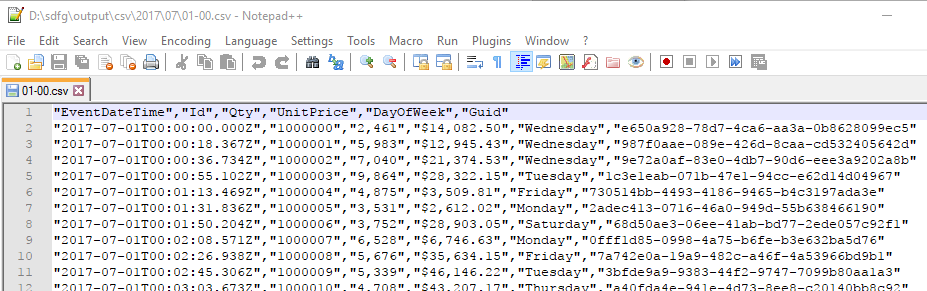 |
Runfiles
Now that we have generated a first set of data files , I'll discuss runfiles: what they are, how they are structured, and how you can create your own for your specific file structures.
Runfiles are JSON files that describe the synthetic data files to be generated. A runfile contains all the information sdfg needs. (My goal was to enable a zero-code experience, and require only a text editor to customize sdfg output.)
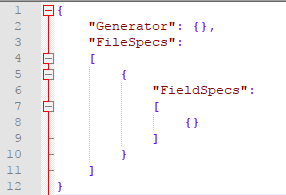
sdfg runfiles include the following elements:
|
 |
Let's examine runfiles in more detail.
For reference, please consult /runfiles/TEMPLATE_FULL_RUNFILE.json, which is available both in the .zip download as well as at https://github.com/pelazem/syndatafilegen/tree/master/runfiles. This runfile is a template that includes all supported keys and values, with explanatory comment for each.
Thus, while I'll discuss several important elements below, please consult this template for details as you build your own runfile. In particular, some elements are constrained to a set of allowable values (for example, which file type you need, such as CSV or fixed-width), and the template runfile documents those.
Generator
Generator is a top-level element. Generator contains OutputFolderRoot and DateStart/DateEnd child elements.
OutputFolderRoot is a relative or absolute path on the local machine's file system. This is the root folder under which generated files will be written by sdfg.
The dates are used for two purposes: first, if output file paths include date/time tokens (see below), dates from within this range are substituted for the tokens and second, if so specified, dates from within this range are written to the output files as a "when did this record occur" event date/time tracking field.
FileSpecs
Runfiles include one or more elements under FileSpecs. This means that a runfile can include instructions to generate multiple file sets. For simplicity, keep it to one FileSpec element at first.
I'll discuss several FileSpec child elements here; others are simple and self-explanatory. See /runfiles/TEMPLATE_FULL_RUNFILE.json for full details.
FileType is the output file type. Currently, these are supported: arff, avro, delimited, fixedwidth, and json.
RecordsPerFileMin and RecordsPerFileMax specify a range for how many records should be written to each generated file. The exact number of records will be randomly generated for each file from within this range. (After all, in the "real world", data files don't all have the same exact number of records either.) Need to specify an exact number anyway? Just set both values to your exact record count.
PathSpec is how you tell sdfg what folder and file names to generate. You can specify an explicit path here (such as "output/myfile.csv"), or you can provide a tokenized value. This tells sdfg to iterate from Generator/DateStart to Generator/DateEnd, and to replace appropriate parts of your PathSpec with the corresponding date/time as it iterates through your date range. Let's illustrate with a couple of examples.
"PathSpec": "{yyyy}\\{MM}\\{dd}\\{hh}{mm}{ss}.txt"will generate output files under a year folder, then a month folder, then a day folder, then a file named for the hour, minute, and second, with a .txt extension. For example: 2017\\07\\18\\145325.txt"PathSpec": "{yyyy}-{MM}-{dd}-{hh}.arff"will generate output files with a filename of year-month-day-hour and a .arff extension. For example: 2017-07-18-14.arff"PathSpec": "{yyyy}\\{MM}\\{yyyy}-{MM}-{dd}-{hh}.csv"will generate output files under a year folder, then a month folder, then a file named for the year, month, day, and hour. For example: 2017\\07\\2017-07-18-14.csv
Notes on PathSpec: as you see, you can use a token (like {yyyy} in the last example) more than once, in both folder and/or file name specification. Also, note the double backslashes (\\): Windows paths use a backslash, but backslash is also the escape character in JavaScript so in a JSON file, I have to use \\ to mean \.
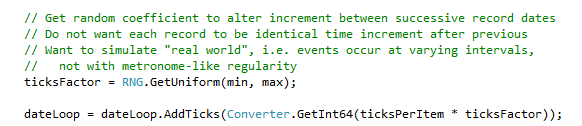
FieldNameForLoopDateTime is the field name to which you would like an event date/time written. This is optional. If you specify it, then as sdfg iterates from Generator/DateStart to Generator/DateEnd, as each record is generated, the "current" date/time within this range is written to it. This is a great way to simulate event log files, which have a strictly increasing event occurrence date/time field on each record.
As sdfg iterates through Generator/DateStart - Generator/DateEnd, the incremented loop date/time is adjusted at each iteration with a random coefficient so that successive records are not always incremented by the identical time interval. In other words, a little bit of event interval "jitter" or irregularity is introduced.
Delimiter and Encloser specify strings used to separate (delimit) and enclose, respectively, values in each generated record. These are used only in delimited or fixed-width files. They can be one or more characters long.
Using "Encloser": "\"" (note that since this is JSON, I have to escape the double quote symbol, hence the backslash) specifies that each value should be enclosed in double quotes; this is very useful, for example, when generating .csv files with numeric fields that are formatted with a thousands separator which, in some languages/cultures, is a comma.
Enclosing values with commas in double quotes prevents downstream consumers of these files from mistakenly interpreting a thousands separator as a delimiter between fields.
Thus, in this fragment of a .csv record "1000000","2,461","$14,082.50","Wednes..., there are two numeric fields present. The first is 2,461; the enclosing double quotes ensure that this value does not get split into 2 and 461 downstream. Similarly, the enclosing double quotes ensure that $14,082.50 is not split into $14 and 082.50 downstream.
Three elements are available for fixed-width files.
The first, FixedWidthPaddingChar, specifies what character to use to pad (i.e. fill to the specified width) a field in a fixed-width file where the value is shorter than the field length. For example, if I have a field with a width of 20 characters and I generate a value of "123" for it, sdfg will add 17 of the character specified for FixedWidthPaddingChar so that exactly 20 characters will be written to the field.
The value specified for FixedWidthPaddingChar must be exactly one character long. Typically, this is a space.
FixedWidthAddPadding and FixedWidthTruncate specify where to pad too-short values, and where to cut off too-long values, respectively. Both are constrained to either of two allowable values: "AtStart" or "AtEnd". This lets you control whether too-short values (like in the previous example) are padded out to the field width before or after the value, and whether too-long values are truncated (cut off) at the right or at the left.
Each FileSpec also contains a list of FieldSpec elements, which are discussed next.
FieldSpecs
Each FileSpec element contains a list of FieldSpec child elements. Each FieldSpec element describes how that field should be generated. (In many, but not all, file formats a field is just a column. Because not all file formats are columnar, though, I use the term field rather than column throughout.)
As with FileSpec above, I'll discuss the most important FieldSpec configuration elements below. Again, see /runfiles/TEMPLATE_FULL_RUNFILE.json for full details.
FieldType designates the type of data that sdfg will generate for this field. Currently, this is limited to one of the following allowable values: Categorical, ContinuousDateTime, ContinuousNumeric, Dynamic, and Idempotent. Let's examine each of these.
Categoricaldesignates a field whose generated values are randomly selected from a list of allowable values which you specify separately (seeCategoriesbelow).ContinuousDateTimedesignates a field whose value will be randomly generated from a min/max range which you specify separately for the field (seeDateStartandDateEndchild elements ofFieldSpec).ContinuousNumericdesignates a field whose value will be a number randomly generated based on the additional configuration you specify, includingNumericDistributionandMaxDigitsAfterDecimalPoint.Dynamicdesignates a field whose value is generated from a C# anonymous function you specify (compiled at runtime using .NET Roslyn) separately in theDynamicFuncelement (see below).Idempotentis used in advanced scenarios when you pass in already-existing data programmatically, using sdfg's file format serialization capability without its data-generating capability. See below in this post for discussion of interacting with sdfg's engine programmatically.
EnforceUniqueValues specifies whether sdfg should ensure that, per file, the values generated for the field are unique, i.e. that no values are repeated in this field throughout the file. By default, this is set to false. Setting it to true increases sdfg's memory usage and compute time, so ensure you really need it before setting it to true.
FormatString is an optional .NET format string. If specified, it will be used to format the generated output. For example: "FormatString": "{0:c}" formats the generated value as a currency; "FormatString": "{0:n0}" formats the generated value as a number with zero digits after the decimal point; and so on. See /en-us/dotnet/standard/base-types/formatting-types for details on .NET formatting strings.
PercentChanceEmpty optionally enables sparse data. The default is zero. If set to a value greater than zero, then as each record is generated, in the field where this is specified, there will be that percent chance that the generated value will be empty. This is to enable generation of files that, like the "real world", may have missing data in some records.
I implemented this as a probability per record. So, if you specify 15 here (for 15% chance a given record's value will be "empty"), the final output file will have a percent of empty values in this field that is close to 15, but not necessarily exactly so. This also yields (hopefully) more realistic files where, even if you specify the same value for PercentChanceEmpty on two fields, the generated records will have some records where neither field is empty, some where one but not both is empty, and some where both fields are empty. In other words, I tried to avoid artificially neat generated data.
Since this is specified per field, generated files can be very finely tuned to resemble real data. For example, if production files always have an event date/time and a record ID, but sometimes have empty values in transaction or event fields, this setting enables simulating such a scenario on the applicable fields that sometimes are missing data.
Similarly, EmptyValue enables specification of a string value to be written to the output when the value generated for a record in this field comes up as "empty". By default this is an empty string, but can be set to other values as needed. Again, this is set per field for maximum control over the output.
FixedWidthLength specifies the size for the field in a fixed-width file. It is ignored in other file types.
FixedWidthPaddingChar, FixedWidthAddPadding, and FixedWidthTruncate are all optional per field. If specified, they will override the same-named file-level settings. This enables you to optionally format each field in a fixed-width file individually if the file-level defaults are not applicable across all fields in the file. These are ignored for file types other than fixed-width.
Categories is a list of allowable values for a Categorical field. Optionally, values can be weighted so that some values will appear more often than others in the generated files. Weights are normalized by sdfg during processing, so you can specify any positive values that you like.In the screenshot, I provide days of the week as my allowable values. I have weighted the days differently; for example, Friday is weighted 1.0 and Saturday is weighted 0.25, which means Friday is four times as likely to occur in the output as Saturday. |
 |
NumericDistribution designates the distribution, and associated parameters, to be used to generate random values for a ContinuousNumeric field.
Currently, the DistributionName is limited to one of these allowable values: Beta, Cauchy, ChiSquare, Exponential, Gamma, Incrementing, InverseGamma, Laplace, LogNormal, Normal, StudentT, Uniform, and Weibull.
Each of the DistributionName values require associated parameters to configure the sdfg random number generator correctly. For example, if you specify "DistributionName": "Normal", you will also need to specify values for Mean and StandardDeviation. Similarly, if you specify "DistributionName": "Uniform", you will also need to specify values for Min and Max.
As before, consult /runfiles/TEMPLATE_FULL_RUNFILE.json for details. The numeric distribution element and its child elements are exhaustively documented there, with the parameters required for each distribution clearly designated.
DynamicFunc is where you provide a C# anonymous function for a Dynamic field. This function will be used to generate a value for this field on each record. Specifically, you need to provide a function that takes no parameters and emits an object.
For example: "DynamicFunc": "() => System.Guid.NewGuid()" generates a new GUID (globally unique identifier) on each row. What could you do here? You could call a REST API, for example. Note that this function is called for every record, so that a computationally intensive (read: slow) function will significantly increase the time sdfg takes to generate your files.
Conclusion
This semi-exhaustive look at the internals of sdfg runfiles will hopefully help you build your own runfiles and generate synthetic data files for your specific scenario.
Next, we'll discuss how you can use sdfg without runfiles.
Advanced Scenarios
Using sdfg with a runfile, as discussed above, is convenient in that it only requires you to edit a JSON runfile in a text editor. This approach works very well to generate standalone files. But what if we need to generate sets of related, differently structured files?
What if one file, for example, needs to use categorical values (i.e. the set of allowable values) which were generated for another file in the set? In this scenario, using sdfg with a runfile will not work, as the runfile approach generates one type of file at a time.
(In future, sdfg may be enhanced to support runfiles that lay out multiple related files, and support the ability to link a Categorical field's Categories list to the output of another FieldSpec. If I get feedback that this is needed at the runfile level - i.e. without needing to dive into code - I will prioritize that feature. In the meantime, let's look at how to do this programmatically with sdfg.)
To continue in this section, it will be very helpful if you've cloned the sdfg github repo (https://github.com/pelazem/syndatafilegen) to your machine. You'll need Visual Studio 2017 (any edition) with the latest update (currently release 15.3) and the .NET Core 2.0 SDK installed.
Opening the solution in Visual Studio, we see the sdfg main projects: SynDataFileGen.App and SynDataFileGen.Lib. |
 |
The CCLF17 solution node contains a separate application that programmatically uses the sdfg engine to generate file sets relevant in US health care. Specifically, this application generates file sets in accordance with the Centers for Medicare & Medicaid Services (CMS) Accountable Care Organization - Operational System (ACO-OS) Claim and Claim Line Feed (CCLF) specification for 2017, version 18.0.
This file set, provided to Accountable Care Organizations (ACOs), typically contains extensive PII and PHI data. ACOs and other organizations processing these files need to accommodate large files containing sensitive data, whose structure can change over time. Load-testing a new processing environment that is not yet security-hardened and compliant is impossible with the real files due to their sensitive content; that was the motivation for writing the CCLF17 application.
The following screenshot shows an example method (in CCLF17.Lib/CCLFGenerator.cs) which uses sdfg entities (IFieldSpec, FileSpecFixedWidth, Generator, and WriterLocalFile) to first prepare the appropriate field specifications (in a separate helper method), then instantiate a file spec for generating fixed-width files, then instantiating the sdfg Generator with values for the configuration items we discussed above (e.g. output folder, start and end dates) and running it.
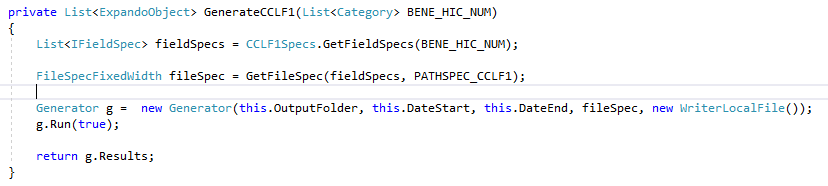
Note that the generator's results - i.e. the records generated for this file - are returned from this method. That's because this CCLF17 application implements the scenario I discussed above, where one file may have Categorical fields whose allowable values are generated for another file. By returning the generated records here, I am enabling code that coordinates between the different files and ensures that one file's generated values serve as the categorical, allowable values for another file.
The next screenshot shows code that calls the method in the previous screenshot, stores its results in an overall list (CCLF1S), then extracts a list of categorical values (CUR_CLM_UNIQ_ID).
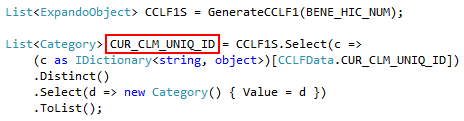
And finally, the next screenshot shows the categorical value list we extracted in the previous call (and previous screenshot) being passed into the next file generation method, where it will be used as the allowable value list for a categorical field. In this way, we have dynamically generated a list of values for one set of files, then we use those dynamically generated values to constrain related fields in other files.

I won't cover more of the CCLF17 codebase here. Its overall structure is simple; there is extensive code to implement the structural details of the source file set, but it's fairly repetitive and if you are familiar with Visual Studio and .NET development, you'll have no trouble understanding it. Feel free to examine it and contact me with questions or comments.
In summary, the github repo contains a solution that includes both the core sdfg utility - which outputs the executable we invoked in the Quick Start above - as well as a separate application that interacts with sdfg programmatically to implement a complex scenario that is (currently) not feasible with a JSON runfile.
Performance
sdfg's performance will vary based on the specs of the machine you run it on, and how complex you make your runfile (especially that DynamicFunc!).
For a point of reference, I used the sample csv.json runfile for three separate sdfg runs. In each run, I only changed the FileSpec/RecordsPerFileMin and FileSpec/RecordsPerFileMax values; for each run, I multiplied them by a factor of 100X from the previous run.
As you can see in the following screenshot, I used ranges of 100-200; 10,000-20,000; and 1,000,000-2,000,000 records per file. The sample csv.json runfile generates 744 files - one file per hour for 31 days.
Let's examine a few of the results.
On run 2, generating over 11 million total rows took less than 2 minutes; and while run 2's min and max records were scaled 100X compared to run 1, total time to execute scaled by 31X.
On run 3, I generated over 1.1 billion records in less than 2.5 hours; the generated files added up to 115 GB. Remember: this is with randomly generated data (including a DynamicFunc) on every single record.
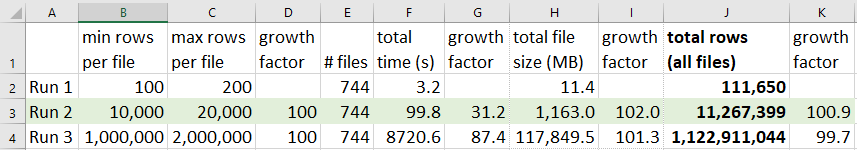
Technical details: these tests were run on a Windows 10 Pro x64 machine, Creators Update (1703), with an Intel Core i7-6700 CPU, 32GB of RAM, and Samsung 850 Evo SATAIII SSD. The machine was otherwise loaded (i.e. not quiesced for max performance), running antimalware and other applications. This was a Release build of sdfg.
Technical Details
I wrote sdfg (and the CCLF17 application) as a .NET Core application and a .NET Standard library. Currently, sdfg is at .NET Core/Standard 2.0.
The zip file you downloaded in the Quick Start is named sdfg-win10-x64.zip, and I said you need a Windows 10 x64 or Windows Server 2016 x64 machine to run it. Why the OS and x64 architecture constraint? Because .NET Core gives us the ability to ship the runtime with the application! In the Quick Start, I didn't say your machine needed .NET vAnything, right? That's because the zip file contains all the .NET it needs. Your machine doesn't need to have it installed just to run sdfg.
This is a change from the .NET Framework (currently 4.7), which did require a system-wide installation. Distributing an application built for .NET 4.7 required you to have that .NET framework installed on that machine. By contrast, distributing an application like sdfg as a self-contained application means you can deploy multiple applications, each potentially built on a different version of .NET Core, without risking negative effects due to a different version of .NET than you built on.
The downside to distributing an application like sdfg self-contained (i.e. shipped with all needed .NET Core files) is that the .NET Core files themselves are OS-specific. Hence, while we gain isolation and safety (no risk of .NET framework version issues), we also have to build per OS and architecture. I provide sdfg for 64-bit versions of Windows 10 and Windows Server 2016; if there is a significant need for another platform, contact me or feel free to clone the repo, add the needed support, and send me a pull request.
To work in the sdfg code after you clone the repo, you will need Visual Studio 2017 with the latest update (currently 15.3) and the .NET Core 2.0 SDK - not just the runtime - installed.
The DynamicFunc field discussed above enables you to write a C# anonymous function into the JSON runfile, and have it evaluated at runtime using Microsoft Roslyn technology. See SynDataFileGen.Lib/Factory.cs/GetFunky().
Currently, sdfg is limited internally to a maximum of 250 million (250,000,000) records per file. If you specify a value for FileSpec/RecordsPerFileMax that exceeds 250,000,000, it will be reset to 250,000,000.
Conclusion and Future
I hope the above discussion of scenarios where synthetic data is valuable, and of a synthetic data file generation tool I wrote for such scenarios, is helpful. Please contact me with questions or comments. If sdfg is useful to you, I would greatly appreciate it if you let me know. Similarly, if you clone it and improve the code, please send me a pull request!
What's next for sdfg? A few ideas I am thinking about:
- Enable runfiles to generate related files with cross-file references to generated values for categorical allowable value lists
- Remove the per-file max records limit of 250,000,000
- Implement a
ContinuousNonNumericfield type to generate random non-numeric values without requiring aDynamicFunccode fragment - Add support for outputting files to other locations than the machine's file system. For example: Azure Storage
Separately: is there a need for a tool like sdfg that "understands" a relational database's schema and generates synthetic data in it, including respecting key relationships? Let me know your thoughts!
Resources:
The sdfg github repo: https://github.com/pelazem/syndatafilegen
Comments
- Anonymous
August 28, 2017
Looks like just the ticket. Can't wait to tuck in. - Anonymous
August 28, 2017
Nice to see your work in this article ... thanks for sharing!