Quand le Deep Learning permet l’apprentissage par renforcement des robots industriels – 1ère partie
Les vacances sont aujourd'hui bel et bien finies et nous vous proposons de reprendre le cours de nos échanges sur le #DeepLearning et ses cas d'usage concret et justement, pour rentrer dans le « vif du sujet », nous vous proposons aborder le sujet de l'apprentissage par renforcement pour les robots industriels.
J'en profite pour remercier très sincèrement Morgan Funtowicz qui a conduit de bout en bout cette étude et sa mise en œuvre associée.

A travers une série de billets que nous initions ici avec ce premier billet, nous souhaitons donc vous présenter et partager ensemble une étude récemment réalisée dans le cadre d'une collaboration avec KUKA Robotics.
 Comme décrit sur son site ici, « en tant que pionnier en robotique et technologie d'automatisation, KUKA fait partie des fabricants de robots industriels leaders dans le monde. KUKA couvre presque tous les types de robot et toutes les capacités de charge avec une sélection unique et variée de robots industriels. »
Comme décrit sur son site ici, « en tant que pionnier en robotique et technologie d'automatisation, KUKA fait partie des fabricants de robots industriels leaders dans le monde. KUKA couvre presque tous les types de robot et toutes les capacités de charge avec une sélection unique et variée de robots industriels. »
Ainsi, dans le cadre de cette collaboration entre KUKA Robotics et Microsoft France, nous avons souhaité allier l'expertise du groupe KUKA et notamment celle de ses robots industriels à la puissance de l'infrastructure « cloud » de Microsoft Azure.
Dans cette dynamique, l'étude et le projet associé font intervenir les compétences robotiques de KUKA, en particulier via son robot industriel à 7 degrés de liberté, le LBR IIWA 7 R800.
Ce dernier offre des possibilités (presque) sans limites. Pour vous en convaincre, vous pouvez visiter le site dédié sur le site https://www.kuka-lbr-iiwa.com/ où vous trouverez de nombreuses vidéos et des exemples d'application.
Que dire alors des synergies possibles avec l'environnement Microsoft Azure ?
Microsoft Azure est composé d'une gamme croissante de services cloud intégrés (analyse avancée de données, puissance de calcul, lac de données et bases de données SQL et NoSQL, stockage et services web, etc.), de modèles prédéfinis, d'outils intégrés qui permettent de créer et de gérer facilement et rapidement des applications d'entreprise, mobiles, web et IoT (objets connectés), et ce en faisant appel aux compétences et technologies existantes ; ce qui aident de fait nos clients et partenaires à atteindre des objectifs plus grands, plus rapidement et sans augmenter leurs coûts. (Pour la deuxième année consécutive, Microsoft Azure est le seul fournisseur classé par le Gartner dans le top 4 des cinq « Magic Quadrants » pour l'infrastructure cloud en tant que service, la plateforme d'application en tant que service et les services de stockage dans le cloud.)
Si le champ des possibles s'étale devant nous, notre ambition pour ce projet de collaboration s'articule (comme le titre du billet le suggère) autour de la mise en œuvre d'une méthode d'apprentissage par renforcement, sans supervision spécifique, d'un processus de saisie de pièces par ce robot industriel au moyen d'une pince.
Le scénario envisagé ici concerne la mise en œuvre d'un processus de recyclage automatique de certains types de déchets. L'idée s'est portée sur le recyclage des boissons, (canettes de soda, bouteilles d'eau et tasses de café papier) et dont le tri s'effectue dans 3 containeurs différents.
L'idée consiste donc à mettre en place un système autonome se basant i) sur l'image qu'il perçoit de l'objet à trier et ii) sur un modèle de Deep Learning afin d'en déterminer le bac de destination.
Commençons par voir ensemble ce que cela suppose en matière d'environnement et de contraintes afférentes.
Un environnement et des contraintes
Dans la pratique, le robot industriel se doit d'être en mesure d'appréhender son environnement d'exécution, et ce, en restreignant au maximum les limitations fixées par un facteur humain.
Pour cela, cette opération peut être réalisée via une caméra observant la scène. Une telle approche avec une caméra unique possède plusieurs avantages, dont principalement, vous en conviendrez, la simplicité de mise œuvre.
Pour autant, afin de pallier à tout risque inhérent à l'utilisation d'un robot dans un environnement réel (s'opposant à un environnement simulé), le robot doit être réglé de manière à assurer au maximum la sécurité de lui-même, et bien évidemment des personnes pouvant se trouver à proximité. Pour cela, un environnement d'exécution est défini sur ce dernier. Ainsi, il est impossible pour le robot de s'aventurer dans des positions qui seraient extérieures à cet environnement prédéfini.
Les actions du robot, au sein de l'environnement d'exécution, son bac à sable en quelques sortes, sont quant-à-elles sous la responsabilité du roboticien, en l'occurrence, les personnes impliquées directement dans l'étude.
Il va donc de soi que des mesures doivent être prise en compte sur les algorithmes mettant en œuvre les mouvements du robot. Toutes ces mesures seront détaillées plus en détails dans la section intitulée La génération des mouvements (Servoing).
Vous avez dit « Apprentissage par renforcement » ?
Le fait de superviser le moins possible l'apprentissage du robot, et de le laisser appréhender son environnement fait en soi référence à de l'apprentissage par renforcement.
Dans ce genre d'apprentissage, un agent (KUKA ici) s'exécute dans un environnement inconnu et sans apriori. Cet agent va être amené à exécuter des actions, lesquelles seront plus ou moins pertinentes dans le contexte présent. La pertinence des actions choisies est évaluée selon une fonction, caractérisant l'objectif que l'on souhaite atteindre.
Dans notre cas, notre fonction va s'intéresser à caractériser la probabilité de succès de la saisie d'un objet dans l'état actuel, en exécutant un mouvement donné.
Plus formellement, cette fonction est de la forme suivante :
Soit π une fonction qui, pour un ensemble d'états S, associe un ensemble d'actions A, nous renvoie
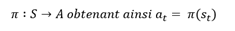
En l'état, notre agent ne sait pas déterminer si une action est meilleure qu'une autre. Pour cela, il lui est nécessaire d'avoir une fonction de gain.
Cette dernière est caractérisée de la façon suivante :
Soit R une fonction récompense, suivant l'état actuel, une action possible dans cet état, et l'état d'arrivée suivant cette action, nous pouvons retranscrire cela sous la forme :
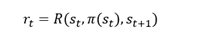
De fait, l'apprentissage par renforcement peut être schématisé de la manière suivante :
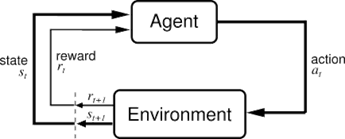
Figure 1 : Processus de décision d'un agent avec apprentissage par renforcement (source : Université d'Alberta)
Dans la Figure 1, ci-dessus, l'agent est dans un état st, et exécute une action at. Cette action a des conséquences dans l'environnement de l'agent, et pour lequel il reçoit une récompense rt, et change d'état, st+1.
La principale difficulté de ce genre d'algorithme est d'ordre combinatoire. En effet, dans la version simple, l'algorithme doit être capable de maintenir une table qui, pour un état donné, renvoie la meilleure action à prendre. Cependant, dans des contextes où l'état du robot est continu (dans le monde réel par exemple), la dimension de la table peut être infinie.
Un moyen d'arriver à contrebalancer ce phénomène est d'approximer la fonction de récompense au moyen d'un estimateur. En effet, des estimateurs, tels que les machines à vecteurs de support ou SVM (Support Vector Machine) ou les réseaux de neurones, permettent de modéliser des fonctions non linéaires et permettent ainsi de ne plus avoir à maintenir cette table. Il suffit alors simplement d'interroger l'estimateur pour récupérer la valeur de la récompense.
La génération des mouvements (Servoing)
La dernière brique nécessaire à la mise en œuvre du robot est la génération des actions possibles pour un état donné. Dans notre contexte, il s'agit de déterminer les mouvements que peut faire le robot, tout en essayant de se rapprocher au mieux de son objectif.
Cette étape, essentielle, peut paraitre simple pour un humain, mais le domaine d'étude est gigantesque pour un ordinateur. En effet, un mouvement dans un espace 3D est modélisé par un vecteur {x, y, z}, auquel nous pouvons rajouter une composante représentant la rotation de la pince fixée au bout du bras. Nous nous retrouvons donc avec un vecteur de 4 composantes {x, y, z, r}, dont les valeurs sont continues dans l'environnement du robot.
Les valeurs étant continues et non pas discrètes, les possibilités sont donc infinies ; ce qui, même pour un ordinateur puissant demeure encore infini. La recherche de la meilleure solution peut donc s'avérer très couteuse, en temps notamment, mais aussi potentiellement en espace.
Pour contourner ce problème, on cherche souvent à approcher cette solution optimale, laquelle pourra être trouver rapidement, et fournira des performances suffisantes. On parle alors d'optimisation numérique, et plus particulièrement du domaine des métaheuristiques.
Parmi les méthodes les plus courantes, nous pouvons ainsi mentionner :
- La recherche tabou : A partir d'une position donnée, l'exploration se fait dans le voisinage.
- Le recuit simulé : inspirée de la métallurgie, la température autorisant à un matériau de se déformer plus facilement permet à l'algorithme d'explorer plus ou moins un espace d'une fonction.
- Les algorithmes génétiques : Chromosomes générés de manière à favoriser les générations futures
- Les algorithmes de colonies de fourmis : Capacité des fourmis à déposer des phéromones sur leurs traces. Plus le chemin est court, plus de fourmis l'emprunte, plus forte est la quantité de phéromones sur ce chemin
Ces méthodes sont très souvent issues de phénomènes observés dans la nature, et très concrets. Elles permettent d'arriver à de bons résultats, pas forcément optimaux, mais s'en approchant, en un temps raisonnable. Elles sont par contre, sujettes à « l'enlisement » dans des minimas locaux, les empêchant, dans certains cas, de converger vers des minimas globaux.
En guise de conclusion pour cette introduction
Les 3 points développés ci-avant constituent la clé de voute du projet et de l'étude ainsi réalisée ; ces derniers permettant de mettre en œuvre le contrôle du robot.
L'algorithme d'optimisation numérique génère des mouvements, et évalue ces derniers au travers de l'estimateur. Cette estimation lui permet alors d'envoyer à KUKA la commande qui maximiser la probabilité de succès de la saisie, et ce, en temps réel et en coordination avec l'environnement de KUKA.
Comme vous pouvez vous en douter, tout cela suppose au-delà de la « beauté » de l'algorithmie et autres métaheuristiques à déployer, une réflexion préalable sur l'architecture à mettre en place.
Nous vous proposons donc de profiter du prochain billet pour un temps « rentrer dans la peau de l'architecte » afin d'aborder ensemble les considérations associées. Soyez rassuré(e)s ! les billets suivants nous donnerons à nouveau l'occasion de repasser dans celle du scientifique des données (data scientist) et ainsi de rentrer dans le vif du sujet de l'apprentissage par renforcement.
Dans l'intervalle, rendez-vous est donc pris pour le prochain épisode de la série de billets si la proposition vous agrée. Stay tuned! :-)