Performance Consideration for Disaggregated and Hyper-converged Configurations
There are two targeted deployment scenarios for Windows Server 2016 Storage Spaces Direct (S2D). Both cases provide storage for Hyper-V, specifically focusing on Hyper-V IaaS (Infrastructure as a Service) for Service Providers and Enterprises.
The disaggregated deployment scenario separate has the Hyper-V servers (compute node) in a separate cluster from the S2D servers (storage node). Virtual machines are configured to store their files on the Scale-Out File Server (SOFS) which is accessed through the network using the SMB3 protocol. This allows for scaling Hyper-V clusters (compute) and SOFS cluster (storage) independently.
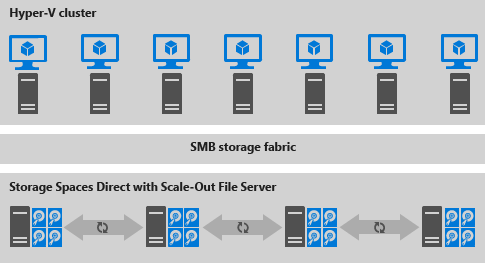
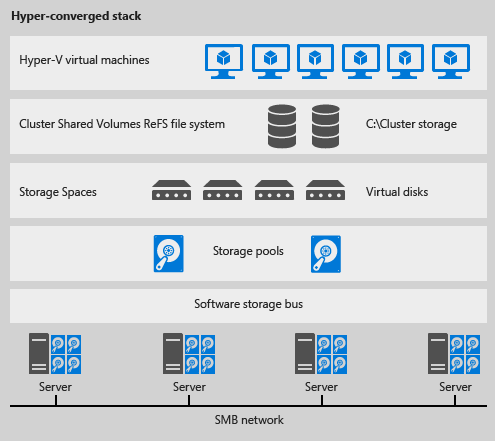
The hyper-converged deployment scenario has the Hyper-V (compute) and S2D (storage) components on the same cluster. Virtual machine's files are stored on the local CSVs and does not implement a SOFS. This allows for scaling Hyper-V compute clusters and storage together and removes requirement of configuring file server access and permissions. Once Storage Spaces Direct is configured and the CSV volumes are available, configuring and provisioning Hyper-V is the same process and uses the same tools that you would use with any other Hyper-V deployment on a failover cluster.
For more information regarding those two deployments, please refer to Storage Spaces Direct in Windows Server 2016 Technical Preview.
In Azure Stack Express (a.k.a, Azure Stack PoC), we chose disaggregated deployment although there is only one node. The main reason is from design point of view, disaggregated model is more flexible and the concept could be expanded to a large deployment. Of coz there would be some performance difference between those two deployment models. Disaggregated add one more layer (SMB Share on SOFS) and involve more network activities. In this blog, we will try answering the question what's performance trade off to select disaggregated instead of hyper-converged.
Test Environment:
Hardware:
- WOSS-H2-10 (DELL 730xd, E5-2630-v3 X2, 128GB Memory, 2TB SATA HDD X2 RAID1, 1 INTEL P3700 400GB NVMe drive, 1 Mellanox ConnectX-3 10Gb NIC + 1Gb NIC)
- WOSS-H2-12 (DELL 730xd, E5-2630-v3 X2, 128GB Memory, 2TB SATA HDD X2 RAID1, 1 INTEL P3700 800GB NVMe drive, 1 Mellanox ConnectX-3 10Gb NIC + 1Gb NIC)
- WOSS-H2-14 (DELL 730xd, E5-2630-v3 X2, 128GB Memory, 2TB SATA HDD X2 RAID1, 1 INTEL P3700 400GB NVMe drive, 1 Mellanox ConnectX-3 10Gb NIC + 1Gb NIC)
- WOSS-H2-16 (DELL 730xd, E5-2630-v3 X2, 128GB Memory, 2TB SATA HDD X2 RAID1, 1 INTEL P3700 400GB NVMe drive, 1 Mellanox ConnectX-3 10Gb NIC + 1Gb NIC)
The test environment is the same as the one in the previous two blogs.
- Build an All-Flash Share Nothing High Available Scale-Out Storage for Private Cloud
- The Power of RDMA in Storage Space Direct
Only difference is I have one more DELL 730xd server to play computer node role (Hyper-V server).
Software:
- Windows Server 2016 Technical Preview 4 Datacenter Edition
- 3 NVMe drives were in the same storage pool. The virtual disk on top of it was configured as two-way mirror, the column number is 1.
- Create a SOFS and a SMB Share on top of the above virtual disk.
- Create a high available VM role with a 60GB fixed VHD attached in the S2D Cluster.
- Export the above VM to the SMB Share and import it into WOSS-H2-16 Hyper-V management console.
Now I have two identical VMs. One is running on CSV volume directly. The other is running in a SMB file share.
Test Results:
I compared the Storage IO performance of VMs in Hyper-Converged deployment, SMB Direct disaggregated deployment and SMB disaggregated deployment.
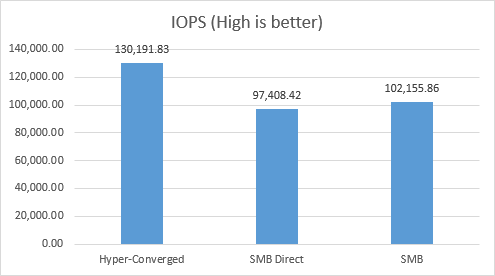
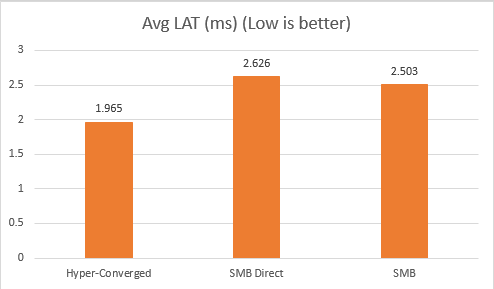
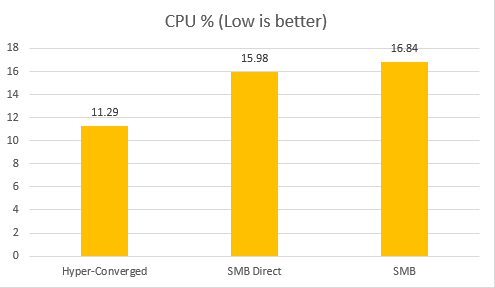
From the above diagram we could see compare to the Hyper-Converged deployment, Disaggregated deployment's IOPS drop around 25%. And latency increased around 33%. CPU usage increase 42%. Even in that case, from end to end the average latency is controlled very pretty good (around 2.6ms) meanwhile, it provides around 100,000 IOPS inside the single VM.
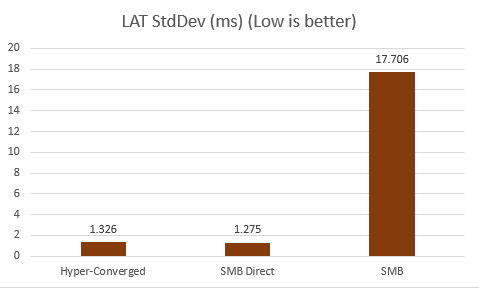
If we look at consistency of the performance, SMB Direct is outstanding. The standard deviation of latency and IOPS is lower or much lower than Hyper-Converged deployment.