ListItemRetriever: Accurately Retrieving Text of a Open XML WordprocessingML Paragraph
When you are retrieving the text of an Open XML WordprocessingML paragraph, it is often pretty important to retrieve the text of a list item. This was especially true for the WordprocessingML => XHtml transform. This post introduces the ListItemRetriever class, which implements one aspect of the functionality in HtmlConverter to retrieve the entire text of a paragraph accurately. ListItemRetriever is stand-alone – you can use it in a variety of contexts other than HtmlConverter.
This is one in a series of posts on transforming Open XML WordprocessingML to XHtml. You can find the complete list of posts here.
This blog is inactive.
New blog: EricWhite.com/blog
Blog TOCIt is important to understand exactly what a list item is. Numbered and bulleted lists are made up of two components – the list item, and the paragraph text:
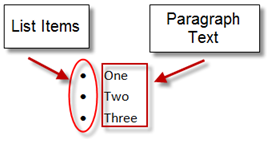
The same distinction applies to a numbered list:

The blog post, Working with Numbering in Open XML WordprocessingML, describes the markup for list items. That blog post has also been published as an MSDN article, which you can find here. The ListItemRetriever class implements the algorithms that are necessary to process the markup described in that post.
The use of ListItemRetriever is super simple. The class consists of one public static method with the following signature:
public static string RetrieveListItem(WordprocessingDocument wordDoc,
XElement paragraph, string bulletReplacementString)
To retrieve a string that contains the list item text, you pass an open WordprocessingML document, a LINQ to XML XElement object, and an optional bullet replacement string. Following is an example that shows the use of ListItemRetriever.RetrieveListItem:
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Xml.Linq;
using OpenXmlPowerTools;
using DocumentFormat.OpenXml.Packaging;
class Program
{
static void OutputBlockLevelContent(WordprocessingDocument wordDoc,
XElement blockLevelContentContainer)
{
foreach (XElement blockLevelContentElement in
blockLevelContentContainer.LogicalChildrenContent())
{
if (blockLevelContentElement.Name == W.p)
{
string listItem = ListItemRetriever.RetrieveListItem(
wordDoc, blockLevelContentElement, "-");
string text = blockLevelContentElement
.LogicalChildrenContent(W.r)
.LogicalChildrenContent(W.t)
.Select(t => (string)t)
.StringConcatenate();
Console.WriteLine("Paragraph text >{0}<", listItem + text);
continue;
}
// If element is not a paragraph, it must be a table.
Console.WriteLine();
Console.WriteLine("Table");
Console.WriteLine("=====");
foreach (var row in blockLevelContentElement.LogicalChildrenContent())
{
Console.WriteLine();
Console.WriteLine("Row");
Console.WriteLine("===");
foreach (var cell in row.LogicalChildrenContent())
{
Console.WriteLine();
Console.WriteLine("Cell");
Console.WriteLine("====");
// Cells are a block-level content container, so can call this
// method recursively.
OutputBlockLevelContent(wordDoc, cell);
Console.WriteLine();
}
}
}
}
static void Main(string[] args)
{
byte[] byteArray = File.ReadAllBytes("Test.docx");
using (MemoryStream memoryStream = new MemoryStream())
{
memoryStream.Write(byteArray, 0, byteArray.Length);
using (WordprocessingDocument wordDoc =
WordprocessingDocument.Open(memoryStream, true))
{
RevisionAccepter.AcceptRevisions(wordDoc);
XElement root = wordDoc.MainDocumentPart.GetXDocument().Root;
XElement body = root.LogicalChildrenContent().First();
OutputBlockLevelContent(wordDoc, body);
}
}
}
}
The following document contains a number of paragraphs that are part of numbered or bulleted lists. It includes a table with one row and two cells:

When you run the example program for this document, you see:
Paragraph text >First. This is a test.<
Paragraph text >Second. This is another paragraph.<
Paragraph text >Third. Third paragraph is here.<
Paragraph text ><
Paragraph text >I. This list has roman numerals.<
Paragraph text >II. Et tu, Bruté?<
Paragraph text >III. This is a third paragraph.<
Paragraph text >IV. This is a fourth paragraph.<
Paragraph text >V. This is a fifth paragraph.<
Paragraph text ><
Table
=====
Row
===
Cell
====
Paragraph text >1st. This is a numbered list in a cell.<
Paragraph text >2nd. Another item.<
Paragraph text >3rd. A third item.<
Cell
====
Paragraph text >- Here is a bulleted list.<
Paragraph text >- Another item.<
Paragraph text ><
In this example, the OutputBlockLevelContent method needs to be recursive, as table cells can contain other tables.
In this example, I passed a hyphen (-) to the bulletReplacementString argument of ListItemRetriever.RetrieveListItem, so that it is easy to print the string. Alternatively, you can pass null for the bulletReplacementString argument, in which case the returned string contains the Unicode characters for bullets. There are a number of bullets that you can use for a bulleted list.
The ListItemRetriever depends on the document containing no tracked revisions. This example uses the approach of reading a document into a byte array, then creating a resizable memory stream from the byte array, and then opening the WordprocessingML document from the memory stream. Using this approach, the example is free to accept revisions, and subsequently process the document without affecting the document stored on disk. I introduced this approach in Simplifying Open XML WordprocessingML Queries by First Accepting Revisions.
This example uses the LogicalChildrenContent axis method, which I introduced in Mastering Text in Open XML Word-Processing Documents. By first accepting revisions, and by using the LogicalChildrenContent axes, this example will return the correct text regardless of whether the source document contains revisions, content controls, smart tags, or any of the other interesting artifacts of WordprocessingML that can make processing WordprocessingML content more challenging.
ListItemRetriever class is part of the PowerTools for Open XML project. You can find ListItemRetriever.cs in the HtmlConverter.zip download, under the 'Downloads' tab at PowerTools for Open XML.
PowerTools for Open XML also includes the PtOpenXmlUtil.cs module, which includes the LogicalChildrenContent axis methods.
This example uses the StringConcatenate extension method. The module PtUtil.cs in the PowerTools for Open XML project contains a number of my favorite functional programming extension methods, including StringConcatenate.