SQL Server 2016 new features to deal with the new CE
It is no news that SQL Server 2014 changed the Cardinality Estimator (CE).
Ok. Even if it is not something new: What means CE? What is the impact of the new CE? And most important what SQL server 2016 propose to deal with it?
The idea of this post is to answer those kind questions and give even more reasons to migrate for SQL Server 2016.
So, first things first. What is CE (Cardinality Estimator)?
Defined by the Microsoft white paper - Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator: “At a basic level, cardinality estimates are row count estimates calculated for each operator within a query execution plan. In addition to row count estimation, the cardinality estimator component is also responsible for providing information on:
- The distribution of values.
- Distinct value counts.
- Duplicate counts as input for parent operator estimation calculations.
Estimates are calculated using input from statistics associated with objects referenced in the query. Statistics objects used for estimation can be associated with an index or they can exist independently. You can create statistics objects manually or the query optimization process can generate them automatically. A statistics object has three main areas of information associated with it: the header, density vector, and histogram.“
Summarizing: It is basically SQL Server statistic predictions, which SQL optimizer uses during the compilation of the query execution plan. So, suppose you execute a query to obtain as result set of 100 rows, SQL Server knows that you want to filter or not a query in a way that is expected to return 100 rows, based on the statistic information for that table, SQL Server optimizer will use the right operator in the execution plan for that result set. Without change the logic of the query, SQL Server could use a different operator if the result set expected is for instance, 1.000 rows.
For that definition, you probably noticed that accurate statistic is quite important for SQL Optimizer create an accurate execution plan.
New CE?
The new CE is available since SQL Server 2014, and it changes the calculation for distribution of data against different columns, for example, it assumes there is a correlation between the columns. The old CE (since SQL Server 7.0 until SQL Server 2012) assumes the distribution of the data across different column are uncorrelated.
What is the impact?
Some queries have better performance with the old CE. Other may execute faster using the new CE, which address a lot of fixing from the old CE.
What SQL server 2016 propose different from 2014 to deal with the new and the old CE?
Ok, so consider a scenario of a mixed workload with some queries that present a better performance using the old CE and others that present a better performance with the new CE.
What are the options?
SQL Server 2014:
- Trace Flag 9481 reverts query compilation and execution to the pre-SQL Server 2014 legacy CE behavior for a specific statement.
- Trace Flag 2312 enables the new SQL Server 2014 CE for a specific query compilation and execution.
At the query level, you could use the hint QUERYTRACEON. The hint takes precedence over server and session-level enabled trace flags. Server and session-level trace flags take precedence over database compatibility level configuration and context.
SQL Server 2016:
Documented at: https://msdn.microsoft.com/en-us/library/ms181714.aspx
SQL Server 2016 provides another Option available since SP1:
USE HINT ( ' hint_name ' ) Provides one or more additional hints to the query processor as specified by a hint name inside single quotation marks.
Under this option there are a lot of possible hints, regards to the old\new CE, the option is: 'FORCE_LEGACY_CARDINALITY_ESTIMATION' : it forces the query optimizer to use Cardinality Estimation model of SQL Server 2012 and earlier versions. This is equivalent to trace flag 9481 or Database Scoped Configuration setting LEGACY_CARDINALITY_ESTIMATION=ON.
Example – AdventureWorks:
[sql]
SELECT [AddressID],
[AddressLine1],
[AddressLine2]
FROM Person.[Address]
WHERE [StateProvinceID] = 9 AND
[City] = 'Burbank'
OPTION (USE HINT ( 'FORCE_LEGACY_CARDINALITY_ESTIMATION' ))
[/sql]
Figure 1 shows the execution plan, note estimated and actual number of rows (the stats was already update for this table).
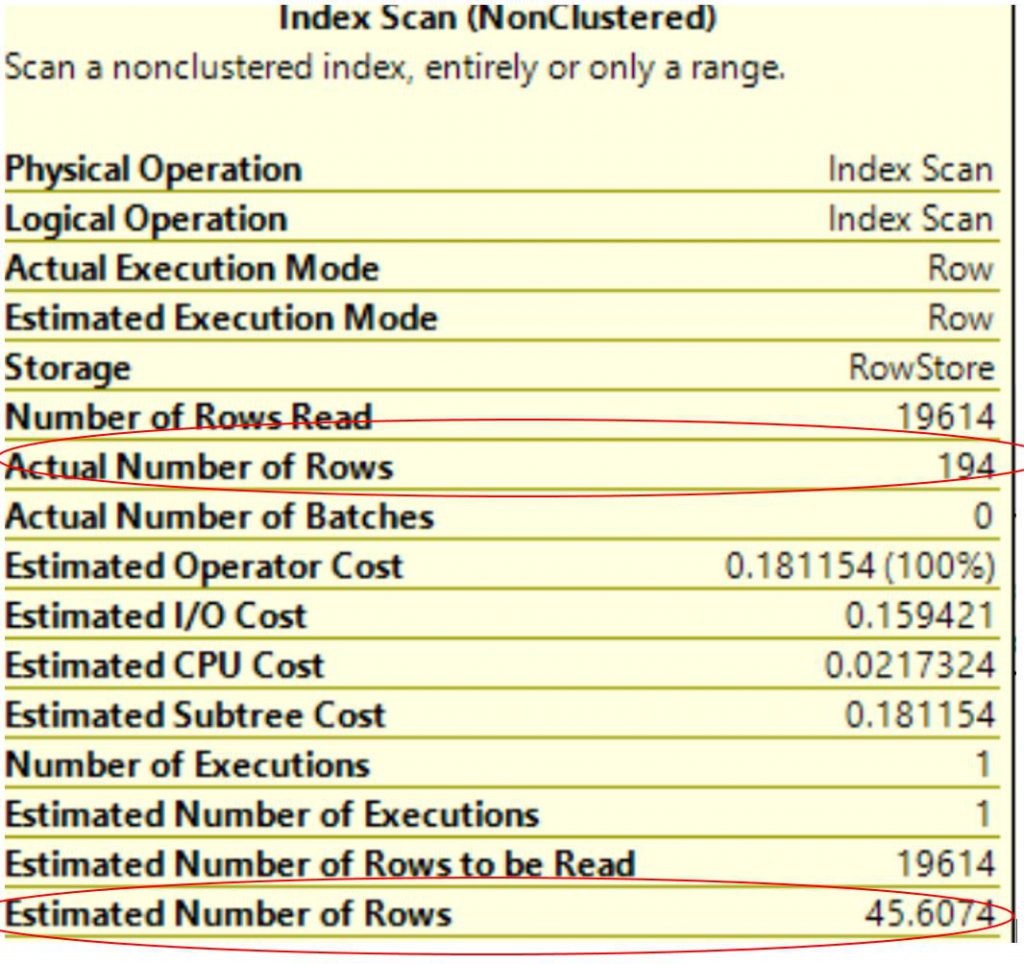
Figure 1: Execution Plan Hint
If the same query is executed once more without the hint, it will use the actual CE because it was executed against a SQL Server 2016 – SP1.
[sql]
SELECT [AddressID],
[AddressLine1],
[AddressLine2]
FROM Person.[Address]
WHERE [StateProvinceID] = 9 AND
[City] = 'Burbank'
[/sql]
Figure 2 shows the execution plan:
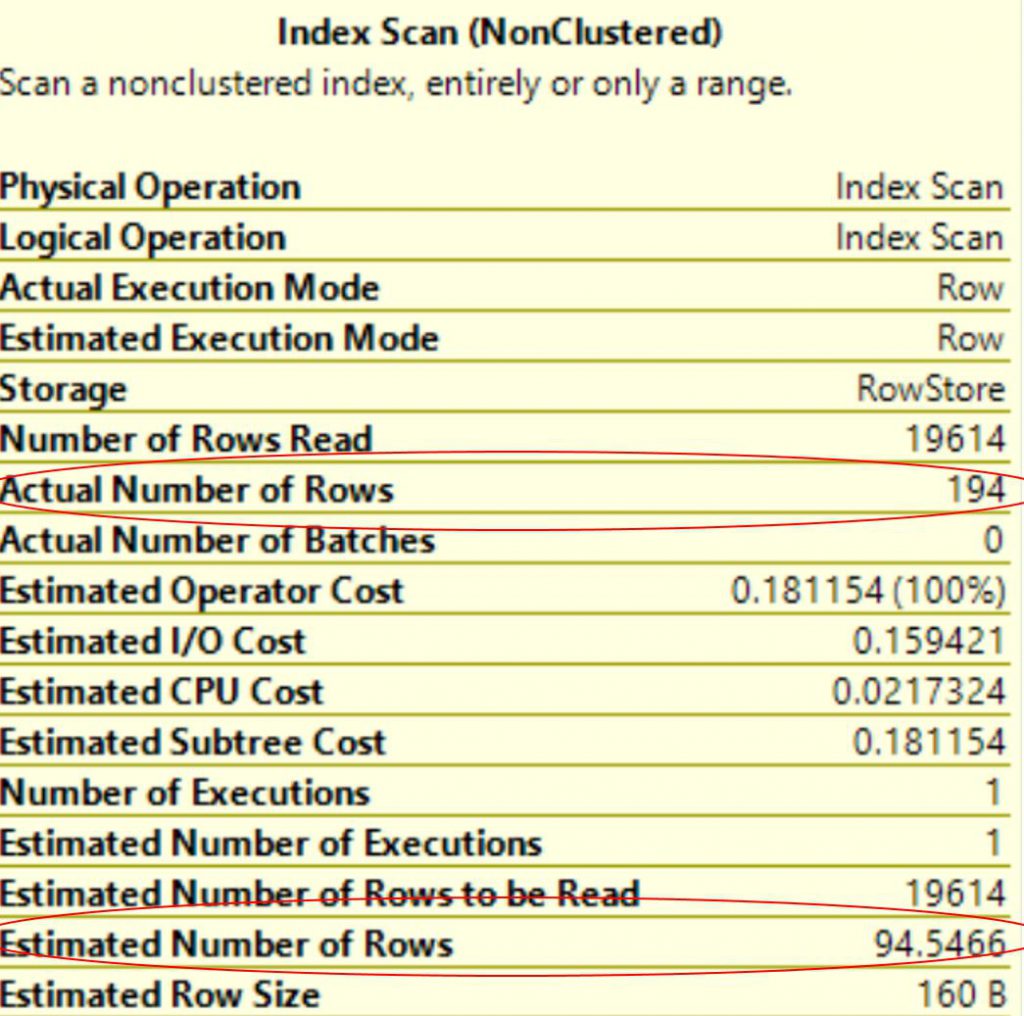
Figure 2: execution plan without the hint – SQL 2016 SP1
The estimated number of rows and the actual number of rows are still different, but comparing to the old CE the new CE for this query has a much more precise prediction that the old CE had.
- But if the entire database performs better using the old CE not the new. Should I use the hint in every single query or is there another option? The answer is: SQL Server 2016 provides a better option.
SQL Server 2014:
The option was change the compatibility level of the database, what has the obvious drawback of: you will not be able to use SQL Server 2014 new features.
[sql]
ALTER DATABASE [AdventureWorks2012] SET COMPATIBILITY_LEVEL = 110;
GO
[/sql]
SQL Server 2016: Database Scope.
Documented at: https://msdn.microsoft.com/en-us/library/mt629158.aspx
Database Scope enables several database configuration settings at the individual database level. This statement is available in both Azure SQL Database V12 and in SQL Server 2016.
Possible settings:
- Clear procedure cache.
- Set the MAXDOP parameter to an arbitrary value (1,2, ...) for the primary database based on what works best for that particular database and set a different value (e.g. 0) for all secondary database used (e.g. for reporting queries).
- Set the query optimizer cardinality estimation model independent of the database to compatibility level. -> (The one that we are interested)
- Enable or disable parameter sniffing at the database level.
- Enable or disable query optimization hotfixes at the database level.
So, that means (what you are probably thinking right now): Yes, you could have a database using the compatibility level of SQL Server 2016, 130, and the old CE at the same time.
And it is quite simple:
[sql] ALTER DATABASE SCOPED CONFIGURATION SET  LEGACY_CARDINALITY_ESTIMATION=ON; [/sql]
Once you execute that, every query running in this database will start to use the old CE.
You could be thinking, but what about the queries that already exist in my cache? Database scope will clear the procedure cache in the current database, which means that all queries will have to be recompiled.
Other options of Database Scope:
MAXDOP: basically, you can define a degree of parallelism for that database. That setting even overrides whatever you had in you sp_configure (unless the scope is 0).
QUERY_OPTIMIZER_HOTFIXES: You can disable the SQL Optimizer fix under the traceflag 4199.
Parameter sniffing: You could disable parameter sniffing behaviour. Parameter sniffing refers to the fact of SQL Server instead of compiling each query (as long as is using parameters), it tries to reuse the same plan for similar queries. This setting is the same as the traceflag 4136.
FOR SECONDARY In case of Always On or Geo replication, you could specify some settings for the secondary databases (all secondary databases must have the identical values).
For example:
[sql] ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET MAXDOP=4 [/sql]
Note: Consider a scenario of a query executed with an inner join between two tables referenced two different databases, one database is using the old CE and the other is using the new CE.
The CE used for the query will be the one from the current database context.
Example:
Adventureworks2008: Old CE
AdventureWorks: New CE
Query:
[sql]
SET STATISTICS XML ON;
SELECT a.[AddressID],
a.[AddressLine1],
a.[AddressLine2]
FROM [AdventureWorks].Person.[Address] a
INNER JOIN (
SELECT [AddressID],
[AddressLine1],
[AddressLine2]
FROM [AdventureWorks2008].Person.[Address]
WHERE [StateProvinceID] = 9 AND
[City] = 'Burbank') tab
on tab.[AddressID] = a.[AddressID]
WHERE a.[StateProvinceID] = 9 AND
a.[City] = 'Burbank'
SET STATISTICS XML OFF;
[/sql]
Executed from AdventureWorks:

Executed from Adventureworks2008: 
And that is all folks! 😉
Liliam Leme
SQL UK PFE
Comments
- Anonymous
May 09, 2017
Nice! - Anonymous
October 08, 2017
Very interesting thoughts. Thank you.