HDInsight: - Creating, Deploying and Executing Pig UDF
During my developer experience, I always look for how customization (write my own processing) can be done if functionality is not available in programming language. That thought was triggered again when I was working on Apache Pig in HDInsight. So I started researching it and thought it would be good to share.
In this article I take a basic example (which might be doable with pig scripts alone) to focus on creating, deploying and executing Pig UDF.
Scenario
In this article, we'll see how we can evaluate an employee's performance based on the sales they made for given years. Along with that we'll also calculate the commission based on certain condition. If an employee achieves the target then they were allowed for 8% commission else no commission. We will have employee's sales record stores on blob storage.
Step 1:- Creating a Pig UDF
Pig UDF can be implemented through Java, Python, and JavaScript. We will use Java platform to build UDF. We'll be using eclipse to write java program.
Open eclipse, Click on File -> New -> Java Project

Provide a suitable Project Name such as "Commission" and click on Finish.

Right click on Project Name -> Select New -> Package

Provide Java Package Name such as salescommission 
Right click on package -> Click New -> Click on Class

Provide a Class Name such as calculatecommission and click on Finish

The next step is to add logic in class, which you can see below. The same code can be copied from here.

Before we compile this code we need to add reference of Pig jar file for the reason of using some classes in code. One thing you need to be sure of is to add correct reference. I recommend to have the jar file targeting the Pig version that you will be utilizing in Hadoop.
In HDInsight, we have pig 0.11 version available so I copied pig-0.11.0.1.3.7.1-01293.jar from "C:\apps\dist\pig-0.11.0.1.3.7.1-01293" after logging onto an RDP session on the head node. The version number will vary based on the version of HDInsight or Hadoop that you have deployed. You can also download from Apache website as well. If versions are mismatched we might get errors.
Copy that .jar locally to a folder, and reference that. We have to add the reference in the eclipse solution and here how we can do it.

Right click on the project, and select Build Path > "Add External Archives… " and select the location where you have copied pig-0.11.0.1.3.7.1-01293.jar on your local hard drive.
The next step is to generate jar. Right click on Project and click Export 
Select JAR file and click Next

Select the package and then select calculationcommission.java.
Provide an export destination path and click Next. 
Use the default settings on the Packaging Options page and click Next 
Step 2:- Deploying a Pig UDF
Once the .jar file is compiled and generated locally, copy the .jar file onto Microsoft Azure Blob storage. Details of how to copy files into Microsoft Azure Blob storage can be find here.
As this stage, you may want to copy the data file as well so we can later try it out. I have uploaded a sample data text file here.
In the next step we'll register the jar file and use the function we created.
Step 3:- Executing a Pig UDF
Before executing the Pig UDF, first register it. This is required because Pig should know which JAR file to load via classloader. You will get error if you try to use a function from a class without registering it. When PIG is running in distributed mode then it sends the JAR files to the cluster. Below is the screenshot of PowerShell and outcome. I have copied the sample PowerShell here.

Instead of seeing the result on screen, I stored the result in a file by changing DUMP B command from above to STORE B INTO 'LOCATION_NAME' .
For example you can add this line into the Pig Latin on the $QueryString variable in powershell by using the + sign to concatenate the string.
"STORE B INTO 'wasb://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/user/pigsampleudf/output/';"
The output will go into a folder named output, and the file will be named part-m-00000 for example.
Step 4:- Analyzing output in Excel 2013
Once the output is stored on Microsoft Azure Blob storage, you can open it in Power Query.
First Open Microsoft Excel 2013 and Click on the Power Query ribbon.
Next choose to import data From Other Sources then choose From Windows Azure HDInsight 
Provide the Microsoft Azure Blob storage name. This is the storage account name as you would see on your storage page in the Azure portal. All your containers in that account will be shown.

Once connected, select the container where output is stored.

One connected, you will find many files in blob storage so one of the ways is to sort on Date modified column.

Once you select the output file from our Pig script, let's see how the result is displayed. If you notice year, name, sales and commission are in one merged column. So the next step is to split that into different columns for the fields.

Right click on Column1 and select Split Column and click on By Delimiter. Choose Tab as a delimiter.

Once the split is done, below is the outcome and notice all fields are displaying perfectly. Change the column name as well for better understanding the fields.
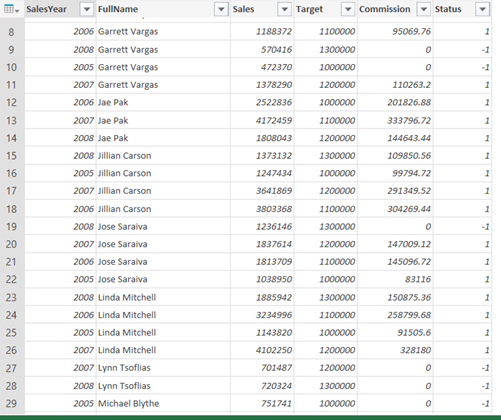
Once it's imported, I have add conditional formatting on Status and then did sort on FullName column. Now I can analyze the employee performance year by year for example if you look for employee "Amy Albert" not able to meet target (Status column shows -1 values) and if you look for employee "Jillian Carson" is able to meet the target all years (Status column shows 1 values).

At last
- Check out piggybank jar file, since it might have canned features you were looking for.
- If computation takes more memory then specified, it will spill to disk (which will be expensive). Use bag data type in such cases as pig will manage it. It knows how to spill.
Thanks Jason for reviewing this post.
Thanks and Happy learning.
Sudhir Rawat