Encoding 101 - Exporting from SQL Server into flat files, to create a Hive external table
Today in Microsoft Big Data Support we faced the issue of how to correctly move Unicode data from SQL Server into Hive via flat text files. The main issue faced was encoding special Unicode characters from the source database, such as the degree sign (Unicode 00B0) and other complex Unicode characters outside of A-Z 0-9.
The goal was to get Hive to read those same strings SQL Server had saved out to text files and represent them equally to the Hive consumer. We could have used Sqoop if there was a connection between Hadoop and the SQL Server, but that was not possible, as this was across company boundaries and shipping files was the easier approach.
It was tricky to do, but we found a couple of solutions. When the Unicode string value is exported from Microsoft SQL Server via SSIS or the Import Export wizard, they look fine to the naked eye, but SELECT * FROM HiveTable; and the data looks different.
Microsoft SQL Server: zyx°°° Looks good
Hive: zyx ��� Uh-oh! We've got trouble.
That Unicode string (NVARCHAR) value in SQL appears as zyx°°° We Export that data to a flat file using SSIS or the Import Export Wizard, then copy the files into Azure Blob Storage. Next using Azure HDInsight, when a Hive table is created atop those files, then the same characters look garbled black question marked - zyx��� as if the characters are unknown to Hive's interpretation.
Linux and Hive default to text files encoded to UTF-8 format. That differs from the SSIS Flat File Destination's Unicode output.
I found two ways we found to make them compatible.
- Change the export options in SQL Server SSIS Flat File Destination to uncheck the "Unicode" checkmark and select code page 65001 (UTF-8) instead.
- Keep the Unicode encoding as is in SSIS, but tell Hive to interpret the data differently using serdeproperties ('serialization.encoding'='ISO-8859-1');
Time for a little trial and error
1. Setup an example Database
These are the steps I used to see the issue. You can use SQL Server (any version from 2005-2016).
Using SQL Management Studio, I create a database TestHive and table T1 in SQL Server. Insert some data into the NVarchar column, including some special characters. NChar and NVarChar and NVarChar(max) are the double-byte Unicode data type in SQL Server columns, that are used for global language support.
| CREATE DATABASE TestHive GO USE TestHive GO CREATE TABLE T1(Col1 Int, Col2 NVarchar(255)); GO INSERT INTO T1 VALUES (1,N'abcdef'), (2,N'zyx°°°'), (3,N'123456' ) GO SELECT * FROM T1 |
2. Run the SQL Server Import Export Wizard from the Start menu to copy the rows into a text file.
On the Source – point to your SQL Server instance, and select the database and table you want to pull from.
On the Destination – choose Flat File Destination, point to a file path on the local disk, and Select the Unicode checkbox on the locale. 
You could use the same Flat File Destination from within an Integration Services (SSIS) package design and run that if you prefer more control on how the data is transformed in the Data Flow Task, but the Import Export Wizard does the simple copy that we need here.
This is the output – so far looks good.

3. Connect to my Azure HDInsight cluster in the cloud to upload the file.
I used a Linux based HDInsight Hadoop cluster, so I will use SSH to connect to the head node.
Then I create a directory, and upload the first file into that location in blob store. This is much like saving the file from the local disk into HDFS for the purposes of Hadoop outside of Azure.
hadoop fs -mkdir -p /tutorials/usehive/import1/
hadoop fs -copyFromLocal tableexport_ssisunicode.txt wasb:///tutorials/usehive/import1/tableexport_ssisunicode.txt
You could also upload the files directly to Azure Blob Storage from tools such as Visual Studio Azure VS 2015 / VS 2013 or Microsoft Azure Storage Explorer / Azure Storage Explorer or Cloud Explorer for Visual Studio 2013
4. Run Hive to read that first folder
Now that the text file is ready in Blob storage, I can run Hive and create a table, and query from that file saved into the import1 folder. From my SSH session I simply run hive.
cd /bin
hive
{
DROP TABLE Import1;
CREATE EXTERNAL TABLE Import1(col1 string, col2 string) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/tutorials/usehive/import1/' tblproperties ("skip.header.line.count"="1");
SELECT * FROM Import1;
}
Notice the strange characters ��� where I expected my degree signs. 
Just to be sure it's not something special with my SSH client (MobaXTerm here) I am trying from the Ambari web dashboard for my Azure HDInsight Cluster, and using the Hive View from the menu icon in the upper right. 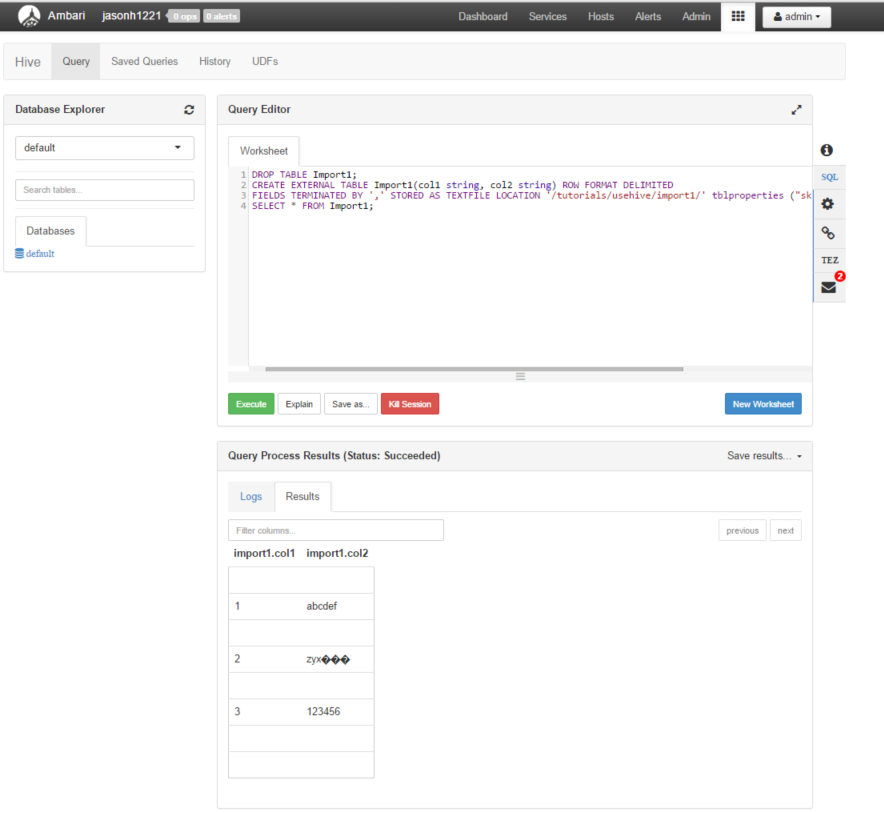
5. OK let's try exporting again – this time changing the flat file encoding setting.
In the SSIS Import Export Wizard (SSIS Flat File Destination) choose code page UTF-8.
- Uncheck the "Unicode" checkmark.
- Choose code page 65001 (UTF-8) 
6. Upload that second file to Linux (SFTP) and then copy into HDFS or Azure Blob Storage.
I made a new folder, so I could compare my trials side-by-side.
hadoop fs -mkdir -p /tutorials/usehive/import2/
hadoop fs -copyFromLocal tableexport_ssisunicode2.txt wasb:///tutorials/usehive/import2/tableexport_ssisunicode2.txt
7. Now test the Hive table again with the UTF-8 encoded file in the second folder
Run Hive
cd /bin
hive
{
DROP TABLE Import2;
CREATE EXTERNAL TABLE Import2(col1 string, col2 string) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/tutorials/usehive/import2/' tblproperties ("skip.header.line.count"="1");
SELECT * FROM Import2;
QUIT;
}
My zyx°°° looks normal now! Success! 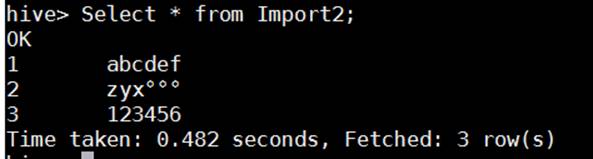
The Hive View in Ambari likes this data too. 
8. An alternative- Tell hive to encode / decode the external files differently
Perhaps you don't want to change the file format to UTF-8 (most universal in Linux and Hadoop), or maybe you cannot change the format at all, because the files come from an outsider.
Starting in Hive 0.14 version and above, Hive has a simple way to change the encoding of serialization (for interpreting the bytes encoding in text files for example).
The change was explained here https://issues.apache.org/jira/browse/HIVE-7142
1. You can Create from scratch with this code page serializer and override the serialization.encoding property to a code page that best matches your source data encoding.
CREATE TABLE person(id INT, name STRING, desc STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES("serialization.encoding"='ISO-8859-1');
2. Or if you have an existing table, this can be adjusted after the fact. You need to carefully match your encoding to whatever kind of files will be presented in the storage underneath this Hive table.
Choose one, or make your own…
ALTER TABLE Import1 SET serdeproperties ('serialization.encoding'='US-ASCII');
ALTER TABLE Import1 SET serdeproperties ('serialization.encoding'='ISO-8859-1');
ALTER TABLE Import1 SET serdeproperties ('serialization.encoding'='UTF-8');
To find out which tokens to list next to the equal sign, refer to the Charset code ID is listed in Java documentation
https://docs.oracle.com/javase/7/docs/api/java/nio/charset/Charset.html
I am guessing the right one is this one to match SQL's "Unicode" but it needs to be tested further to be totally sure that ALL characters are interpreted as expected.
| ISO-8859-1 | ISO Latin Alphabet No. 1, a.k.a. ISO-LATIN-1 |
Other tips we didn't have time to try yet:
Someone made a tool to help convert files if it is not possible for them to change the format in SSIS or BCP exports to text files. https://code.msdn.microsoft.com/windowsdesktop/UTF8WithoutBOM-Converter-7a8218af
Hope this helps someone out there. Let us know if it does, or if you still get stuck, post a comment below, or try the Azure forums for help.