Offline Schema Development
Continuing with the Best Practices post series, let's take a look at Offline Schema Development to set the stage for future topics. This posting is for DBAs and Database Application Developers that are not using the VSTSDB or have just started using VSTSDB. For those that are already using VSTSDB to manage their database development there also may be something in here for you as well.
Historically, database development follows a different process than other software development processes in many organizations. For example, when most of you have developed a database you make changes directly to a live development database and (hopefully) capture those changes either in script or in a document for later reference; the website that uses the database is iterated on by the ASP.NET developers with the source being checked into some source code control system. Once the website is ready to move to a QA environment it is built and xcopy deployed to the QA environment. The database changes must also be migrated so the DBA or developer uses the script they incrementally created or creates the change script based on the changes defined in their change document and begins stepping through all the changes to update the QA environment's database. The development and xcopy deployment of the website application are in sharp contrast to the manual approach taken to update the database.
The differences in development and deployment techniques between application and database development is largely attributed to the existence of data and operational state that inherently resides in all live databases. The operational state includes configuration of the database, database schema, security settings, permissions and data. To change the operational state of the database, some knowledge of the existing state is required and the change is often additive in nature. The existence of data complicates the database change process because the data is often migrated, transformed, or reloaded when changes are introduced by application development efforts that affect the shape of the database's tables. Throughout this change process, production quality data and operational state must be protected against changes that may jeopardize its integrity, value, and usefulness to the organization.
Given the constraints that data introduces, the need to manage database state in general, and specific tools required to effect database change, organizations often struggle with integrating database development processes into their larger Application Lifecycle Management (ALM) strategies. This has given rise to segmented and often fragmented application development workflow processes which ultimately reduce the organization's collaboration, efficiency and agility.
These fragmented processes typically originate in the area of Software Configuration Management (SCM). If you compare database development and application development SCM practices, the key difference is the existence of state that must be managed for databases. To manage this state, change scripts must be developed that not only identify the desired schema and state of the database, but also any modifications and transformations necessary to move the database (and its data) from the existing state to the new state at deployment or release. Conversely, for application development in general, there is usually not a significant amount of existing state and the application is often simply replaced with the new version at the time of release.
Visual Studio Team System 2008 Database Edition (VSTSDB) provides tools necessary to effectively manage database change in a manner which easily integrates into their organization's existing SCM processes. VSTSDB provides a disconnected, declarative database development environment based on a model representation of the database where the source code defines the database, options, and schema. T-SQL script (source code) in VSTSDB projects is the primary artifact and is managed and versioned throughout the development cycle in the same respect as artifacts for other Visual Studio Projects. This is Offline Schema Development and enables a repeatable, flexible, process driven Database Development Life Cycle (DDLC) process.
Adoption of VSTSDB may require a mental shift (old habits are hard to break) for some developers or at least a change in process or workflows. Developers who have developed database applications where the production database represents the current version of the database will need to adopt a source code based approach where source code becomes the vehicle to which change is made to databases. In VSTSDB, the project and the source code is the "One Version of the Truth" for the database schema and is managed using SCM workflows likely already being used by the developer or organization for other portions of their application stack. For the data, the production database remains its "One Version of the Truth" as it should be.
Offline schema development is an approach to database development that focuses on creating and maintaining the database using source code in an environment that is disconnected from an actual database. The source code is developed without defining the implementation details of modifying an existing database. Instead, the schema is declared in source code and the source code is versioned throughout the development lifecycle. The database schema is modeled in the project system and includes the data object structures like tables and views as well as programmability objects such as stored procedures and functions.
Side Note: VSTSDB comprehends almost all objects and syntax. Very few objects and syntax only meaningful to the database engine at runtime have been excluded.
VSTSDB enables an Offline Schema Development environment by providing:
- A database project (.dbproj) designed to manage database development;
- Declarative T-SQL syntax support where the schema is defined in the domain language of the database;
- Schema model representation of the database schema where source can be round tripped from source to model and back again;
- Schema model interfaces providing programmatic interaction to database tooling and designers;
- Interpretation and validation of T-SQL syntax and schema dependencies ensuring integrity of the source without executing it against a database;
- Schema comparison which compares your source with a target database to generate an update script;
- Compiled versions of database schema enabling deferred deployment and script generation(.dbschema file);
- .dbschema files can be deployed to different environments with different configurations.
Ok, so enough with the big words and fancy bullets... Let's walk through a scenario that will hopefully demonstrate the points above. In this scenario we will track a multitier application over 3 development iterations/release cycles without using VSTSDB. In this scenario, a simple class represents the application tier and a table represents the data tier.
- In version 1 the application developer (APPDEV) defines a simple class called Customer. The database developer (DBDEV) defines a simple table called Customer. Life is good.
- In version 2, the team has realized that they will very likely have more than one customer named Tom Smith (Hey Tom! ;) ) and decide that a means to uniquely identify a customer would be a valuable addition. The APPDEV adds an Id member to their class. The DBDEV adds Id column and primary key to the table. This is where things start getting interesting. While the APPDEV can simply update their class and check it in, the DBDEV must write alter statements to add the new column and primary key. The DBDEVs code no longer represents the true shape of the Customer table. The true shape of the Customer table exists in the current development DB and is possibly spread over two scripts: Some in the original table create script and some in the database update script. The diligent DBDEV makes the changes checks the new file in. Side Note: For simplicity reasons in this scenario we will disregard data motion required to push the change out to the database. That's another post. ;)
- By the time we hit version 3, business is good and management has rewarded the team with new dev boxes, lcds and shiny new tools. The team needs to differentiate their customers and decides to add a property to their customers to identify the customers they want to keep and expand business with. To implement this the APPDEV adds a new member to their class called IsKeyCustomer and checks in. The DBDEV adds another file and writes another alter statement to add the new column to the Customer table. The DBDEV updates the development database and the change script and checks in.
At the end of version 3 we end up with project artifacts that look similar to the following:
Customer.cs
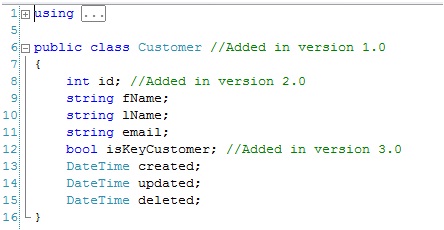
Customer.table.sql

Take a look at the change script. The change script are all the changes together in one SQL file. Change scripts typically validate an expected schema condition before each change. You will often need data motion scripts before some changes can be completed on tables with eisting data.

There are a number of problems with maintaining a schema change script: It's a manual and time consuming; error prone; complexity increases as time goes on and number of version changes grow; development team agility increases the maintenance cost of change script; it's really not a scalable process. Moreover, you must insatiate your database schema by running the full set of scripts against a live database to view or reference your objects. This introduces a dependency on the development database as the "truth" of the databases schema instead of the source code. This also requires making changes twice, once in the dev db and again in the change script.
Now let's go through the same scenario using VSTSDB. There are no changes in behavior for the APPDEV so I will only call out the actions of the DBDEV.
- In version 1 the DBDEV defines a simple table called Customer2.
- In version 2 the DBDEV adds the Id column and primary key to the Customer Table definition. Life is grand!
- In version 3 the DBDEV adds the IsKeyCustomer column to the Customer table definition and openly mocks the APPDEV while checking in the change. ;)
At the end of version 3 we end up with database source that looks similar to the following:
Customer.table.sql

The DBDEV defines the shape of the object for the version of the application, not how to mutate the existing object in the database engine to the desired shape. You are probably thinking: yeah, right! That will never deploy! This is where the deployment engine comes in to play. As mentioned previously, the deployment engine will take the compiled version of your schema and compare it against a database deployment target. The differencing engine will produce the necessary DDL scripts to update the target schema to match the version you are deploying from the project. Let's look at the example update scripts below using our previous scenario.
When deploying to an empty database the deployment engine will produce the full script below (excerpt provided).
![]()
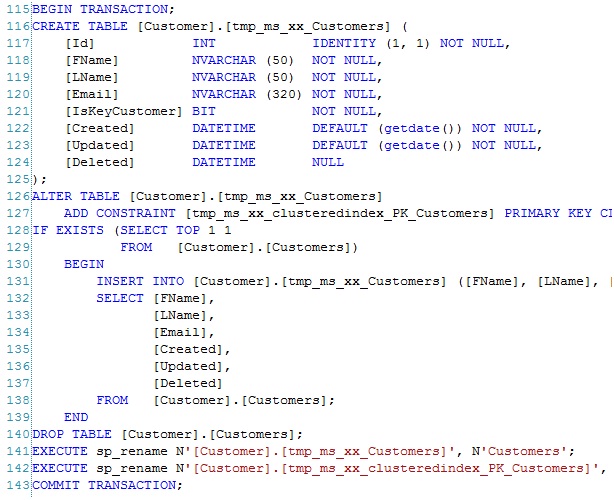
When deploying to an existing version of the database, let's say a production environment running version 1.0, it will produce the update script below.
You can deploy your project's schema to multiple databases with different schema versions to integrate the schema defined in your project. This is extremely powerful. The graphic below depicts what happens at the time of deployment.
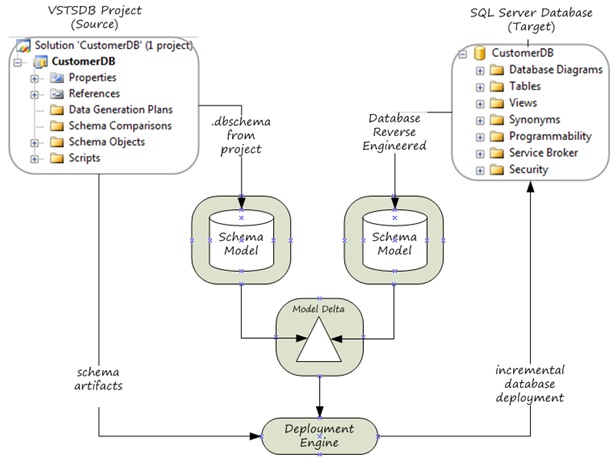
At the time of deployment the schema model defined by your project and the schema model defined by the target database are compared. The deployment engine then creates a deployment plan based on the difference of the model comparison. The deployment plan is final executed against the target database or the deployment plan is deployed to script. This demonstrates how the target database change script creation is deferred to the time of deployment. This enables you to build your schema once and deploy it many times. The source controlled version of your project represents the truth of the database schema and the "compiled" .dbschema file is a blueprint of your schema at a specific point in time. The .dbschema file is also mobile can be included in the application release payload and deployed along with the rest of the application stack. Very cool!
It is recommended that you test your deployments during development and integration. Testing the deployment ahead of time will provide you with an understanding of what the deployment engine will do against a target database instance. An easy way to do this is to deploy to script, review, and then run it against a test environment. You can also test deploying your project against a test database instance and schema compare the test instance with production or development. Testing ahead of time will also provide you the confidence needed to eventually automate the execution of your deployments. If you have multiple environments such as: DEV, TEST, INT, ACCEPT, PPE, or PROD, you will want to deploy to these environments to mimic the promotion of schema deployments before an actual deployment to production.
I hope this is helpful and provides a solid foundation for the future topics in the Best Practices series. Next time we will take a look at Data Motion which will be a nice segue given this overview. We will dig into that topic and use our simple Customer Database exercise to demonstrate how to deploy schema changes when the target database has existing data and tables will be modified during the deployment process. Until next time, let me know what you think about this and any areas that you believe need to be addressed further.
Thanks to Jamie Laflen and Genevieve Orchard of the VSTSDB team for their contributions and help on finishing up this post.
Comments
- Anonymous
March 03, 2009
The manual approach is exactly what we do here! I've started using DBPro for a new project, with the idea it can be eventually be used for our existing [more critical] products.really looking forward to the "Data motion" topic :)thx, Jag - Anonymous
March 04, 2009
The comment has been removed - Anonymous
March 30, 2009
Continuing with the VSTS: DB Best Practices post series, let’s take a look at managing data motion in