How WebHCat Works and How to Debug (Part 1)
1. Overview and Goals
One of the common scenarios our customers facing are: why my Hive, Pig, or Scoop job submissions are failing? Most likely something is wrong with your WebHCat service.
In this article, we will try to answer some of the common questions like:
- What is WebHCat or sometimes referred to also as Templeton?
- Am I using it in my case?
- If I am using it, then how it works under the hood?
- How do I mitigate my WebHCat issue?
- What is Root Cause for my issue, why it happened anyway in the first place?
This article is constructed of two main parts. In the 1st part, we mainly discuss “How WebHCat Works” and hopefully that will give you answers to the first 3 questions in the above list. In the 2nd part, we focus on “How to Debug WebHCat”, and hopefully will answer the last two questions in the above list.
2. How WebHCat Works WebHCat is a REST interface for remote jobs (Hive, Pig, Scoop, MapReduce) execution. WebHCat translates the job submission requests into YARN applications and reports the status based on the YARN application status. WebHCat results are coming from YARN and troubleshooting some of them needs to go to YARN.
SSH shell/Oozie hive action directly interact with YARN for HIVE execution where as Program using HdInsight Jobs SDK/ADF (Azure Data Factory) uses WebHCat REST interface to submit the jobs.
Below control flow diagram illustrates WebHCat interaction at a cluster level (assuming the current active head node is headnode0)
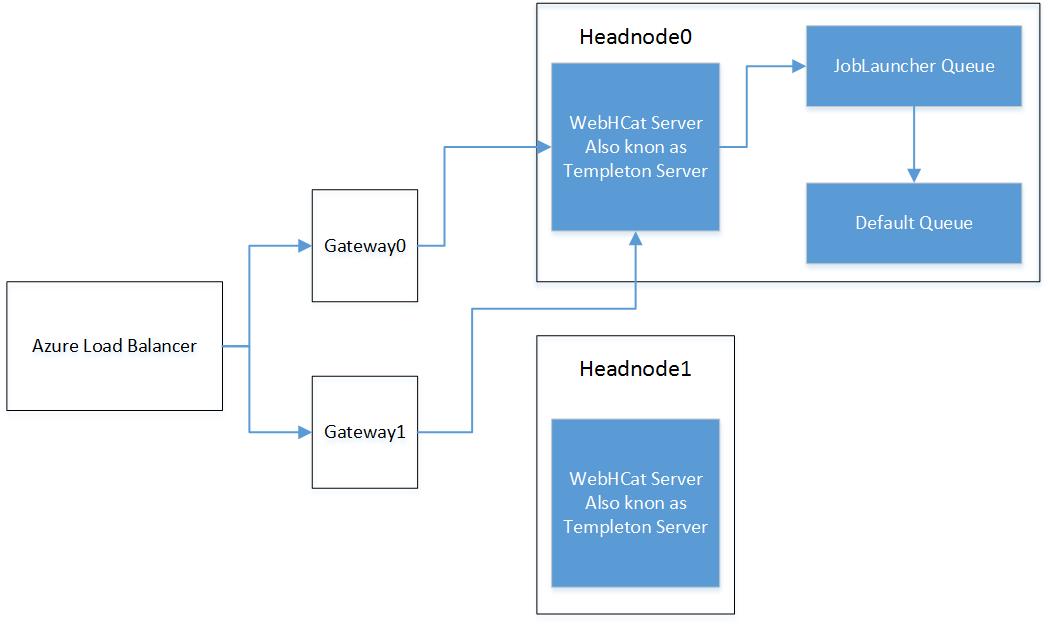
Gateway nodes proxies all cluster calls. Gateway nodes are behind Azure load balance which can distribute the incoming calls to any of the Gateway nodes. Each gateway node routes the incoming request to current active headnode (which is maintained through Zookeeper). Headnodehost is a hostname alias which HDInsight maintains which resolved to the current active head node.
The Templeton server will then submit the actual job to YARN.
Typical hive job execution interaction with WebHCat will be like
- Submit hive job for execution. Returns id which can be used to get job status.
- Pool for job completion using job status API.
- Check the job result by reading job output
Let’s submit a simple hive query to WebHCat and check its status. Below CURL command submitting HIVE query
$ curl -u UserName:Password -d user.name=admin -d execute="select+*+from+hivesampletable;" -d statusdir="wasb:///example/curl" "https://ClusterName.azurehdinsight.net/templeton/v1/hive"
{"id":"job_1488891723504_0001"}
$ curl -G -u UserName:PassWord -d user.name=UserName https://ClusterName.azurehdinsight.net/templeton/v1/jobs/job\_1488891723504\_0001
{
"status": {
"mapProgress": 1.0,
"reduceProgress": 1.0,
"cleanupProgress": 0.0,
"setupProgress": 0.0,
"runState": 2,
"startTime": 1488928210438,
"queue": "default",
"priority": "NORMAL",
"schedulingInfo": "NA",
"failureInfo": "NA",
"jobACLs": {},
"jobName": "TempletonControllerJob",
…
…
…
}
As we see job submission returned as Job ID which is used later to get the job status. Resource Manager UI shows below YANR jobs executed

We can notice here that we have an YARN application with the same suffix as job ID returned by WebHCat. Each job submitted to WebHCat results in a MapReduce job named “TempletonControllerJob” whose mapper launches another YARN job which does the real work.
WebHCat execution model scales well with the cluster resources as the job (or query) execution is delegated to a YARN application. But this also makes this path very heavy. Each job execution needs a YARN application with 2 containers.
“TempletonControllerJob” saves the job status to /user/{user.name}/{statusdir} folder. Enumerating the folder content looks like below
$ hdfs dfs -ls /user/admin/firsttempletonjobstatusdir
Found 3 items
-rw-r--r-- 1 admin supergroup 3 2017-03-07 00:53 /example/curl/exit
-rw-r--r-- 1 admin supergroup 376 2017-03-07 00:53 /example/curl/stderr
-rw-r--r-- 1 admin supergroup 0 2017-03-07 00:53 /example/curl/stdout
exit: Contains the exit code of the HIVE query. For successful queries ZERO is expected. Non-zero exit code is expected otherwise.
stdout: Contains the query output. In-case of select query this will contain the result set in text.
stderr: Contains the Hive logs (similar to what we will see when ran on HIVE CLI)
NOTE: In-case where the HIVE query execution failed you will see the corresponding “TempletonControllerJob” status as SUCCEEDED. The status directory contains the actual details. The status you get here is the just the “TempletonControllerJob” status, the actual hive job status is at “status directory”.
If you look at the corresponding HIVE job launched by TempletonControllerJob, if you see the status as “SUCCEEDED”, it still doesn’t mean that the hive job actually succeeded. That only means that YARN job succeeded, not necessarily the Hive job. You must look into the status directory in order to make sure the hive job actually succeed. Link To Part 2