Appending an Index Column to Distributed DataFrame based on another Column with Non-unique Entries
The sample Jupyter Scala notebook described in this blog can be downloaded from https://github.com/hdinsight/spark-jupyter-notebooks/blob/master/Scala/AddIndexColumnToDataFrame.ipynb
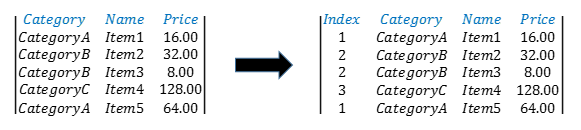
In many Spark applications a common user scenario is to add an index column to each row of a Distributed DataFrame (DDF) during data preparation or data transformation stages. This blog describes one of the most common variations of this scenario in which the index column is based on another column in the DDF which contains non-unique entries. This means, entries in the index column are repeated following the entries in the column on which it is based in a method similar to hashing to some integer values. A visualization of the transformation of the original DDF to the target DDF is shown below where the index column is based on the Category column.
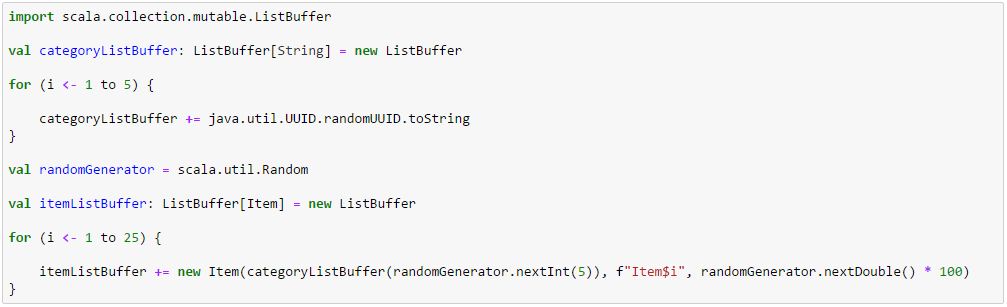
In the example notebook, we declare an Item case class and create a DDF of objects of type Item. In this particular example, there are 25 items belonging to 5 categories represented as Globally Unique Identifiers (GUIDs).


The basic idea is to create a lookup table of distinct categories indexed by unique integer identifiers. The way to avoid is to collect the unique categories to the driver, loop through them to add the corresponding index to each to create the lookup table (as Map or equivalent) and then broadcast the lookup table to all executors. The amount of data that can be collected at the driver is controlled by the spark.driver.maxResultSize configuration which by default is set at 1 GB for Spark 1.6.1. Both collect and broadcast will eventually run into the physical memory limits of the driver and the executors respectively at some point beyond certain number of distinct categories, resulting in a non-scalable solution.



If the lookup table can be broadcast to all the executors, it can be used in a User Defined Function (UDF) to add the index column to the original DDF using the withColumn method.


An alternate scalable way is to create a DDF of distinct categories, use the zipWithIndex method on the underlying Resilient Distributed Dataset (RDD) and generate a new DDF with index and category columns.
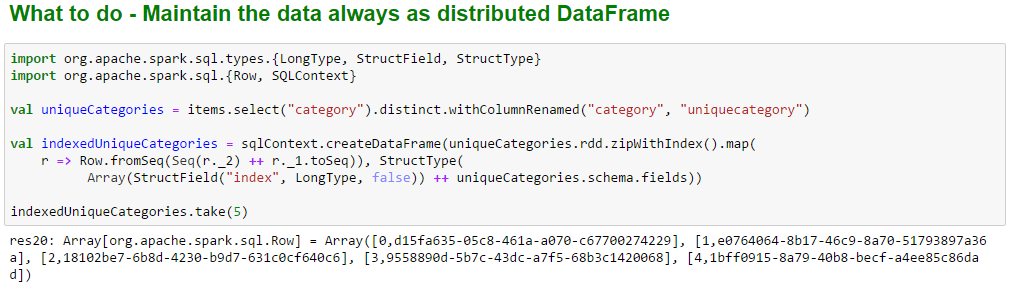
Once the new DDF is generated there are two ways of creating the target DDF. One way is by inner joining the original DDF with the new DDF on the category columns and dropping the duplicate category column.

Another way is by using DDF as the lookup table in a UDF to add the index column to the original DDF using the withColumn method.


If required, the columns in the target DDF can be reordered to make the index column the first column. This step may be avoided by changing the join order in Method 1.

[Contributed by Arijit Tarafdar]