What’s new for SQL Server 2016 Analysis Services in CTP3
We are really excited to announce the SQL Server 2016 Analysis Services CTP 3 update can be downloaded within the next few days here. This month’s update includes some great improvements and features that we think you will be very excited about.
If this is your first look at Analysis Services in SQL Server 2016 Preview, here is a small recap of the features we’ve already shipped:
- XEvents support through SSMS allows a simplified way of monitoring your Analysis Services instances, both Tabular and Multidimensional.
- For a significant reduction in processing time the Tabular model now supports parallel partition processing.
- Over 50 new DAX functions, including variable support for measures, allowing for more powerful and diverse models.
- The DirectQuery mode in Analysis Services has significantly improved performance compared to SQL Server 2014.
- Improvements made to the Analysis Services formula engine improved DAX performance through Super DAX resulting in faster tabular models in SQL Server 2016.
With CTP3 available for download in the next few days, we are releasing many new features for Analysis Services.
A new SQL Server 2016 compatibility level
The tabular model offers new features that can only be used with a SQL Server 2016 tabular server. To leverage these new features, you will need to create a new model that is set to the new 1200 compatibility level. These models cannot be deployed to a SQL Server 2014 or earlier.
The biggest change with this compatibility level is that we have moved away from using XMLA and its inherited multidimensional taxonomy as the primary representation of a tabular model. A new tabular model definition and tabular object model will be available in an upcoming CTP of SQL Server 2016 that allows for simplified scripting and development for tabular models. The biggest benefits of this new scripting language and object are:
Both the scripting language and object model are native to tabular, meaning that objects are now based on a model, table, and relationship nomenclature. In the past you had to map your tabular objects to equivalent multidimensional object names (i.e., using cube metadata when referring to a model).
- Changes to the model now only change a single object instead of having to map everything to multidimensional objects, this makes metadata operations really fast.
- As metadata changes are now localized in the script, it allows for simple code merges.
- The script to represent the schema of the model is developed together with the Power BI team. We aim for parity with Power BI API’s that allows for reusability between products. The new language to describe and manage objects will be JSON, just like the Power BI API’s.
Not everything described above is available in CTP3. In this CTP, scripting is not yet available in either SSMS or the XMLA client or using AMO directly. This will come in subsequent releases so stay tuned.
Upgrading models to the new 1200 compatibility level is also not available in the current CTP but will be available in a subsequent CTP. There are also some features that are sure to ship, but not yet supported publicly. For more information about capabilities we expect to deliver for 1200 models, see the release notes Both XMLA and AMO will continue to functional with full parity on SQL Server 2016 with tabular models set to compatibility level 1103 and below.
Bi-directional cross filtering and an improved diagram view layout
Bi-directional cross filtering is a new feature for SQL Server 2016 that allows modelers to determine how they want filters to flow. In SQL Server 2014, filter context of a table is based on the values in a related table. With Bi-directional cross-filtering the filter context is propagated to second related table on the other side of a table relationship. This will allow you to solve the “many-to-many” problem without writing complicated DAX formula’s. For more information on Bi Directional cross filtering see this help topic.
An improved diagram view layout helps you navigate complex models with ease. The design has been optimized to understand complex relationships in your model. You will now be able to see immediately the filter direction of the relationship and the cardinality of the data.
MDX support for DirectQuery
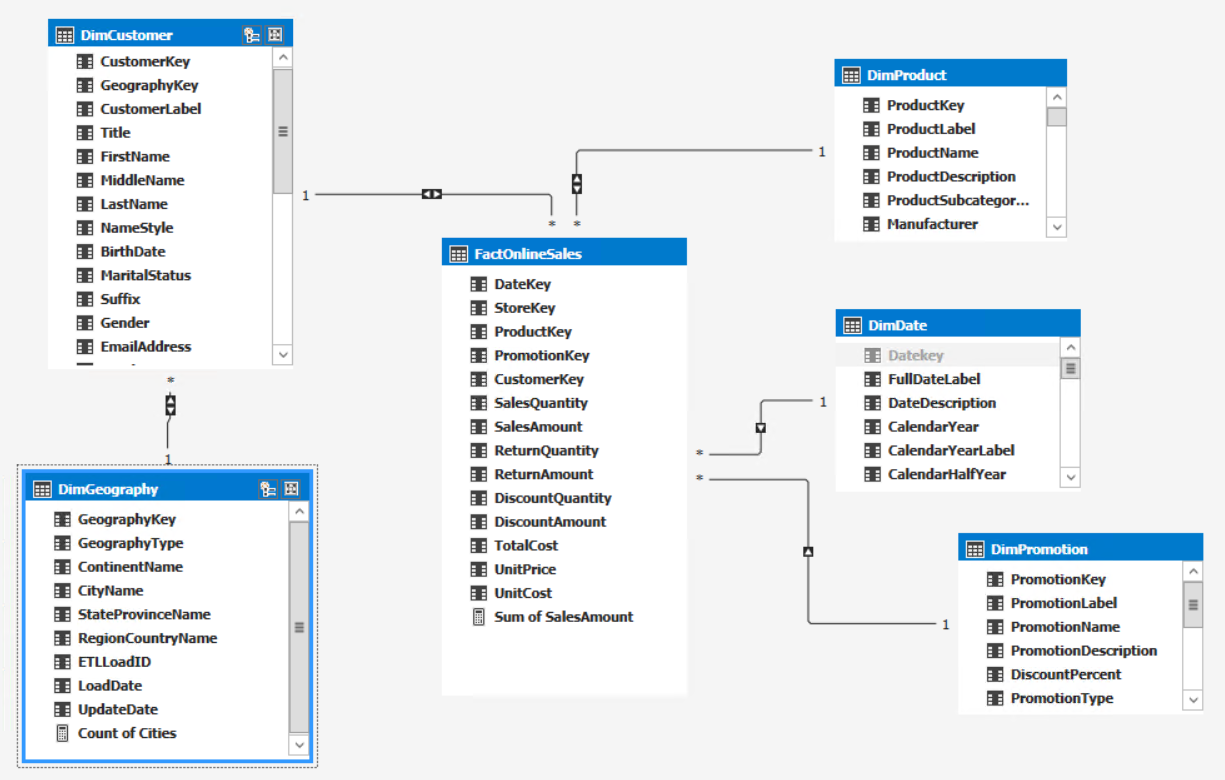
With SQL Server 2016 you can now use Excel PivotTables or any other MDX client tool to query a Tabular model in DirectQuery mode. This is available for models in every compatibility level, in this CTP there are still some limitations though that are described in the release notes. Most notably DirectQuery is not yet enabled for compatibility level 1200 models but works for all other compatibility levels. We expect most of these limitations to be removed once we release the final product.
Below is a screenshot of an Excel PivotTable connected to a Tabular model in DirectQuery mode:
Support for Oracle, Teradata and APS for DirectQuery
DirectQuery in SQL Server 2016 can now be used to connect directly to SQL Server, SQL Server Parallel Data Warehouse (Microsoft Analytics Platform System), Oracle and Teradata. This will allow you to expose more data sources directly to your business users through the semantic layer of an Analysis Services data model without caching the data in Analysis Services. DirectQuery is not yet enabled for compatibility level 1200 models but works for all other compatibility levels.
The SSAS developer tools (SSDT) are now available for Visual Studio 2015 in a simplified setup experience
SSDT for Analysis Services is now available as part of SQL Server Data Tools Visual Studio 2015 Preview that can be downloaded here. This will give you a single simplified installation experience for all your SQL Server data tools which are now available in Visual Studio 2015.

Where the previous SSDT – BI installation was about 1 GB in size, this setup is very small and will only download what you need. For example, if you already have Visual Studio installed it will not download it again. This will make incremental updates much easier and faster to consume.
This version of SSDT allows you develop Multidimensional and Tabular models for all supported versions of SQL Server Analysis Services.
Improved DAX formula editing
Updates to the formula bar help you write formulas with more ease by differentiating functions, fields and measures using syntax coloring, it provides intelligent function and field suggestions and tells you if parts of your DAX expression are wrong using error 'squiggles'. It also allows you to use multiple lines (Alt + Enter) and indentation (Tab). The formula bar now also allows you to write comments as part of your measures, just type “//” and everything after these characters on the same line will be considered a comment.
Below you see an example of a measures that uses variables and comments and shows all items differentiated by syntax highlighting:

Of course variables, new DAX expressions, and comments will only be available when you use SQL Server 2016 as workspace server. If you use SQL Server 2014 you will see the DAX expressions that were available in that version but the syntax highlighting and multi lines are available. We are planning to make more improvements to the editor in subsequent releases so stay tuned.
A new tabular script in SSDT
As mentioned before, tabular models set to the SQL Server 2016 compatibility level (1200) no longer use XMLA to describe the model. The bim file in SSDT now shows the schema using JSON:
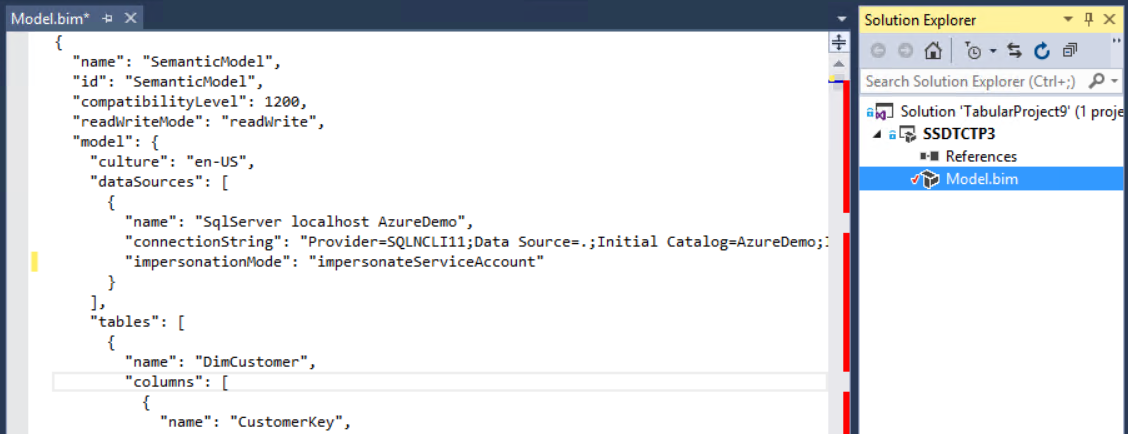
We are planning more improvements in this area to allow for better code merges in a later release. More on this in a later blog post.
Improved SSDT modelling performance
Another great improvement thanks to the new tabular object model is that metadata operations in SSDT will be much faster. For example, creating a relationship on a model set to the SQL Server 2014 compatibility level (1103) with 23 tables takes 3 seconds on my laptop. The same relationship on a model created set to the SQL Server 2016 compatibility level (1200) takes just under a second.
Formula Fixup
With formula fixup on a SQL Server 2016 compatibility level (1200) tabular model in SSDT will automatically update any measures that is referencing a column or table that was renamed. No need to do it yourself anymore!
Saving incomplete measures
Don’t you hate it when you are working on a complicated DAX formula but it is time to go pick up your kids or go to that meeting and there is no way to save your formula because it contains errors? So you either e-mail it to yourself or put it into a new text file. Well no more. You can now save incomplete measures directly in your SSDT on a SQL Server 2016 compatibility level (1200) tabular model solution and pick it up again tomorrow.
Support for Visual Studio Configuration manager
To support multiple environments, like Test and Pre-production environments, Visual Studio allows developers to create multiple project configurations using the configuration manager. Multidimensional models already leverage this but Tabular models do not. Starting CTP3 you can now use the Configuration manager to deploy to different servers from VS, for more on the Visual Studio configuration manager see this help topic.
DBCC support for Analysis Services
Database Consistency Checker (DBCC) runs internally to detect potential data corruption issues on database load, but can also be run on demand if you suspect problems in your data or model. DBCC runs different checks depending on whether the model is tabular or multidimensional. See DBCC for Analysis Services for details.
In my next blog post, I’ll walk you through what Bi-directional filtering is and how it solves the many-to-many dilemma. Stay tuned!
Comments
Anonymous
October 28, 2015
So, in other words... XEvents for monitoring, and improvements to TABULAR models. I understand that tabular needs improvements to get closer to feature parity with multidimensional... but there seems to be little-to-no attention to multidimensional (as far as new features with each new version of SQL since ~2012 when TAB started to really debut)... and given that there's not really any MIGRATION path between multidimensional models and tabular models... nor any interoperability (as far as querying between MDX and TAB cubes)... it leaves those with an investment in multidimensional cubes feeling neglected, betrayed, as well as suspicious that this shift will occur again when the next shiny model comes along. I'm not saying that TAB doesn't provide some benefits... I just think that the approach by which its adoption is being recommended leaves a LOT to be desired.Anonymous
October 29, 2015
Great work! Can we translate existing XMLA's to JSON format? Looking forward to more updates.Anonymous
October 29, 2015
I did install new SSDT OCT preview. Now, i can see all BI related project templates. But under Analysis Service only Multidimensional Project, NOT tabular project. Am i missing something or do you know, when it will be available?Anonymous
October 29, 2015
Binary, did you do a clean install of the SSDT Toolset or did you install on top of an existing SSDT or VS installation? There is a step in the setup that runs a command that registers the BI templates with VS, it's possible that that failed. You can run the command manually by doing the following from a admin command prompt: <SystemDrive>Program Files (x86)Microsoft Visual Studio 14.0Common7IDEdevenv /setup This may fix the issue, also you should have some setup logs created in your APPDATA folder which might hint to any failures.Anonymous
October 29, 2015
Binay, sorry about the typo in the nameAnonymous
October 31, 2015
It solved the issue.. thanks Matt!!Anonymous
November 03, 2015
Some great improvements in DAX, especially around the pain points of the excel formula bar with "clippy"-esque intellisense & not causing the whole model to refresh for metadata changes. But no Multidim additions? the Formula Engine is STILL single-threaded? The only improvement in SSAS that i can think of is the addition of the DIVIDE() function Tabular's usefulness is limited once you move beyond simple sums, counts and using it as a simple way to speed up reporting vs modelling complex multidimensional dataAnonymous
November 09, 2015
When I read between the lines, it seems that cubes are dead. I guess MS doesn't want to just come right out and say they took us all down the wrong path, but the whole industry went that way. MDX is the hardest language I have coded in for 40 years. Users find cubes very hard to use past simple pivot tables. Reporting against cubes is also hard, with power users not really being able to pull it off. I have done some amazing work building cubes, only to see no one in our vast organization capable of using them. I spent a lot of time gaining SSAS skills, but it seems tabular, as limited as it currently is, will be the future direction.