Power Automate でテキスト認識の事前構築済みモデルを使用する
AI Builder でのテキスト認識事前構築済みモデルは、画像やドキュメントから印刷テキストと手書きテキストを抽出します。 このモデルを Power Automate で使用すると、スキャンしたドキュメント、写真、PDF のテキストを自動的に処理するワークフローを作成できるため、効率的なデータ処理と他のアプリケーションとの統合が可能になります。
Power Automate でのテキスト認識事前構築済みモデルの使用に関するガイドをこのドキュメントで提供します。
Power Automate フローの初期化
Power Automate フローの初期化は、自動化プロセスを設定する最初のステップです。 このステップでは、フローのトリガーと初期入力パラメーターを定義できます。 初期化時に、フローが正しく開始され、テキスト認識タスクを効率的に処理するために必要な情報が含まれていることを確認できます。
フローを初期化するには、次の手順を実行します。
Power Automate にサインインします。
ナビゲーション メニューで、マイ フロー を選択し、新しいフロー>インスタント クラウド フロー を選択します。
フローに名前を付け、このフローをトリガーする方法を選択します の下の フローを手動でトリガーする を選択した後、作成 を選択します。
手動でフローをトリガー を展開し、入力タイプとして +入力の追加>ファイル を選択します。
+新しいステップ>AI Builder 選択し、アクションのリストにある 画像や PDF ドキュメントのテキストを認識する を選択します。
画像入力を選択し、次に動的なコンテンツ リストからファイル コンテンツを選択します。
![[パラメーター] タブで Power Automate フローを初期化しているスクリーンショット。](media/trigger-text-recognition-2.png)
結果を処理するには、文書全文、ページ・テキスト、または文書テキストを行単位で使用できます。
ドキュメント テキスト全体またはページ全体のテキストを取得します
ドキュメント全体のテキストまたは特定のページテキストに対してアクションを実行する必要がある場合、このオプションが便利です。 ページ テキストの使用例は、部分文字列を検索する場合や、サブストリングをダウンストリーム アクションに渡す場合です。
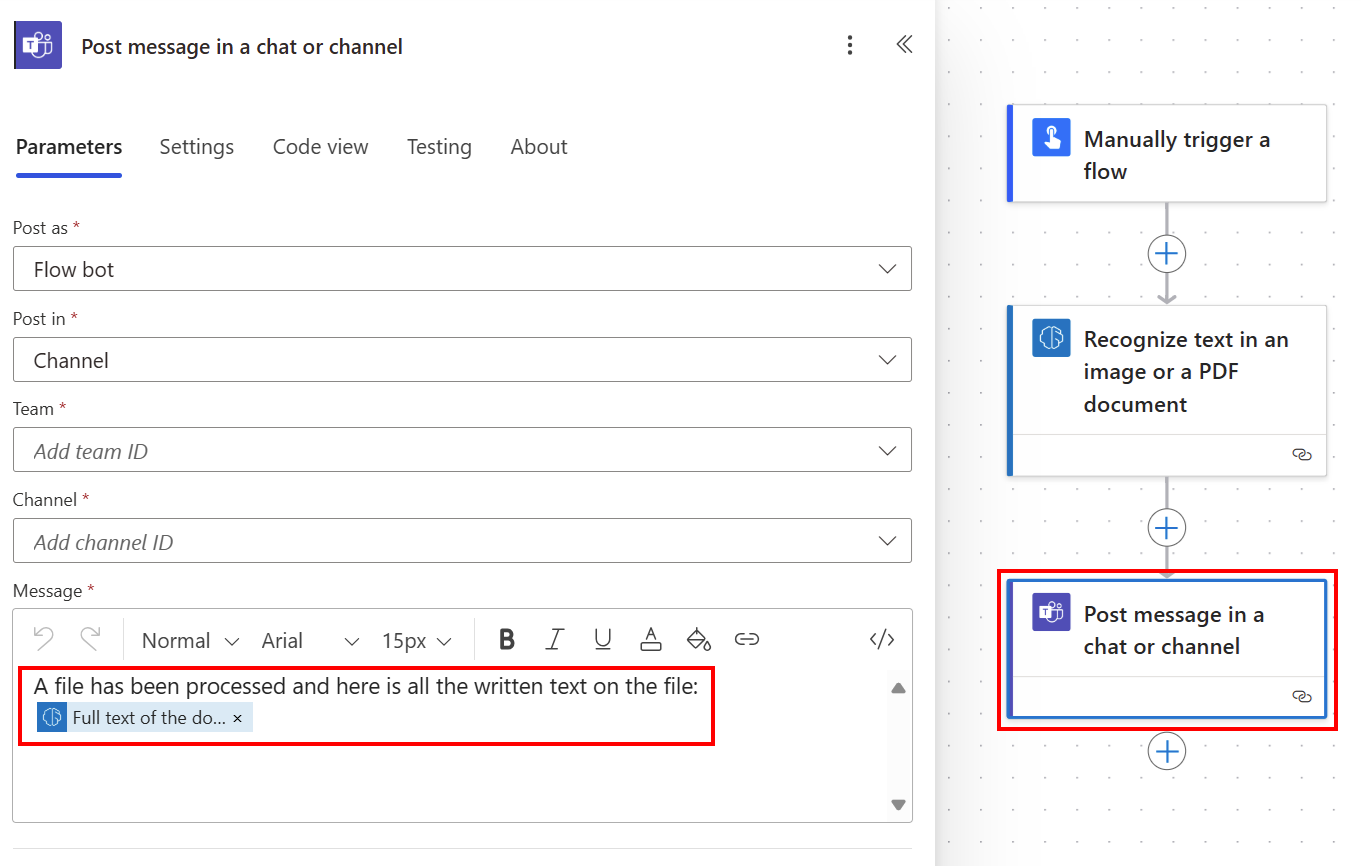
抽出されたすべてのテキストは、動的コンテンツ リストから ドキュメントのフル テキスト を使用して Teams チャネルに投稿できます。
ドキュメントのテキストを行ごとに取得します
ドキュメントのテキストを行ごとに取得すると、特定のテキスト行を分離したり、都合のよいときにテキストの書式を変更したりする必要がある場合に便利です。
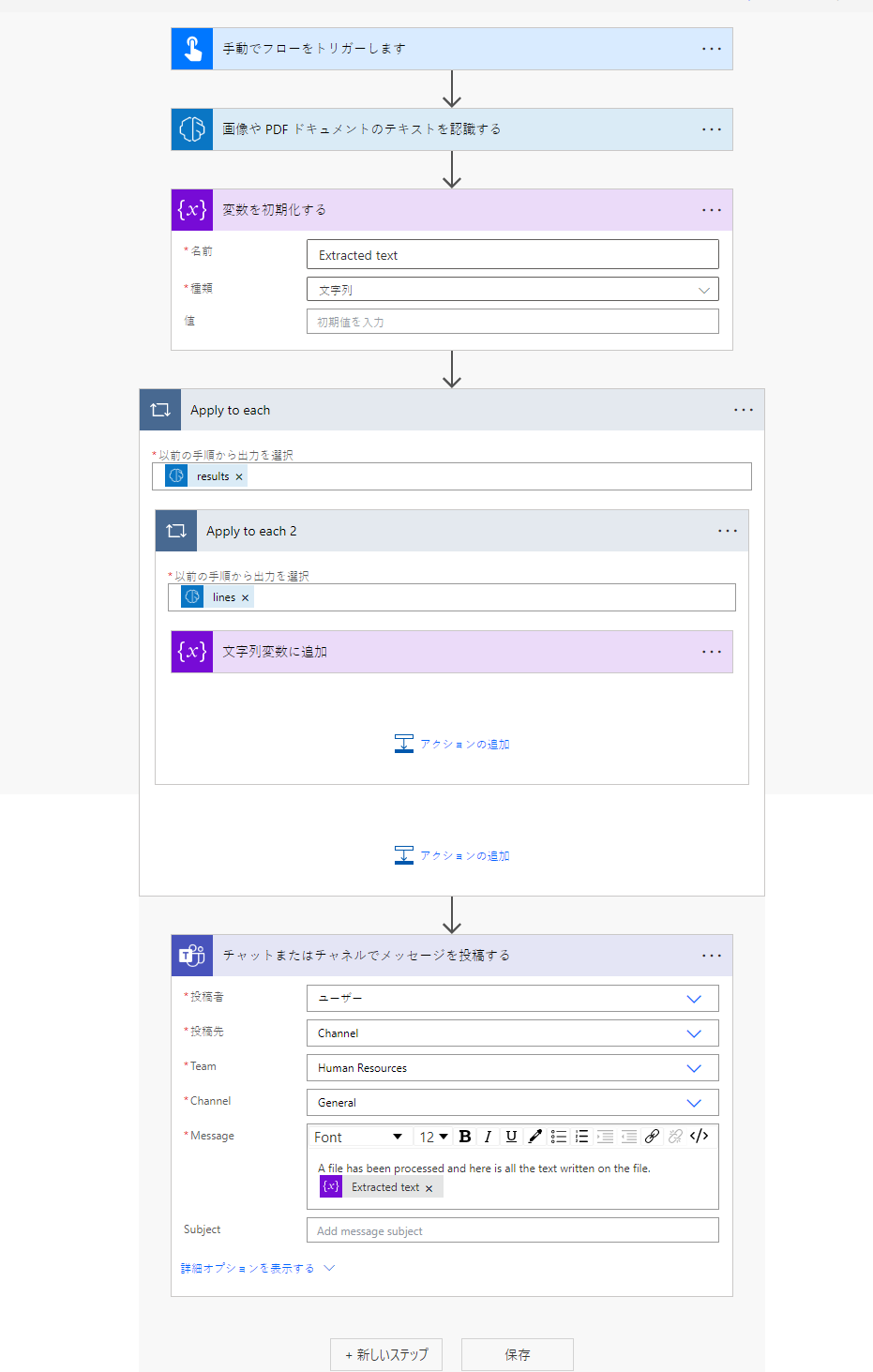
文字列変数を作成するには、 +新しいステップ>コントロールを選択し、 変数の初期化を選択します。
たとえば 抽出されたテキスト という名前を付けます。
+ 新しいステップ>コントロールを選択し、 文字列変数に追加を選択します。
値 フィールドの動的コンテンツから テキスト を選択します。
これは、ページのリスト内の行テキストのリストを読み取っているときに、2 つのそれぞれに適用 アクションを自動生成します。 その後、抽出されたすべてのテキストを Teams チャネルに投稿できます。
おつかれさまでした! これで、テキスト認識モデルを使用するフローを作成できました。 お客様のニーズに合うまで、このフローを基にして構築を継続できます。 右上にある保存を選択し、テストを選択してフローを試します。
Parameters
AI Builder のテキスト認識事前構築済みモデルには次の入力パラメーターと出力パラメーターが含まれています。
input
| 件名 | Required | タイプ | プロパティ |
|---|---|---|---|
| イメージ | 可 | file | 分析する画像 |
出力
検出されたテキストは、結果リストの行サブ リストに埋め込まれます。 最初に それぞれに適用 アクションから 行 を選択する必要があり、次の列すべてを表示します。
| 件名 | 型 | 内容 |
|---|---|---|
| テキスト | 文字列 | 検出されたテキスト行を含む文字列 |
| ページ番号 | string | テキストのページ番号が検出されました |
| 座標 | 浮動小数 | 検出されたテキストの座標 |
| ドキュメントの全文 | string | 検出された全文 |
| ページの全文 | string | 全ページ テキストが検出されました |