クイックスタート: ワンクリックでのデータの取り込み (プレビュー)
ワンクリックでのインジェストを使用すると、データ インジェスト プロセスを簡単かつ迅速に、直感的に行うことができます。 ワンクリックでのインジェストは、データの取り込み、データベース テーブルの作成、マッピング構造の準備をすばやく行い、開始するのに役立ちます。 1 回限りまたは継続的なインジェスト プロセスとして、データ形式の異なるさまざまな種類のソースからデータを選択します。
次の機能により、ワンクリックでのインジェストが使いやすくなります。
- インジェスト ウィザードによる直感的なエクスペリエンス
- わずか数分でのデータの取り込み
- ローカル ファイル、BLOB、コンテナーなどの、さまざまな種類のソースからのデータの取り込み (最大 10,000 個の BLOB)
- さまざまな形式のデータの取り込み
- 新規または既存のテーブルへのデータの取り込み
- テーブル マッピングとスキーマが推奨されており、簡単に変更できる
データの初回取り込み時やデータのスキーマに不慣れな場合に、ワンクリックでのインジェストは特に効果的です。
前提条件
Azure サブスクリプション。 無料の Azure アカウントを作成します。
Synapse Studio または Azure portal を使用して Data Explorer プールを作成します
Data Explorer データベースを作成します。
Synapse Studio の左側のペインで、 [データ] を選択します。
+ (新しいリソースの追加) >[Data Explorer プール] を選択し、次の情報を使用します。
設定 推奨値 説明 プール名 contosodataexplorer 使用する Data Explorer プールの名前 Name TestDatabase データベース名はクラスター内で一意である必要があります。 既定のリテンション期間 365 クエリにデータを使用できることが保証される期間 (日数) です。 期間は、データが取り込まれた時点から測定されます。 既定のキャッシュ期間 31 頻繁にクエリされるデータが、長期ストレージではなく SSD ストレージまたは RAM で利用できるように保持される期間 (日数) です。 [作成] を選択してデータベースを作成します。 通常、作成にかかる時間は 1 分未満です。
テーブルを作成する
- Synapse Studio の左側のウィンドウで、 [開発] を選択します。
- [KQL スクリプト] で、[+] (新しいリソースの追加) >[KQL スクリプト] を選びます。 右側のウィンドウで、スクリプト名を指定できます。
- [接続先] メニューで、[contosodataexplorer] を選択します。
- [データベースの使用] メニューで、 [TestDatabase] を選択します。
- 次のコマンドを貼り付け、 [実行] を選択してテーブルを作成します。
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)ヒント
テーブルが正常に作成されたことを確認します。 左側のペインで、[データ] を選び、contosodataexplorer のその他のメニューを選び、[最新の情報に更新] を選択します。 [contosodataexplorer] で [テーブル] を展開し、StormEvents テーブルが一覧に表示されていることを確認します。
ワンクリック ウィザードにアクセスする
ワンクリックでのインジェスト ウィザードを使用すると、ワンクリックでのデータ取り込み手順を画面の指示に従って行うことができます。
Azure Synapse からウィザードにアクセスするには、次の手順を行います。
Synapse Studio の左側のペインで、[データ] を選択します。
[Data Explorer データベース] で、関連するデータベースを右クリックし、[Azure Data Explorer で開く] を選択します。
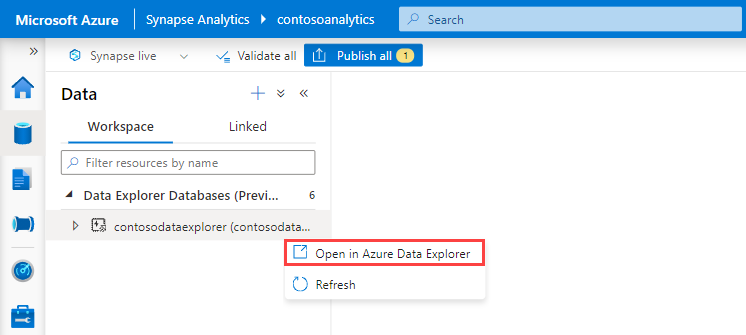
関連するプールを右クリックし、[新しいデータを取り込む] を選択します。
Azure portal からウィザードにアクセスするには、次の手順を行います。
Azure portal で、関連する Synapse ワークスペースを検索して選択します。
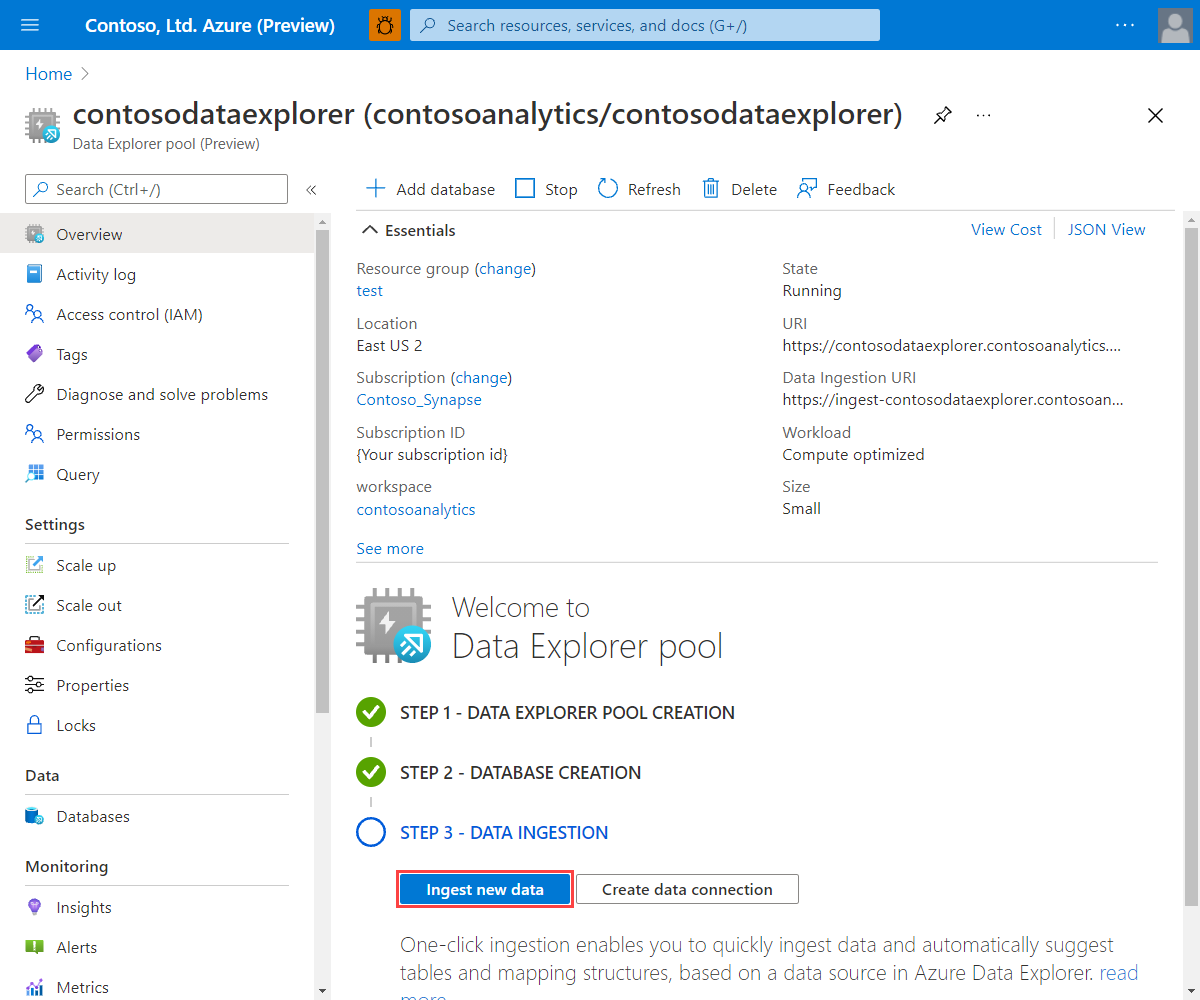
[Data Explorer プール] で、関連するプールを選択します。
[Welcome to Data Explorer pool](Data Explorer プールへようこそ) ホーム画面で、[新しいデータを取り込む] を選択します。
Azure Data Explorer の Web UI からウィザードにアクセスするには、次の手順を行います。
- 開始する前に、次の手順に従って、クエリおよびデータ インジェスト エンドポイントを取得します。
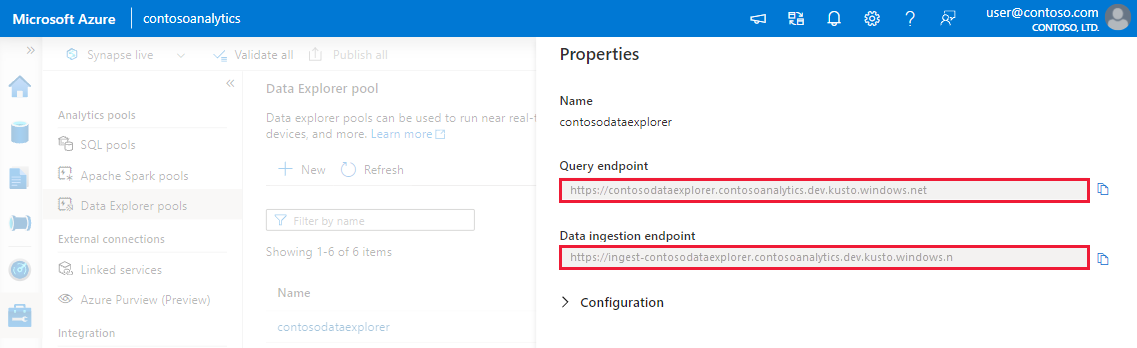
Synapse Studio の左側のペインで、 [管理]>[Data Explorer プール] を選びます。
詳細を表示する データ エクスプローラー プールを選択します。
![既存のプールの一覧が表示されている [Data Explorer プール] 画面のスクリーンショット。](../media/ingest-data-pipeline/select-data-explorer-pool.png)
クエリとデータ インジェストのエンドポイントをメモします。 データ エクスプローラー プールへの接続を構成するときに、クラスターとしてクエリ エンドポイントを使用します。 データ インジェスト用に SDK を構成する場合は、データ インジェスト エンドポイントを使用します。
- Azure Data Explorer の Web UI で、"クエリ エンドポイント" に接続を追加します。
- 左側のメニューから [クエリ] を選択し、[データベース] または [テーブル] を右クリックして、[新しいデータを取り込む] を選択します。
- 開始する前に、次の手順に従って、クエリおよびデータ インジェスト エンドポイントを取得します。
ワンクリックでのインジェスト ウィザード
Note
このセクションでは、イベント ハブをデータ ソースとして使用するウィザードについて説明します。 また、これらの手順を使って、BLOB、ファイル、BLOB コンテナー、ADLS Gen2 コンテナーからデータを取り込むこともできます。
例の値を Synapse ワークスペースの実際の値に置き換えます。
[宛先] タブで、取り込まれたデータのデータベースとテーブルを選択します。
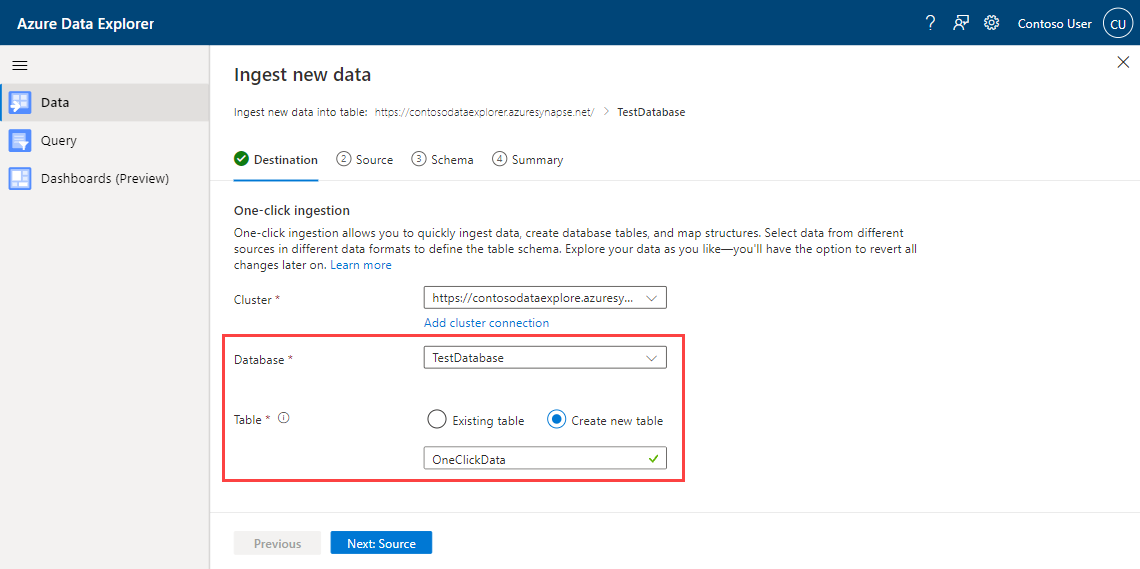
[ソース] タブで、次のように指定します。
インジェストの [ソースの種類] として [イベント ハブ] を選択します。

次の情報を使用して、イベント ハブのデータ接続の詳細を入力します。
設定 値の例 説明 データ接続名 ContosoDataConnection イベント ハブ データ接続の名前 サブスクリプション Contoso_Synapse イベント ハブが存在するサブスクリプション。 イベント ハブの名前空間 contosoeventhubnamespace イベント ハブの名前空間。 コンシューマー グループ contosoconsumergroup Even Hub コンシューマー グループの名前。 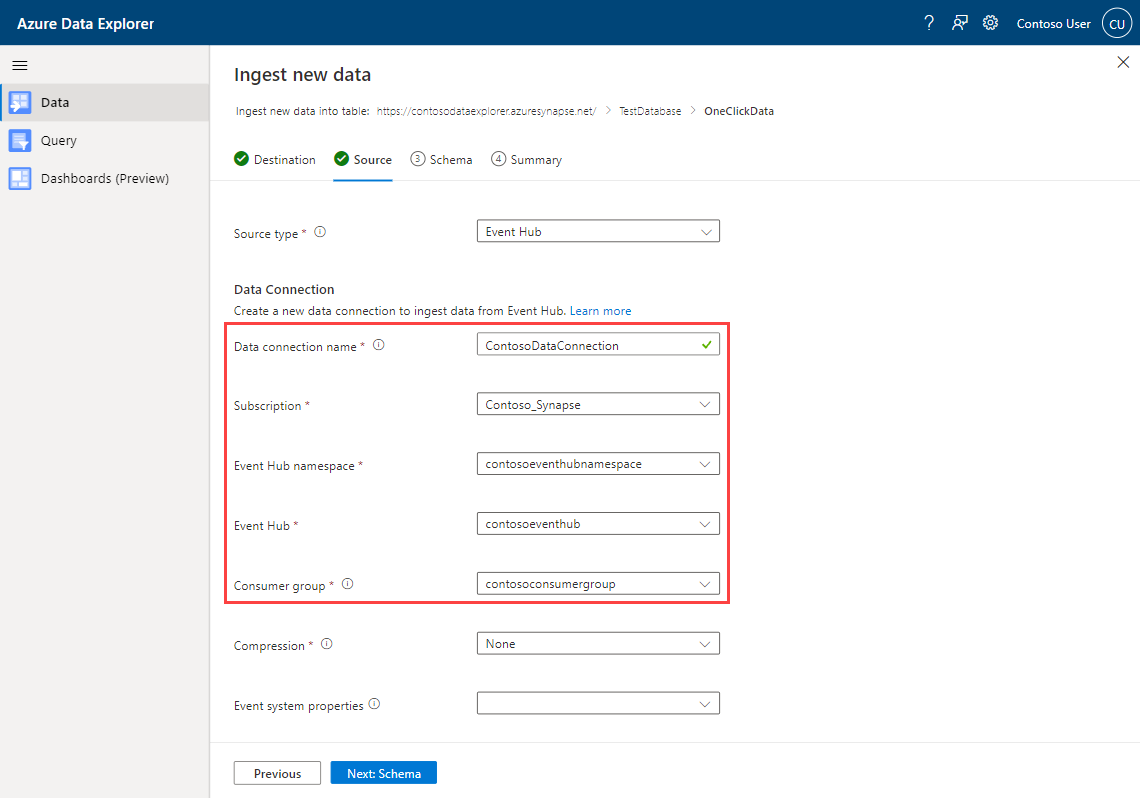
[次へ] を選択します。
スキーマ マッピング
サービスでは、変更可能なスキーマおよびインジェストのプロパティが自動的に生成されます。 新しいテーブルまたは既存のテーブルのどちらに取り込むかによって、既存のマッピング構造を使用することも、新しいマッピング構造を作成することもできます。
[スキーマ] タブで、次の操作を行います。
- 自動生成された圧縮の種類を確認します。
- データの形式を選択します。 異なる形式を使用すると、さらに変更を加えることができます。
- [エディター] ウィンドウでマッピングを変更します。
ファイル形式
ワンクリック インジェストでは、インジェスト用に Data Explorer でサポートされているすべてのデータ形式からデータを取り込むことができます。
エディター ウィンドウ
[スキーマ] タブの [エディター] ウィンドウで、必要に応じてデータ テーブルの列を調整できます。
テーブルに加えることができる変更は、次のパラメーターによって異なります。
- テーブルの種類が新規かまたは既存か
- マッピングの種類が新規かまたは既存か
| テーブルの種類です。 | マッピングの種類 | 使用可能な調整 |
|---|---|---|
| 新しいテーブル | 新しいマッピング | データ型の変更、列名の変更、列の削除、昇順で並べ替え、降順で並べ替え |
| 既存のテーブル | 新しいマッピング | 新しい列 (その後データ型の変更、名前の変更、および更新が可能) 新しい列、昇順で並べ替え、降順で並べ替え |
| 既存のマッピング | 昇順で並べ替え、降順で並べ替え |
注意
新しい列を追加するとき、または列を更新するときに、マッピング変換を変更できます。 詳細については、マッピング変換に関するページを参照してください。
マッピング変換
一部のデータ形式マッピング (Parquet、JSON、Avro) では、簡単な取り込み時の変換がサポートされています。 マッピング変換を適用するには、エディター ウィンドウで列を作成または更新します。
マッピング変換は、データ型が int または long であるソースを使用して、string または datetime 型の列に対して実行できます。 サポートされているマッピング変換は次のとおりです。
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
データ インジェスト
スキーマ マッピングと列の操作が完了すると、インジェスト ウィザードでデータ インジェスト プロセスが開始されます。
コンテナー以外のソースからのデータ取り込みは、直ちに結果が反映されます。
データ ソースがコンテナーの場合は、次のようになります。
- Data Explorer のバッチ処理ポリシーによりデータが集計されます。
- インジェストが完了すると、インジェスト レポートをダウンロードして、処理された各 BLOB のパフォーマンスを確認できます。
初期データ探索
インジェストが完了すると、ウィザードには、データの初期探索で クイック コマンド を使用するためのオプションが表示されます。