チュートリアル: Parquet 形式で Event Hubs データをキャプチャし、Azure Synapse Analytics を使用して分析する
このチュートリアルでは、Stream Analytics のノー コード エディターを使用して、Event Hubs のデータを Parquet 形式で Azure Data Lake Storage Gen2 にキャプチャするジョブを作成する方法を示します。
このチュートリアルでは、以下の内容を学習します。
- イベント ハブにサンプル イベントを送信するイベント ジェネレーターをデプロイする
- ノー コード エディターを使用して Stream Analytics のジョブを作成する
- 入力データとスキーマを確認する
- イベント ハブ データをキャプチャする Azure Data Lake Storage Gen2 を構成する
- Stream Analytics ジョブの実行
- Azure Synapse Analytics を使用して Parquet ファイルのクエリを実行する
前提条件
始める前に、次の手順が完了していることを確認してください。
- Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成してください。
- TollApp イベント ジェネレーター アプリを Azure にデプロイします。 'interval' パラメーターを 1 に設定し、この手順で新しいリソース グループを使用します。
- Data Lake Storage Gen2 アカウントを使用して Azure Synapse Analytics ワークスペースを作成します。
ノー コード エディターを使用して Stream Analytics のジョブを作成する
TollApp イベント ジェネレーターがデプロイされたリソース グループがある場所を探します。
Azure Event Hubs 名前空間を選択します。 別のタブまたはウィンドウで開くことができます。
[Event Hubs 名前空間] ページで、左側のメニューの [エンティティ] の下にある [Event Hubs] を選択します。
entrystreamインスタンスを選択します。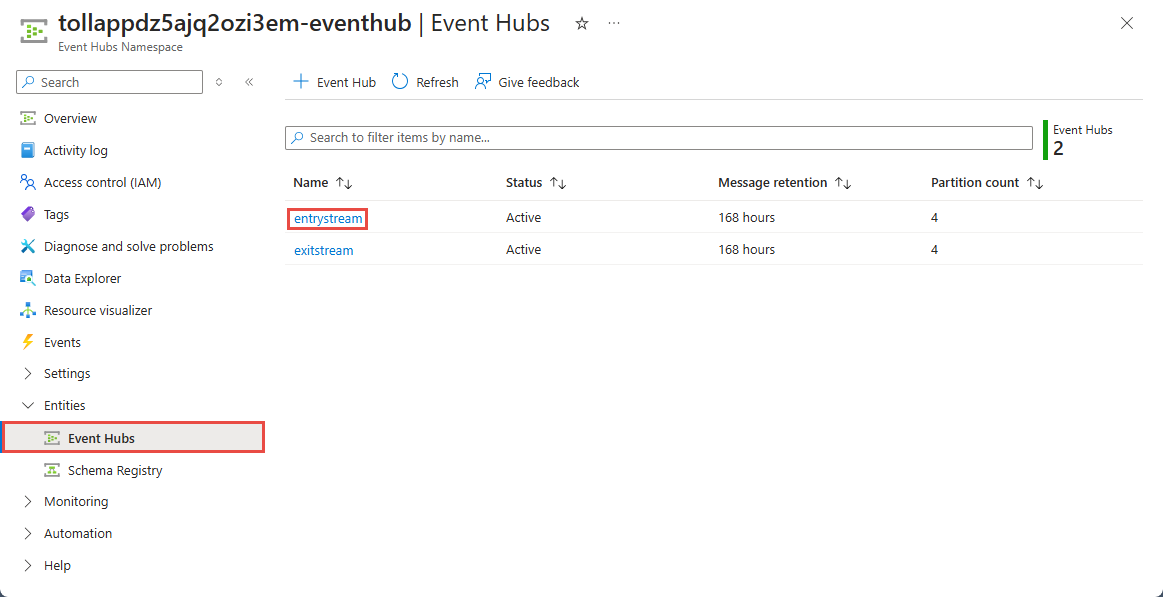
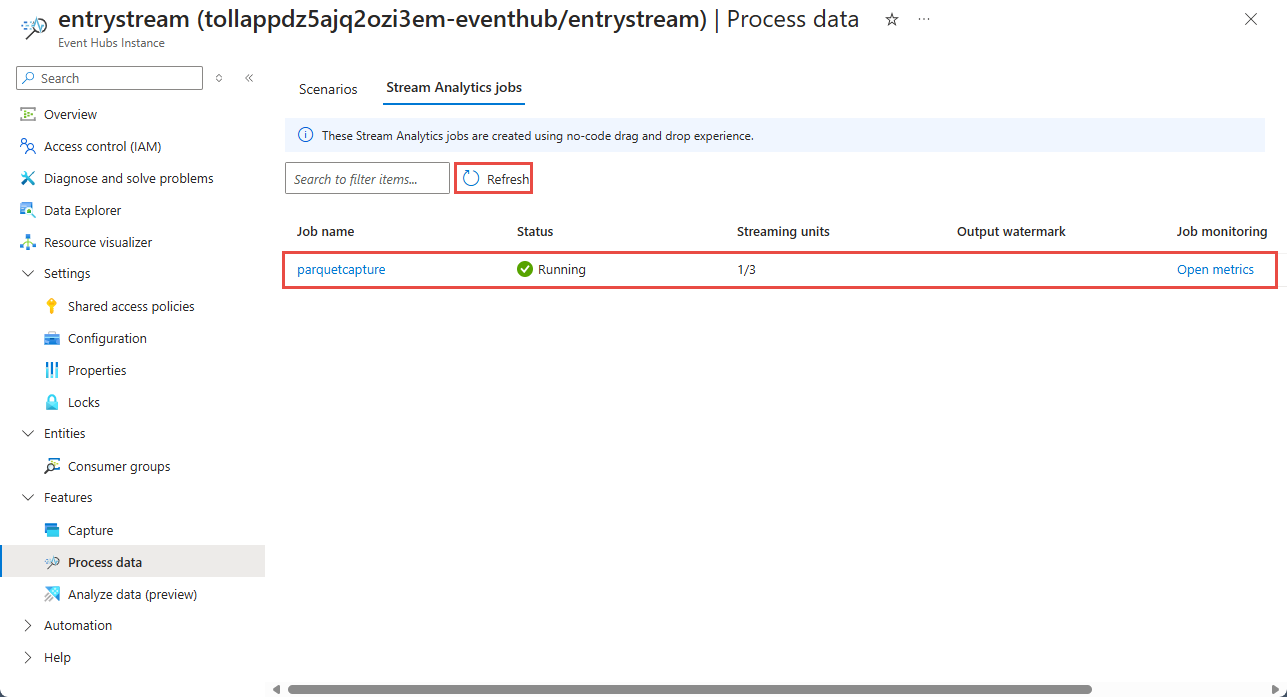
[Event Hubs のインスタンス] ページで、左側のメニューの [機能] セクションで [データの処理] を選択します。
[Capture data to ADLS Gen2 in Parquet format] (ADLS Gen2 へのデータを Parquet 形式でキャプチャする) タイルの [開始] を選択します。
![[データを Parquet 形式で ADLS Gen2 にキャプチャする] タイルの選択を示すスクリーンショット。](media/stream-analytics-no-code/parquet-capture-start.png)
ジョブに
parquetcaptureという名前を付け、[作成] を選択します。![[新しい Stream Analytics ジョブ] ページのスクリーンショット。](media/stream-analytics-no-code/new-stream-analytics-job.png)
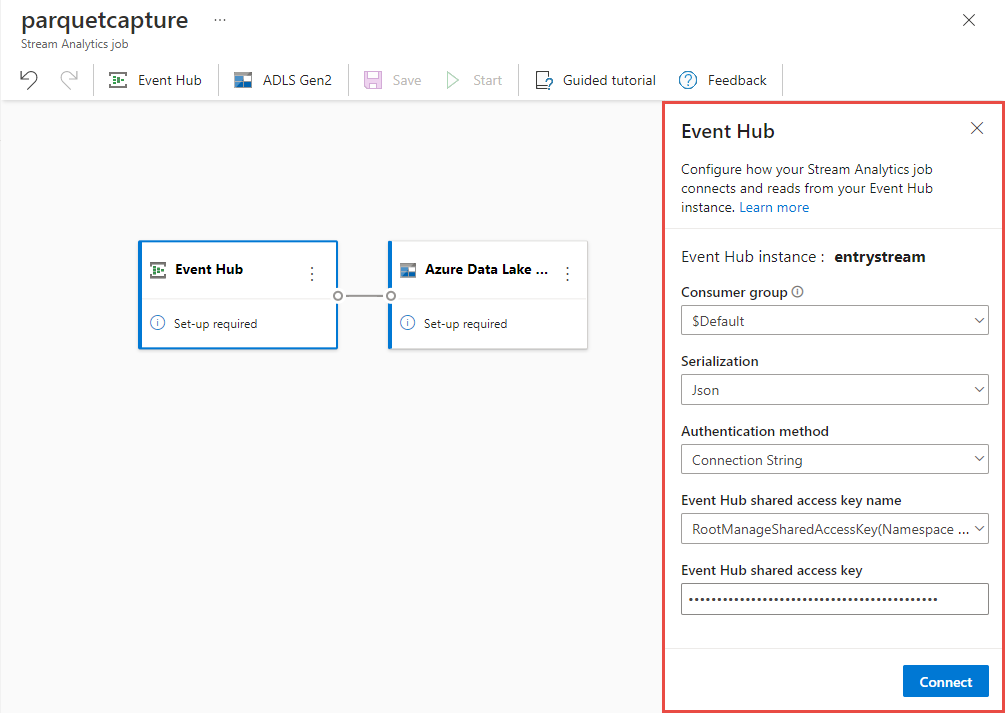
[イベント ハブ] 構成ページで、次の手順に従います。
[コンシューマー グループ] で、[既存のものを使用] を選択します。
$Defaultコンシューマー グループが選択されていることを確認します。[シリアル化] が JSON に設定されていることを確認します。
[認証方法] が [接続文字列] に設定されていることを確認します。
[イベント ハブの共有アクセス キー名] が [RootManageSharedAccessKey] に設定されていることを確認します。
ウィンドウの下部にある [接続] を選択します。
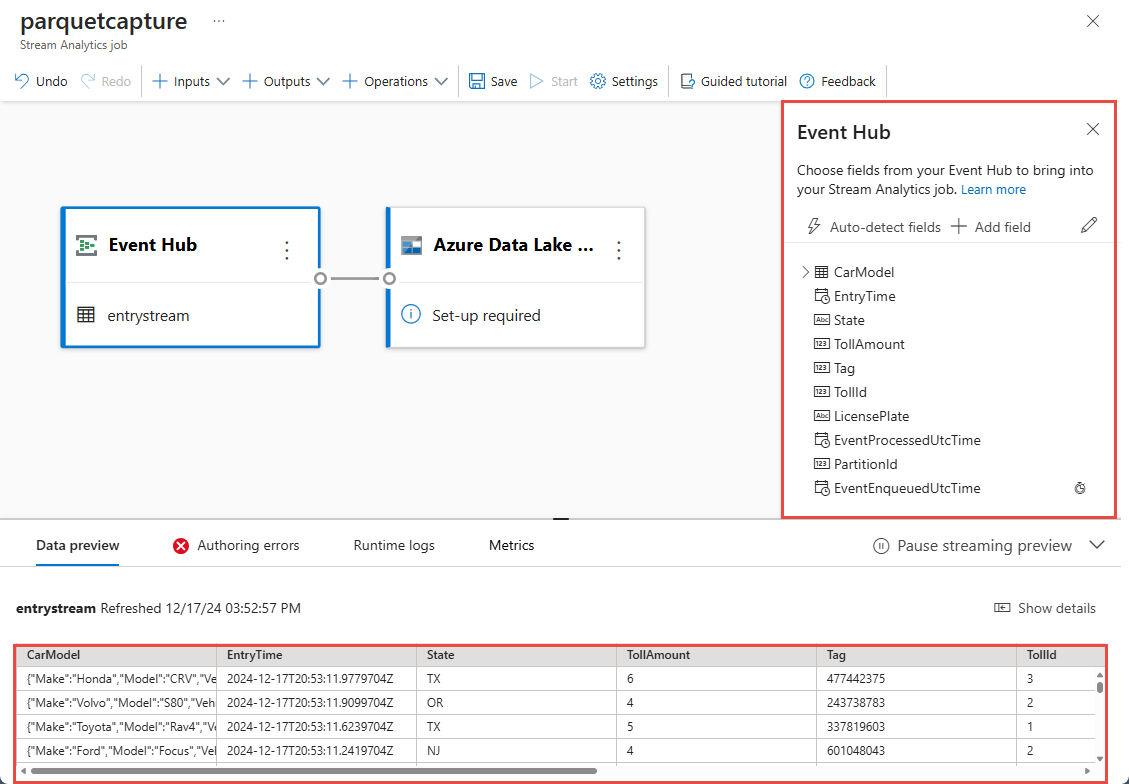
数秒以内に、サンプルの入力データとそのスキーマが表示されます。 フィールドの削除、フィールド名の変更、データ型の変更を実行することもできます。
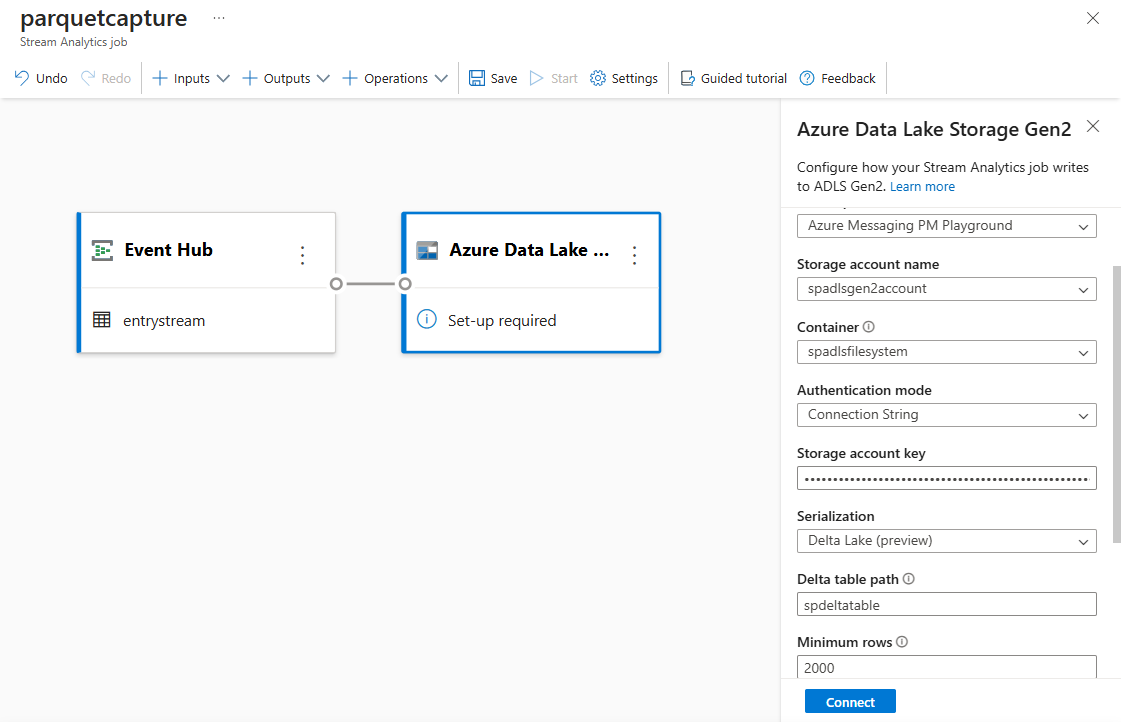
キャンバス上の[Azure Data Lake Storage Gen2] タイルを選択し、次を指定して構成します。
Azure Data Lake Gen2 アカウントが配置されているサブスクリプション
ストレージ アカウント名。これは、「前提条件」セクションで行われた Azure Synapse Analytics ワークスペースで使用されたのと同じ ADLS Gen2 アカウントである必要があります。
Parquet ファイルが作成されるコンテナー。
[Delta テーブルのパス] で、テーブルの名前を指定します。
既定の yyyy-mm-dd および HH としての日付と時刻のパターン。
[接続] を選択します
上部のリボンで [保存] を選択してジョブを保存し、[開始] を選択してジョブを実行します。 ジョブが開始されたら、右上隅にある [X] を選択して [Stream Analytics ジョブ] ページを閉じます。
![[Stream Analytics ジョブの開始] ページを示すスクリーンショット。](media/event-hubs-parquet-capture-tutorial/start-job.png)
これで、ノー コード エディターを使用して作成されたすべての Stream Analytics ジョブの一覧が表示されます。 そして 2 分以内に、ジョブは [実行中] の状態になります。 ページの [最新の情報に更新] ボタンを選択すると、状態が [作成済み] -> [開始] -> [実行中] に変わります。

![[データを Parquet 形式で ADLS Gen2 にキャプチャする] タイルの選択を示すスクリーンショット。](media/stream-analytics-no-code/parquet-capture-start.png#lightbox)
![[新しい Stream Analytics ジョブ] ページのスクリーンショット。](media/stream-analytics-no-code/new-stream-analytics-job.png#lightbox)



![[Stream Analytics ジョブの開始] ページを示すスクリーンショット。](media/event-hubs-parquet-capture-tutorial/start-job.png#lightbox)

Azure Data Lake Storage Gen 2 アカウントの出力を表示する
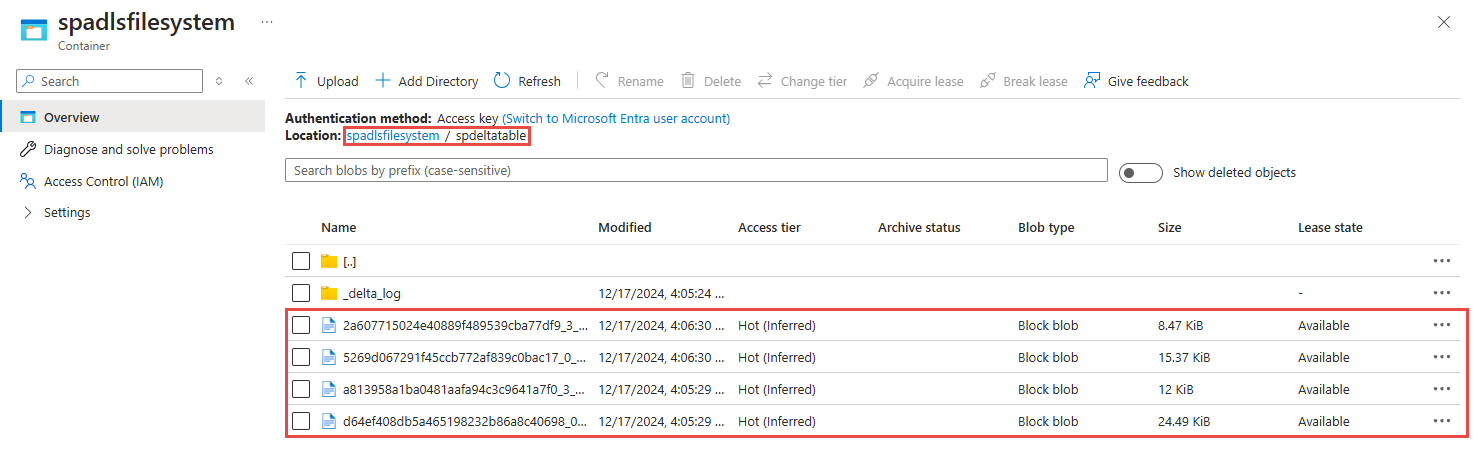
前の手順で使用した Azure Data Lake Storage Gen2 アカウントを見つけます。
前の手順で使用したコンテナーを選択します。 先ほど指定したフォルダーに作成された Parquet ファイルが表示されます。

Azure Synapse Analytics を使用してキャプチャしたデータに Parquet 形式でクエリを実行する
Azure Synapse Spark を使用してクエリを実行する
Azure Synapse Analytics ワークスペースを見つけて、Synapse Studio を開きます。
まだ存在しない場合は、ワークスペースにサーバーレス Apache Spark プールを作成します。
Synapse Studio で [開発] ハブに移動し、新しい Notebook を作成します。
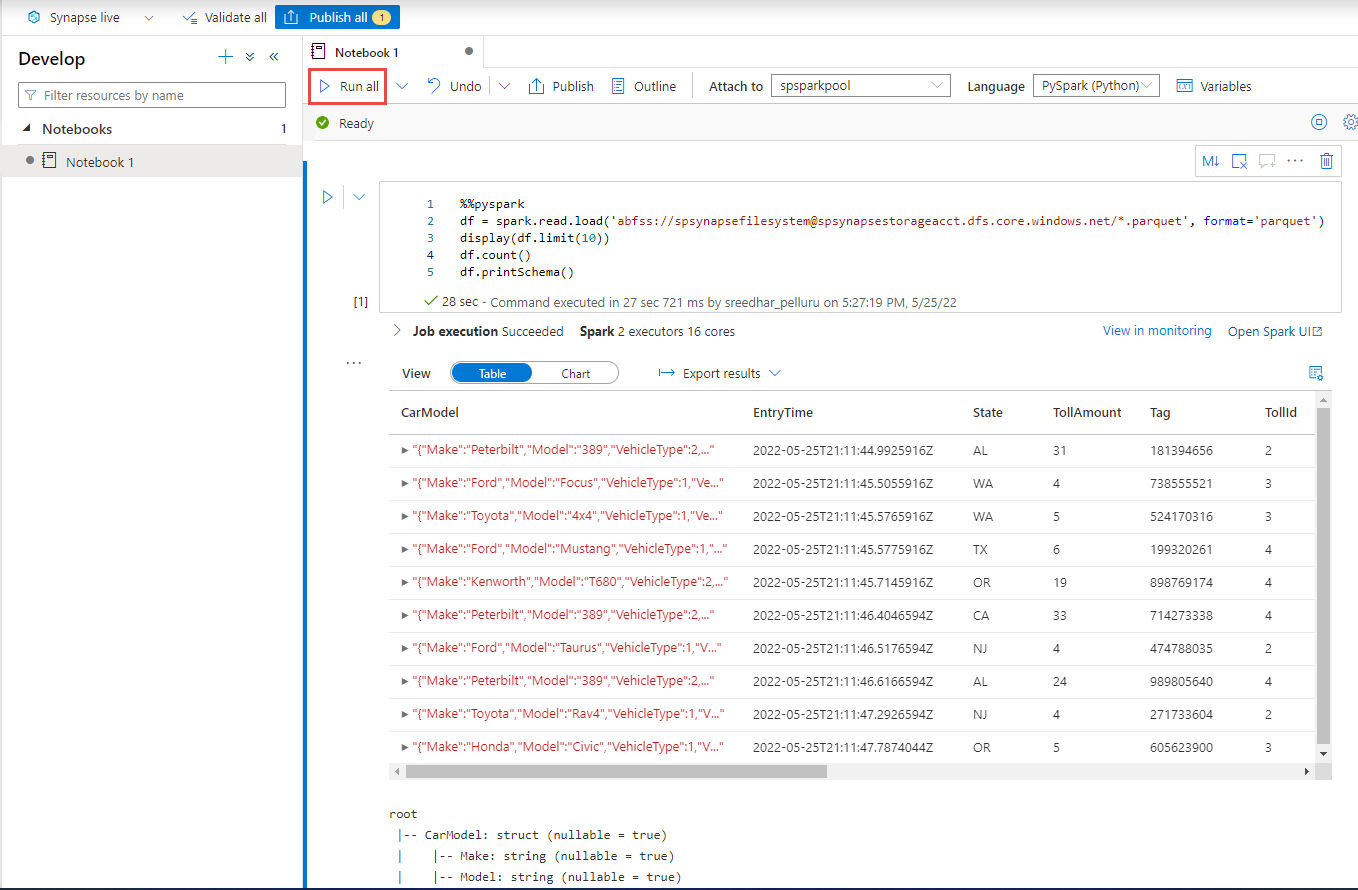
新しいコード セルを作成し、以下のコードをそのセルに貼り付けます。 container と adlsname を、前の手順で使用したコンテナーと ADLS Gen2 アカウントの名前に置き換えます。
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()ツール バーの [アタッチ先] で、ドロップダウン リストから Spark プールを選択します。
[すべて実行] を選択して結果を確認します。

Azure Synapse サーバーレス SQLを使用したクエリ
[開発] ハブで、新しいSQL スクリプトを作成します。
次のスクリプトを貼り付け、組み込みのサーバーレス SQL エンドポイントを使用して実行します。 container と adlsname を、前の手順で使用したコンテナーと ADLS Gen2 アカウントの名前に置き換えます。
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*.parquet', FORMAT='PARQUET' ) AS [result]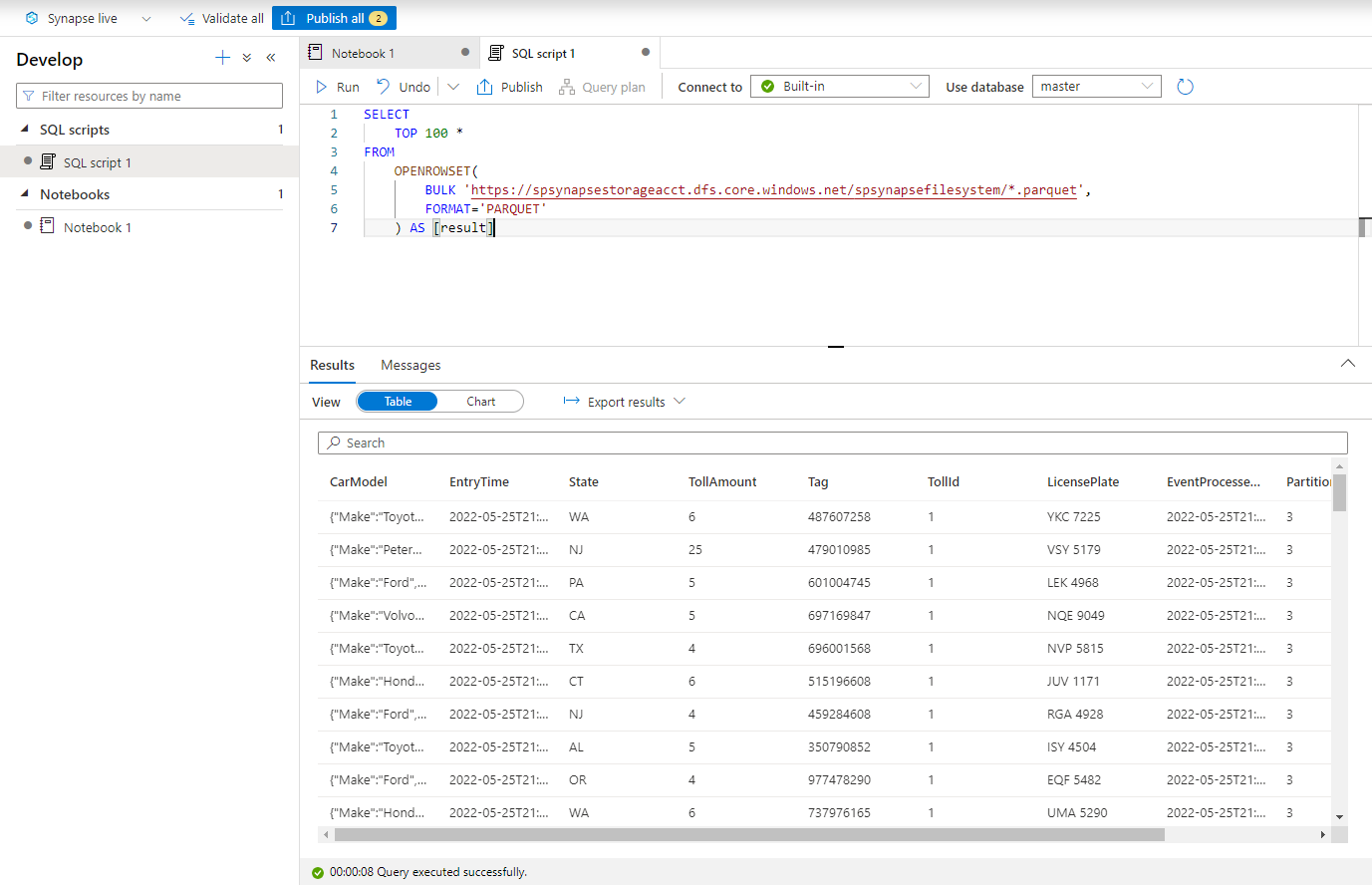

リソースをクリーンアップする
- Event Hubs のインスタンスの場所を探し、[データの処理] セクションの Stream Analytics ジョブの一覧を確認します。 実行中のジョブをすべて停止します。
- TollApp イベント ジェネレーターのデプロイ時に使用したリソース グループに移動します。
- [リソース グループの削除] を選択します。 リソース グループの名前を入力して削除することを確認します。
次のステップ
このチュートリアルでは、ノー コード エディターを使用して Stream Analytics ジョブを作成し、Event Hubs データ ストリームを Parquet 形式でキャプチャする方法について説明しました。 その後、Azure Synapse Analytics を使用して、Synapse Spark と Synapse SQL の両方を使用して Parquet ファイルのクエリを実行しました。