AKS 上の Azure HDInsight で Apache Spark™ クラスターを使用して Delta Lake を使用する (プレビュー)
Note
Azure HDInsight on AKS は 2025 年 1 月 31 日に廃止されます。 2025 年 1 月 31 日より前に、ワークロードを Microsoft Fabric または同等の Azure 製品に移行することで、ワークロードの突然の終了を回避する必要があります。 サブスクリプション上に残っているクラスターは停止され、ホストから削除されることになります。
提供終了日までは基本サポートのみが利用できます。
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加の使用条件」に記載されています。 この特定のプレビューについては、「Microsoft HDInsight on AKS のプレビュー情報」を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新情報については、Azure HDInsight コミュニティのフォローをお願いいたします。
Azure HDInsight on AKS は、組織が大量のデータを処理するのに役立つビッグ データ分析用のマネージド クラウドベースのサービスです。 このチュートリアルでは、AKS 上の Azure HDInsight で Apache Spark™ クラスターを使用して Delta Lake を使用する方法について説明します。
前提条件
AKS 上の Azure HDInsight での Apache Spark™ クラスターの作成
Jupyter Notebook で Delta Lake シナリオを実行します。 以下に Scala での例が示されているため、ノートブックの作成時には Jupyter Notebook を作成し、[Spark] を選択してください。



シナリオ
- NYC タクシーの Parquet データ形式を読み取ります - Parquet ファイルの URL の一覧は、NYC Taxi & Limousine Commission で提供されています。
- URL (ファイル) ごとに、変換を実行し、Delta 形式で格納します。
- 増分読み込みを使用して、Delta テーブルから平均距離、平均コスト (1 マイルあたり)、平均コストを計算します。
- 手順 3 で計算した Delta 形式の値を、KPI 出力フォルダーに格納します。
- Delta 形式の出力フォルダーで Delta テーブルを作成します (自動更新)。
- KPI 出力フォルダーには、乗車について平均距離と 1 マイルあたりの平均コストの複数のバージョンが含まれます。
Delta Lake の必須構成を指定する
Delta Lake と Apache Spark 互換性マトリックス - Delta Lake。Apache Spark バージョンに基づいて Delta Lake バージョンを変更します。
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

データ ファイルを一覧表示する
Note
これらのファイルの URL は、NYC Taxi & Limousine Commission からのものです。
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

出力ディレクトリを作成する
Delta 形式の出力を作成する場所。必要に応じて、transformDeltaOutputPath および avgDeltaOutputKPIPath 変数を変更します。
avgDeltaOutputKPIPath- Delta 形式の平均 KPI を格納しますtransformDeltaOutputPath- Delta 形式の変換済み出力を格納します
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Parquet 形式から Delta 形式のデータを作成する
https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page からダウンロードされたデータがある
listOfDataFileから、入力データを取得しますタイム トラベルおよびバージョンを示すには、データを個別に読み込みます
増分読み込み時に、変換を実行し、次のビジネス KPI を計算します。
- 平均距離
- 平均コスト (1 マイルあたり)
- 平均コスト
Delta 形式の変換済みおよび KPI のデータを保存します
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Delta テーブルを使用して Delta 形式を読み取ります
- 変換済みデータの読み取り
- KPI データの読み取り
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
印刷スキーマ
- 変換済みおよび平均 KPI データ 1 の Delta テーブル スキーマを出力します。
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema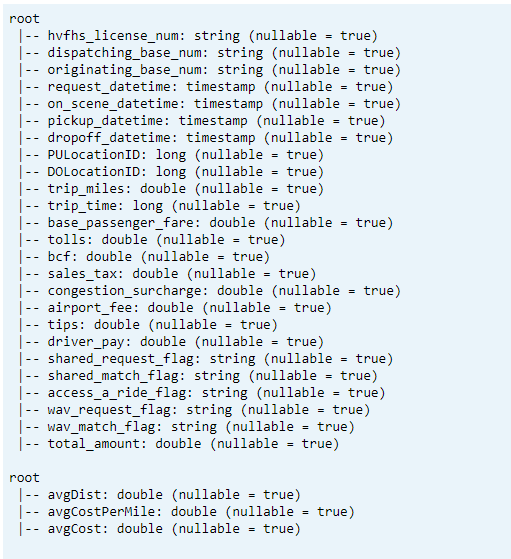
データ テーブルから最後に計算された KPI を表示します
dtAvgKpi.toDF.show(false)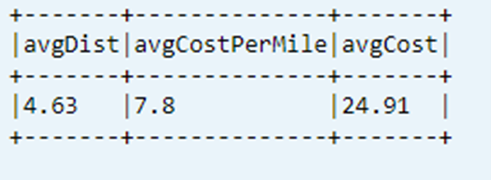


計算済み KPI 履歴を表示する
この手順では、_delta_log からの KPI トランザクション テーブルの履歴を表示します
dtAvgKpi.history().show(false)

各データの読み込み後に KPI データを表示する
- タイム トラベルを使用すると、各読み込み後に KPI の変更を表示できます
- すべてのバージョンの変更を CSV 形式で
avgMoMKPIChangePathに格納することができます。これにより、Power BI でそれらの変更を読み取ることができるようになります
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

リファレンス
- Apache、Apache Spark、Spark、および関連するオープン ソース プロジェクト名は、Apache Software Foundation (ASF) の商標です。