HDInsight on AKS 上の Apache Flink® を使用した Azure Pipelines の使用方法
Note
Azure HDInsight on AKS は 2025 年 1 月 31 日に廃止されます。 2025 年 1 月 31 日より前に、ワークロードを Microsoft Fabric または同等の Azure 製品に移行することで、ワークロードの突然の終了を回避する必要があります。 サブスクリプション上に残っているクラスターは停止され、ホストから削除されることになります。
提供終了日までは基本サポートのみが利用できます。
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加の使用条件」に記載されています。 この特定のプレビューについては、「Microsoft HDInsight on AKS のプレビュー情報」を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新情報については、Azure HDInsight コミュニティのフォローをお願いいたします。
この記事では、HDInsight on AKS で Azure Pipelines を使用して、クラスターの REST API で Flink ジョブを送信する方法について説明します。 サンプルの YAML パイプラインと PowerShell スクリプトを使用したプロセスについて説明します。これらはどちらも REST API の操作の自動化を効率化します。
前提条件
Azure のサブスクリプション。 Azure サブスクリプションを持っていない場合は、無料アカウントを作成してください。
リポジトリを作成できる GitHub アカウント。 無料で作成できます。
.pipelineディレクトリを作成し、flink-azure-pipelines.yml および flink-job-azure-pipeline.ps1 をコピーしますAzure DevOps 組織。 無料で作成できます。 チームに既にある場合は、使用する Azure DevOps プロジェクトの管理者であることを確認します。
Microsoft によってホストされるエージェントでパイプラインを実行する機能。 Microsoft ホステッド エージェントを使用するには、Azure DevOps 組織が Microsoft ホステッド並列ジョブにアクセスできる必要があります。 並列ジョブを購入するか、無料の許可を要求することができます。
Flink クラスター。 持っていない場合は、HDInsight on AKS で Flink クラスターを作成します。
ジョブ jar をコピーするために、クラスター ストレージ アカウントに 1 つのディレクトリを作成します。 このディレクトリは後で、パイプライン YAML でジョブ jar の場所 (<JOB_JAR_STORAGE_PATH>) を構成する必要があります。
パイプラインを設定する手順
Azure Pipelines のサービス プリンシパルを作成する
Azure にアクセスするための Microsoft Entra サービス プリンシパルを作成します。“共同作成者” ロールを使用して HDInsight on AKS クラスターにアクセスするためのアクセス許可を付与し、応答から appId、password、tenant を書き留めます。
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
例:
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
リファレンス
Note
Apache、Apache Flink、Flink、関連するオープン ソース プロジェクト名は、Apache Software Foundation (ASF) の商標です。
Key Vault を作成します
Azure Key Vault を作成します。このチュートリアルに従って、新しい Azure Key Vault を作成できます。
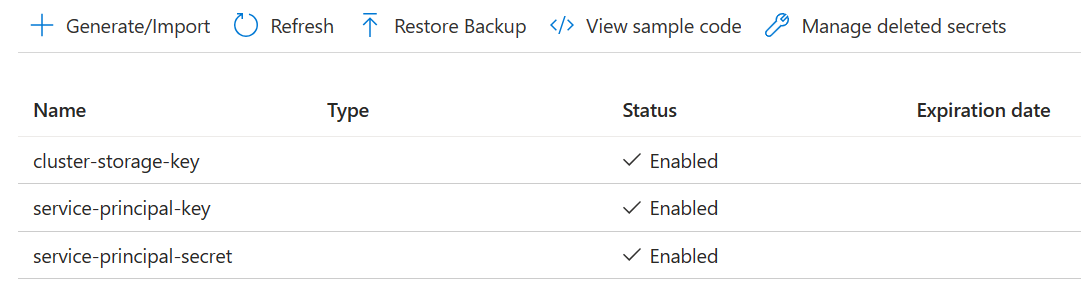
3 つのシークレットを作成します
ストレージ キーのための cluster-storage-key。
プリンシパル clientId または appId のための service-principal-key。
プリンシパル シークレットのための service-principal-secret。
"キー コンテナー シークレット責任者" ロールを使用して Azure Key Vault にアクセスするためのアクセス許可をサービス プリンシパルに付与します。

パイプラインを設定する
プロジェクトに移動し、[プロジェクトの設定] をクリックします。
下にスクロールし、[サービス接続]、[新しいサービス接続] の順に選択します。
[Azure Resource Manager] を選択します。
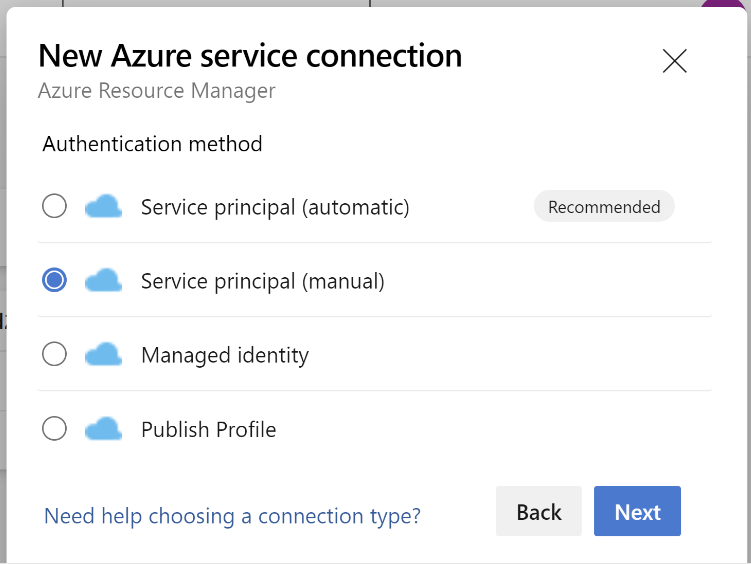
認証方法で、[サービス プリンシパル (手動)] を選択します。
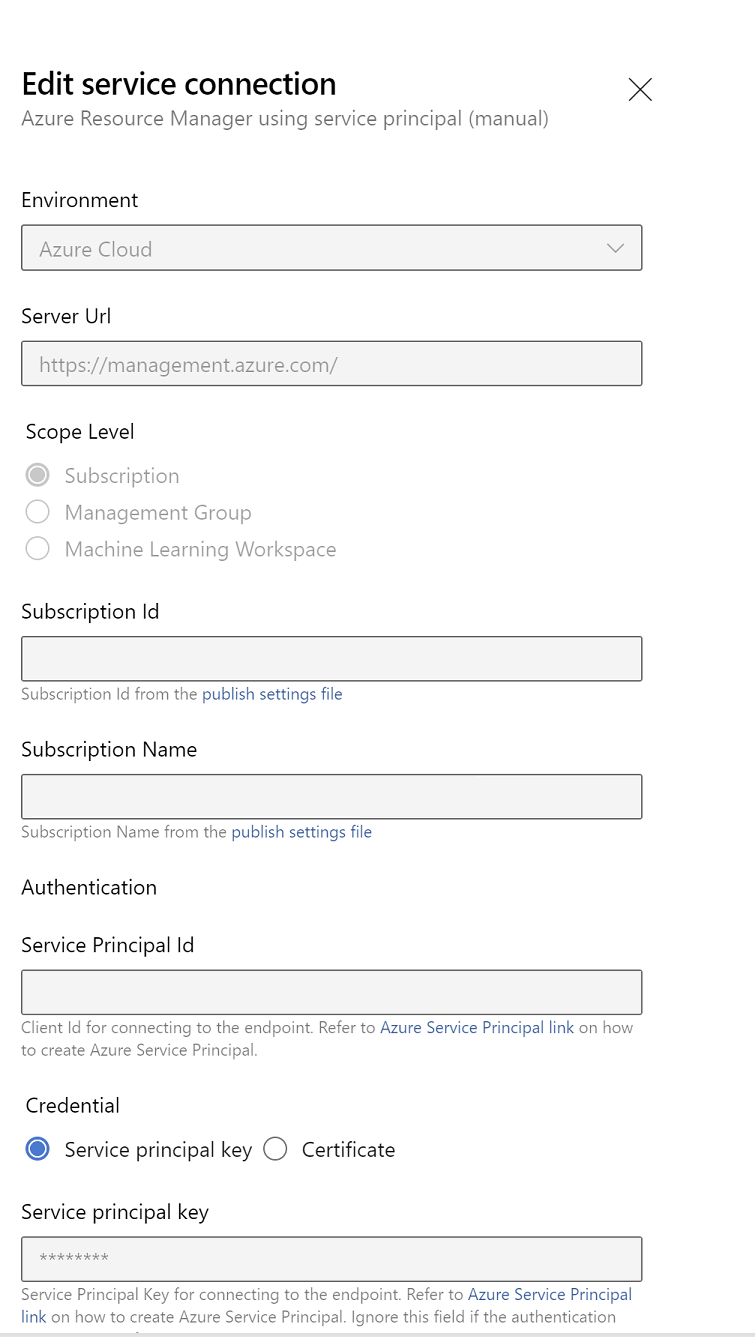
サービス接続のプロパティを編集します。 最近作成したサービス プリンシパルを選択します。
[確認] をクリックして、接続が正しく設定されているかどうかを確認します。 次のエラーが発生することがあります。

この場合、閲覧者ロールをサブスクリプションに割り当てる必要があります。
その後、検証が成功するはずです。
サービス接続を保存します。

パイプラインに移動し、[新しいパイプライン] をクリックします。
コードの場所として [GitHub] を選択します。
リポジトリを選択します。 GitHub でリポジトリを作成する方法を参照してください。 select-github-repo イメージ。
リポジトリを選択します。 詳細については、GitHub でリポジトリを作成する方法を参照してください。
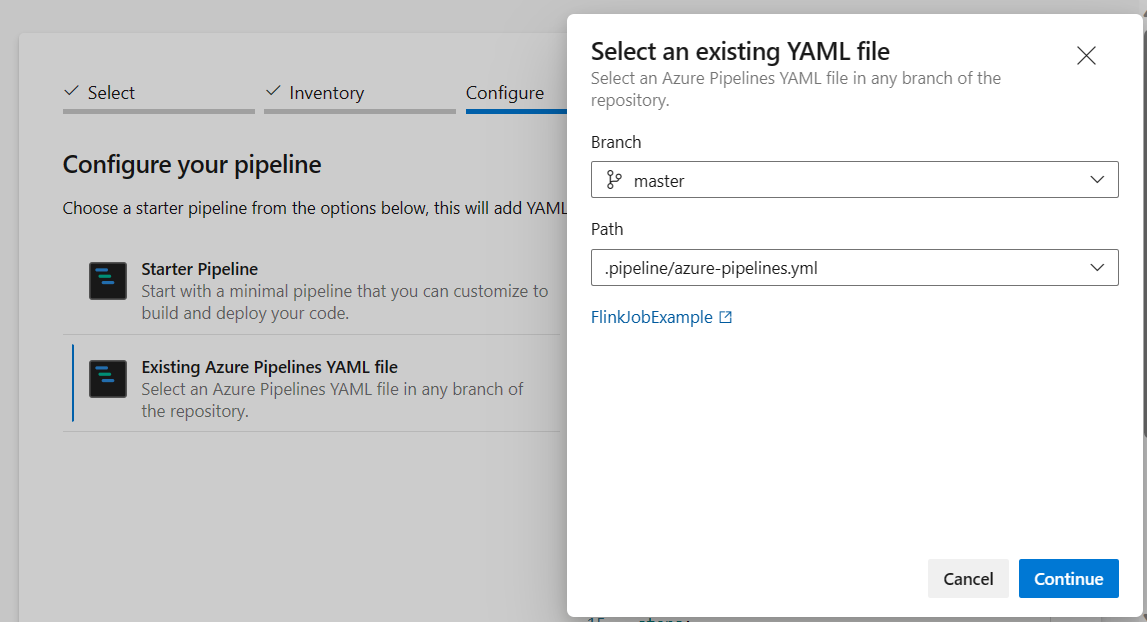
[パイプラインを構成する] オプションで、[既存の Azure Pipelines YAML ファイル] を選択できます。 先ほどコピーしたブランチとパイプライン スクリプトを選択します。 (.pipeline/flink-azure-pipelines.yml)
変数セクションの値を置き換えます。

要件に基づいてコード ビルド セクションを修正し、ジョブ jar ローカル パスについて変数セクションの <JOB_JAR_LOCAL_PATH> を構成します。
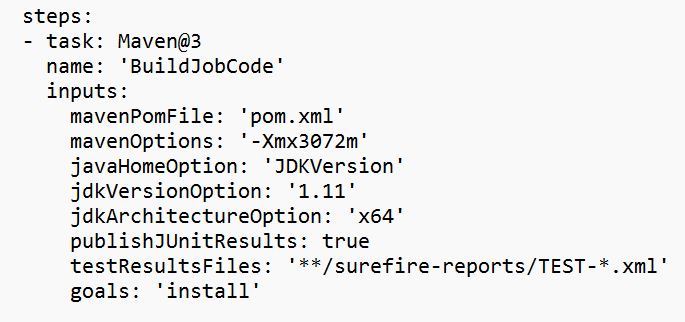
パイプライン変数 "action" を追加し、値 "RUN" を構成します。
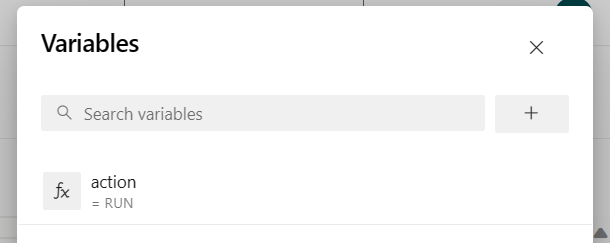
パイプラインを実行する前に変数の値を変更できます。
NEW: この値は既定値です。 これは新しいジョブを起動し、ジョブが既に実行されている場合は、実行中のジョブを最新の jar で更新します。
SAVEPOINT: この値は、実行中のジョブのセーブ ポイントを受け取ります。
DELETE: 実行中のジョブを取り消すか削除します。
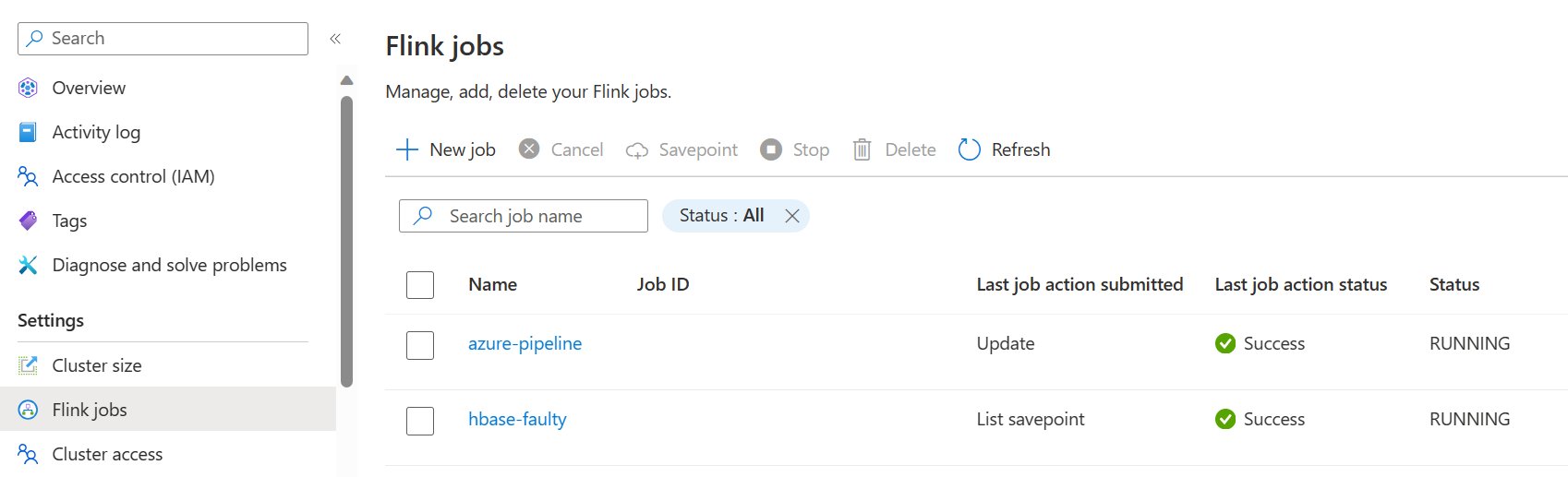
パイプラインを保存し、実行します。 ポータルの Flink ジョブ セクションで、実行中のジョブを確認できます。








Note
これは、パイプラインを使用してジョブを送信するための 1 つのサンプルです。 Flink REST API ドキュメントに従って、ジョブを送信する独自のコードを作成することができます。