AKS 上の Azure HDInsight の Apache Flink® とは (プレビュー)
大事な
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 このお知らせ でについて詳しく学んでください。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
大事な
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案については、詳細を記載した要求を AskHDInsight に送信してください。また、更新情報を入手するために Azure HDInsight Community をフォローしてください。
Apache Flink は、バインドされていないデータ ストリームと有界データ ストリームに対するステートフルな計算のためのフレームワークおよび分散処理エンジンです。 Flink は、すべての一般的なクラスター環境で実行し、計算とステートフル ストリーミング アプリケーションをメモリ内の速度と任意の規模で実行するように設計されています。 アプリケーションは、クラスターで分散され、同時に実行される数千のタスクに並列化されます。 そのため、アプリケーションは無制限の量の vCPU、メイン メモリ、ディスク、およびネットワーク IO を使用できます。 さらに、Flinkは大きなアプリケーション状態を簡単に維持します。 非同期および増分チェックポイント アルゴリズムにより、処理の待機時間への影響を最小限に抑えながら、正確に 1 回の状態の整合性を保証します。
Apache Flink は、ストリーム処理用の非常にスケーラブルな分析エンジンです。
Flink が提供する主な機能の一部は次のとおりです。
- バインドされたストリームとバインドされていないストリームに対する操作
- メモリ内のパフォーマンス
- ストリーミングとバッチ計算の両方の機能
- 待機時間が短く、スループットが高い操作
- 1 回だけ処理する
- 高可用性
- 状態と障害許容
- Hadoop エコシステムと完全に互換性がある
- ストリームとバッチの両方の統合 SQL API
Flink アーキテクチャ図 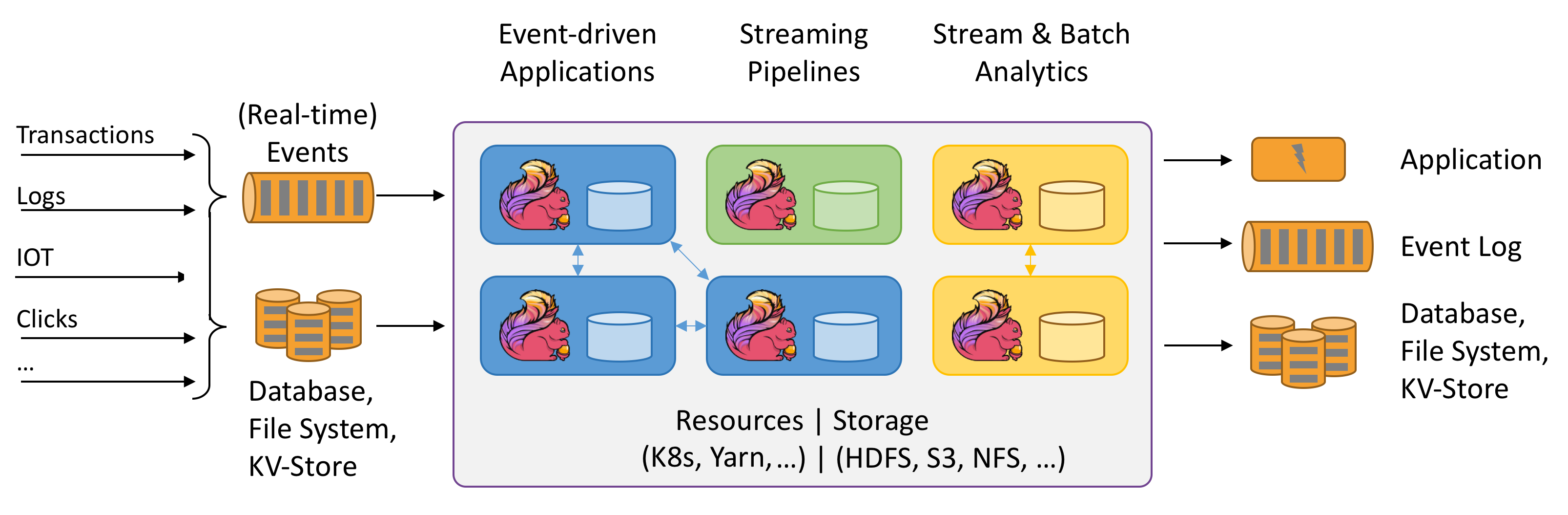
Apache Flink の理由
Apache Flink は、豊富な機能セットにより、さまざまな種類のアプリケーションを開発して実行するための優れた選択肢です。 Flink の機能には、ストリームとバッチ処理のサポート、高度な状態管理、イベント時処理セマンティクス、および状態に対する厳密に 1 回の整合性保証が含まれます。 Flink には単一障害点がありません。 Flink は、数千のコアとテラバイトのアプリケーション状態にスケーリングし、高スループットと低待機時間を実現し、世界で最も要求の厳しいストリーム処理アプリケーションの一部に電力を供給することが実証されています。
- 不正検出: Flink を使用すると、ストリーミング データに複雑なルールと機械学習モデルを適用することで、不正なトランザクションやアクティビティをリアルタイムで検出できます。
- 異常検出: Flink を使用して、センサーの読み取り値、ネットワーク トラフィック、ユーザーの動作など、ストリーミング データの外れ値や異常なパターンを特定できます。
- ルールベースのアラート: Flink を使用して、温度、圧力、株価などのストリーミング データの定義済みの条件またはしきい値に基づいてアラートまたは通知をトリガーできます。
- ビジネス プロセス監視: Flink を使用して、注文フルフィルメント、配送、顧客サービスなど、ビジネス プロセスまたはワークフローの状態とパフォーマンスをリアルタイムで追跡および分析できます。
- Web アプリケーション (ソーシャル ネットワーク): Flink を使用すると、メッセージ、いいね、コメント、推奨事項など、ユーザーが生成したデータをリアルタイムで処理する必要がある Web アプリケーションを活用できます。
Apache Flink ユース ケース で説明されている一般的なユース ケースの詳細を参照してください
AKS 上の HDInsight の Apache Flink クラスターは、フル マネージド サービスです。 AKS 上の HDInsight で Flink クラスターを作成する利点を次に示します。
| 特徴 | 説明 |
|---|---|
| 簡単作成 | Azure portal、Azure PowerShell、または SDK を使用して、HDInsight に新しい Flink クラスターを数分で作成できます。 HDInsight の Apache Flink クラスターを AKS 上で使用開始する方法については、を参照し、を参照してください。 |
| 使いやすさ | AKS 上の HDInsight の Flink クラスターには、ポータル ベースの構成管理とスケーリングが含まれます。 ジョブ管理 API に加えて、ジョブ管理には REST API または Azure portal を使用します。 |
| REST API | AKS 上の HDInsight の Flink クラスターには、ジョブ管理 API 、Azure portal でジョブをリモートで送信および監視するための REST API ベースの Flink ジョブ送信方法が含まれます。 |
| 展開の種類 | Flink は、セッション モードまたはアプリケーション モードでアプリケーションを実行できます。 現在、AKS 上の HDInsight ではセッション クラスターのみがサポートされています。 セッション クラスターで複数の Flink ジョブを実行できます。 アプリ モードは、AKS クラスター上の HDInsight のロードマップにあります |
| Metastore のサポート | AKS 上の HDInsight の Flink クラスターでは、Azure Data Lake Storage Gen2 へのリモート チェックポイントを使用して、さまざまな開いているファイル形式で Hive Metastore を使用するカタログをサポートできます。 |
| Azure Storage のサポート | HDInsight の Flink クラスターでは、Azure Data Lake Storage Gen2 をファイル シンクとして使用できます。 Data Lake Storage Gen2 の詳細については、「Azure Data Lake Storage Gen2」を参照してください。 |
| Azure サービスとの統合 | AKS 上の HDInsight の Flink クラスターには、Azure Event Hubs と Azure HDInsight Kafka との統合が付属しています。 Event Hubs または HDInsight を使用してストリーミング アプリケーションを構築できます。 |
| 適応性 | AKS 上の HDInsight を使用すると、自動スケール機能を使用してスケジュールに基づいて Flink クラスター ノードをスケーリングできます。 AKS クラスターで Azure HDInsight を自動的にスケーリングする方法に関するページを参照してください。 |
| ステートバックエンド | AKS 上の HDInsight では、既定の StateBackend として RocksDB が使用されます。 RocksDB は、高速ストレージ用の埋め込み可能な永続的なキー値ストアです。 |
| チェックポイント | チェックポイント処理は、AKS クラスターの HDInsight で既定で有効になっています。 AKS 上の HDInsight の既定の設定では、永続的ストレージ内の最後の 5 つのチェックポイントが維持されます。 ジョブが失敗した場合は、最新のチェックポイントからジョブを再開できます。 |
| 増分チェックポイント | RocksDB では、増分チェックポイントがサポートされています。 大規模な状態には増分チェックポイントを使用することをお勧めします。この機能を手動で有効にする必要があります。
flink-conf.yaml: state.backend.incremental: true で既定値を設定すると、アプリケーションがコード内のこの設定をオーバーライドしない限り、増分チェックポイントが有効になります。 このステートメントは既定で true です。 または、コードでこの値を直接構成することもできます (構成の既定値をオーバーライドします)。EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true);。 既定では、構成されたチェックポイント ディレクトリ内の最後の 5 つのチェックポイントが保持されます。 この値は、構成管理セクションの構成を変更することで変更できます state.checkpoints.num-retained: 5 |
AKS 上の HDInsight の Apache Flink クラスターには次のコンポーネントが含まれています。これらのコンポーネントは、既定でクラスターで使用できます。
何が近日公開されるのかは、ロードマップ を参照してください。
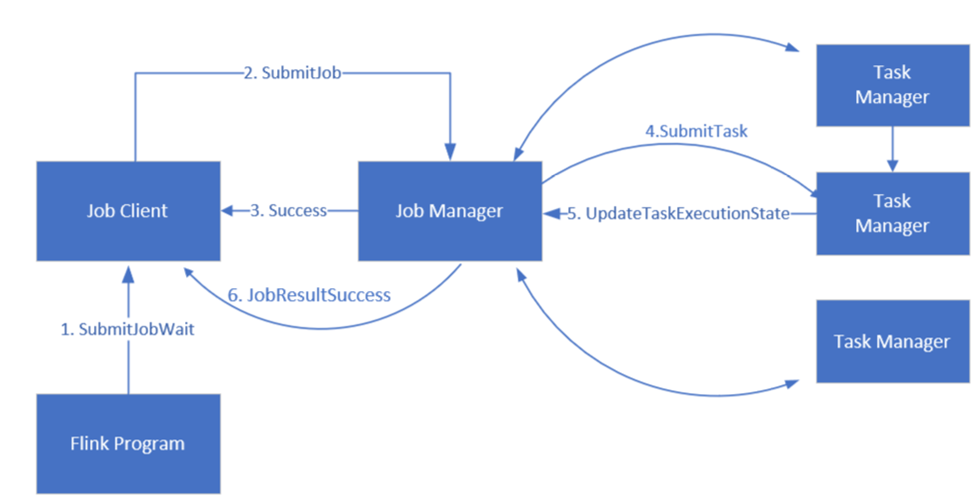
Apache Flink ジョブ管理
Flink は、ジョブ マネージャー、タスク マネージャー、ジョブ クライアントの 3 つの分散コンポーネントを使用してジョブをスケジュールします。このコンポーネントは、Leader-Follower パターンで設定されます。
Flink ジョブ: Flink ジョブまたはプログラムは、複数のタスクで構成されます。 タスクは Flink での基本的な実行単位です。 各 Flink タスクには並列処理のレベルに応じて複数のインスタンスがあり、各インスタンスは TaskManager で実行されます。
ジョブ マネージャー: ジョブ マネージャーはスケジューラとして機能し、タスク マネージャーのタスクをスケジュールします。
タスク マネージャー: タスク マネージャーには、タスクを並列で実行するためのスロットが 1 つ以上付属しています。
ジョブ クライアント: ジョブ クライアントがジョブ マネージャーと通信して Flink ジョブを送信する
Flink Web UI: Flink は、実行中のアプリケーションを検査、監視、デバッグするための Web UI を備えています。
参考
- Apache Flink ウェブサイト
- Apache、Apache Kafka、Kafka、Apache Flink、Flink、および関連するオープンソースプロジェクトの名称は、Apache Software Foundation (ASF) の商標 です。