Azure Data Factory Workflow Orchestration Manager を使用した Apache Flink® ジョブ オーケストレーション (Apache Airflow を利用)
Note
Azure HDInsight on AKS は 2025 年 1 月 31 日に廃止されます。 2025 年 1 月 31 日より前に、ワークロードを Microsoft Fabric または同等の Azure 製品に移行することで、ワークロードの突然の終了を回避する必要があります。 サブスクリプション上に残っているクラスターは停止され、ホストから削除されることになります。
提供終了日までは基本サポートのみが利用できます。
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加の使用条件」に記載されています。 この特定のプレビューについては、「Microsoft HDInsight on AKS のプレビュー情報」を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新情報については、Azure HDInsight コミュニティのフォローをお願いいたします。
この記事では、Azure REST API を使用した Flink ジョブの管理と、Azure Data Factory Workflow Orchestration Manager を使用したオーケストレーション データ パイプラインについて説明します。 Azure Data Factory Workflow Orchestration Manager サービスは、Apache Airflow 環境を作成および管理するためのシンプルで効率的な方法であり、データ パイプラインの簡単な大規模な実行を可能にします。
Apache Airflow は、複雑なデータ ワークフローをプログラムで作成、スケジュール、監視するオープンソース プラットフォームです。 これにより、オペレーターと呼ばれる一連のタスクを定義でき、有向非循環グラフ (DAG) と組み合わせてデータ パイプラインを表すことができます。
次の図は、Azure での Airflow、Key Vault、HDInsight on AKS の配置を示しています。

必要なアクセスを制限し、クライアント資格情報のライフ サイクルを個別に管理するために、スコープに基づいて複数の Azure サービス プリンシパルが作成されます。
アクセス キーまたはシークレットを定期的にローテーションすることをお勧めします。
設定手順
Flink Job jar をストレージ アカウントにアップロードします。 Flink クラスターに関連付けられているプライマリ ストレージ アカウントまたは他のストレージ アカウントを使用できます。このストレージ アカウントには、クラスターに使用されるユーザー割り当て MSI への “ストレージ BLOB データ所有者”ロールを割り当てる必要があります。
Azure Key Vault - 所有していない場合は、このチュートリアルに従って新しい Azure Key Vault を作成できます。
Key Vault にアクセスするための Microsoft Entra サービス プリンシパルを作成します。“Key Vault Secrets Officer” ロールを使用して Azure Key Vault にアクセスするためのアクセス許可を付与し、応答から ‘appId’‘password’、‘tenant’ を書き留めます。 機密情報を格納するためのバックエンドとして Key Vault ストレージを使用するには、Airflow で同じものを使用する必要があります。
az ad sp create-for-rbac -n <sp name> --role “Key Vault Secrets Officer” --scopes <key vault Resource ID>Workflow Orchestration Manager 用の Azure Key Vault を有効にして、機密情報を安全かつ一元的な方法で格納および管理します。 これを行うことで、変数と接続を使用することができ、それらは自動的に Azure Key Vault に格納されます。 接続と変数の名前には、AIRFLOW__SECRETS__BACKEND_KWARGS で定義した variables_prefix のプレフィックスを付ける必要があります。 たとえば、variables_prefixの値が hdinsight-aks-variables の場合、hello の変数キーに対して、変数を hdinsight-aks-variable -hello に格納する必要がありますす。
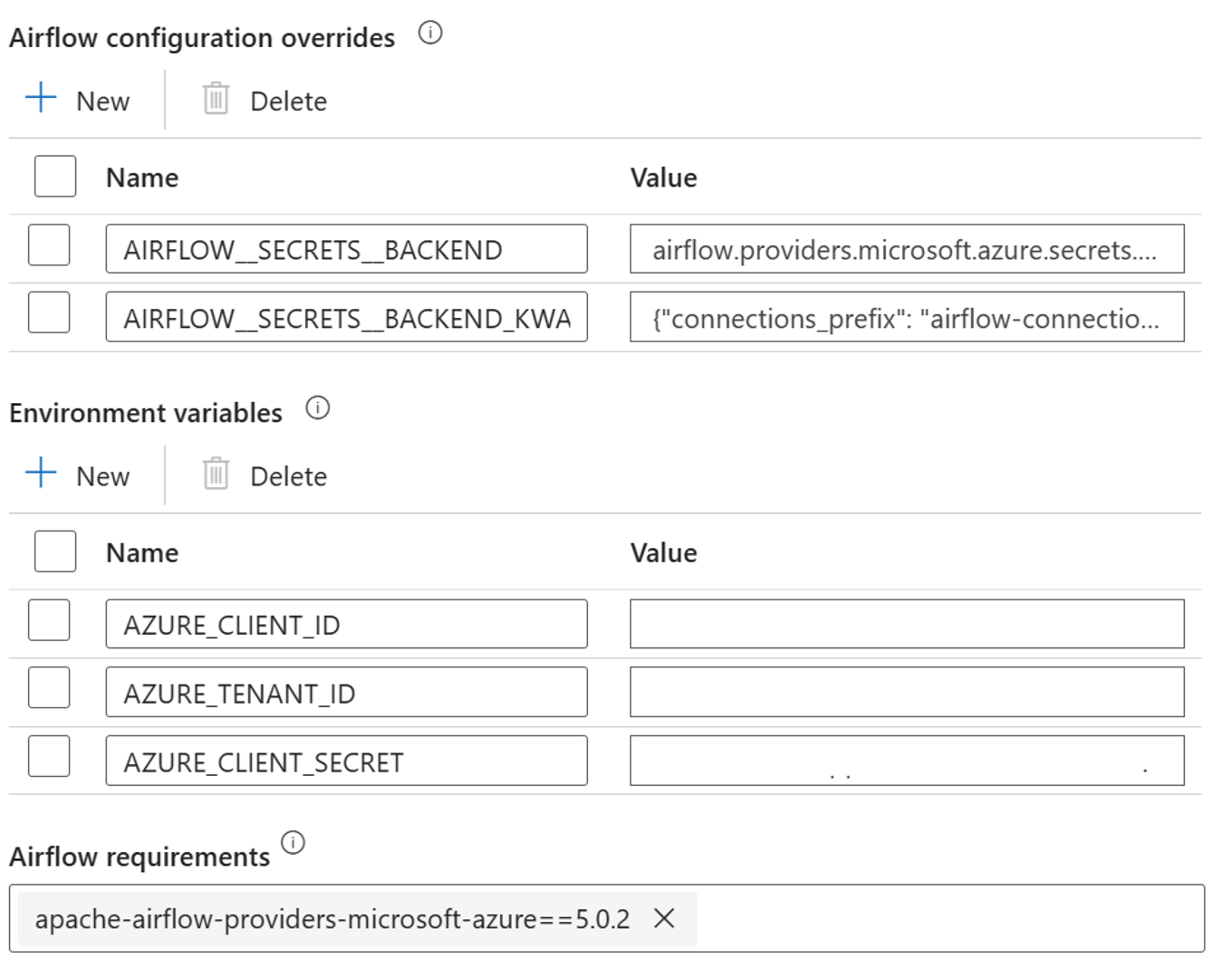
統合ランタイム プロパティの [Airflow 構成のオーバーライド] に以下の設定を追加します。
AIRFLOW__SECRETS__BACKEND:
"airflow.providers.microsoft.azure.secrets.key_vault.AzureKeyVaultBackend"AIRFLOW__SECRETS__BACKEND_KWARGS:
"{"connections_prefix": "airflow-connections", "variables_prefix": "hdinsight-aks-variables", "vault_url": <your keyvault uri>}”
Airflow 統合ランタイム プロパティの環境変数の構成に以下の設定を追加します。
AZURE_CLIENT_ID =
<App Id from Create Azure AD Service Principal>AZURE_TENANT_ID =
<Tenant from Create Azure AD Service Principal>AZURE_CLIENT_SECRET =
<Password from Create Azure AD Service Principal>
Airflow 要件を追加する - apache-airflow-providers-microsoft-azure
Azure にアクセスするための Microsoft Entra サービス プリンシパルを作成します。“共同作成者” ロールを使用して HDInsight AKS クラスターにアクセスするためのアクセス許可を付与し、応答から appId、password、tenant を書き留めます。
az ad sp create-for-rbac -n <sp name> --role Contributor --scopes <Flink Cluster Resource ID>前の AD サービス プリンシパルの appId、password、tenent からの値を使用してキー コンテナーに次のシークレットを作成し、AIRFLOW__SECRETS__BACKEND_KWARGS で定義されているプロパティ variables_prefix のプレフィックスを付けます。 DAG コードは、variables_prefix なしでこれらすべての変数にアクセスできます。
hdinsight-aks-variables-api-client-id=
<App ID from previous step>hdinsight-aks-variables-api-secret=
<Password from previous step>hdinsight-aks-variables-tenant-id=
<Tenant from previous step>
from airflow.models import Variable def retrieve_variable_from_akv(): variable_value = Variable.get("client-id") print(variable_value)

DAG の定義
DAG (有向非循環グラフ) は Airflow の核となる概念であり、タスクをまとめて収集し、依存関係とリレーションシップを使用して編成し、それらの実行方法を示します。
DAG を宣言するには、次の 3 つの方法があります。
コンテキスト マネージャーを使用して、その中のものに DAG を暗黙的に追加することができます
標準コンストラクターを使用して、使用する任意のオペレーターに DAG を渡すことができます
@dag デコレーターを使用して、関数を DAG ジェネレーターに変換できます (from airflow.decorators import dag)
DAG は実行するタスクがなければ存在できず、Operator、Sensor、または TaskFlow のいずれかの形式で提供されます。
DAG、制御フロー、SubDAG、TaskGroup などの詳細については、Apache Airflowを直接参照してください。
DAG の実行
サンプル コードは git で入手できます。コードをコンピューター上でローカルにダウンロードし、wordcount.py を BLOB ストレージにアップロードします。 手順に従って、セットアップ中に作成したワークフローに DAG をインポートします。
wordcount.py は、HDInsight on AKS で Apache Airflow を使用して Flink ジョブの送信を調整する例です。 DAG には、次の 2 つのタスクがあります。
get
OAuth TokenHDInsight Flink ジョブ送信 Azure REST API を呼び出して新しいジョブを送信する
DAG では、OAuth クライアント資格情報のセットアップ プロセス中に説明されているように、サービス プリンシパルのセットアップを行い、実行のために次の入力構成を渡す必要があります。
実行ステップ
Airflow UI から DAG を実行します。モニター アイコンをクリックして Azure Data Factory Workflow Orchestration Manager UI を開くことができます。

[DAG] ページから "FlinkWordCountExample" の DAG を選択します。

右上隅にある "実行" アイコンをクリックし、[Trigger DAG w/ config]\(構成ありで DAG をトリガー\) を選択します。
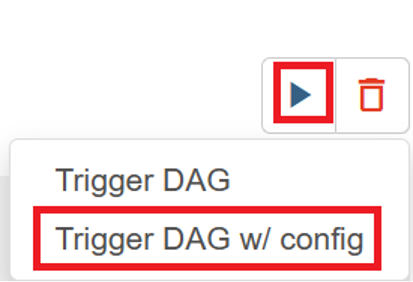
必須の構成 JSON を渡します
{ "jarName":"WordCount.jar", "jarDirectory":"abfs://filesystem@<storageaccount>.dfs.core.windows.net", "subscription":"<cluster subscription id>", "rg":"<cluster resource group>", "poolNm":"<cluster pool name>", "clusterNm":"<cluster name>" }"トリガー" ボタンをクリックすると、DAG の実行が開始されます。
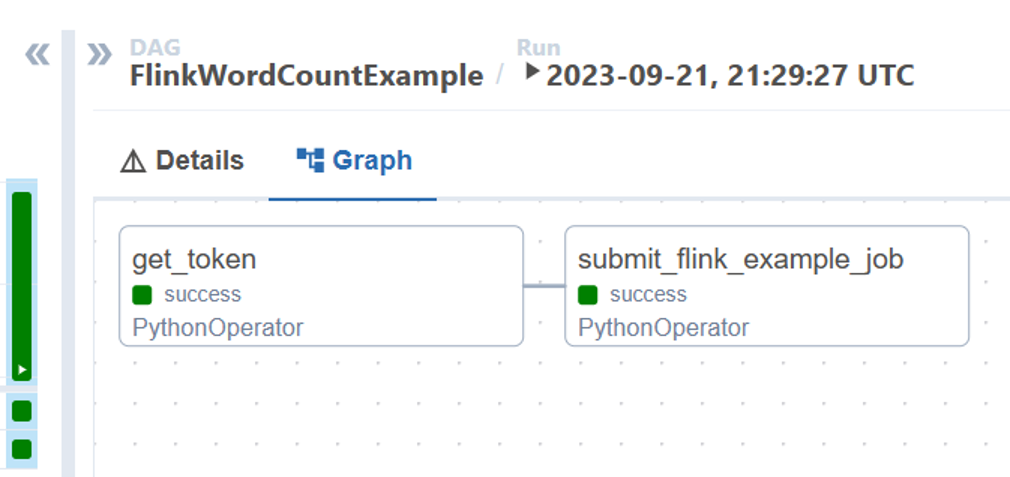
DAG 実行から DAG タスクの状態を視覚化できます
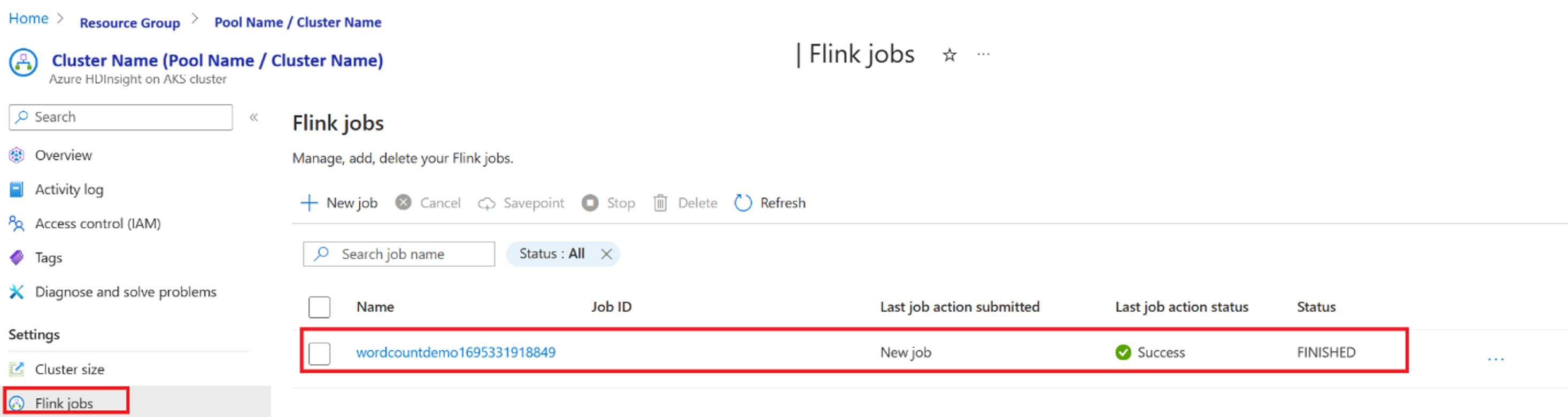
ポータルからジョブ実行を検証します
"Apache Flink ダッシュボード" からジョブを検証します






コード例
これは、HDInsight on AKS で Airflow を使用してデータ パイプラインを調整する例です。
DAG では、OAuth クライアント資格情報のサービス プリンシパルのセットアップを行い、実行のために次の入力構成を渡す必要があります。
{
'jarName':'WordCount.jar',
'jarDirectory':'abfs://filesystem@<storageaccount>.dfs.core.windows.net',
'subscription':'<cluster subscription id>',
'rg':'<cluster resource group>',
'poolNm':'<cluster pool name>',
'clusterNm':'<cluster name>'
}
リファレンス
- サンプル コードを参照してください。
- Apache Flink Web サイト
- Apache、Apache Airflow、Airflow、Apache Flink、Flink、関連するオープン ソース プロジェクト名は、Apache Software Foundation (ASF) の商標です。