変換の最適化
Azure Data Factory および Azure Synapse Analytics パイプラインのマッピング データ フローでの変換のパフォーマンスを最適化するには、次の戦略を使用します。
結合、存在、参照の最適化
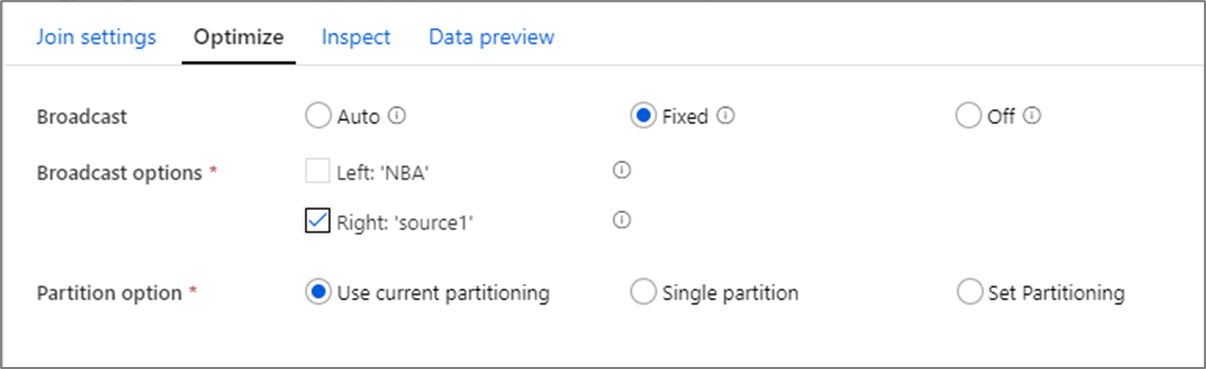
ブロードキャスト
結合変換、参照変換、および存在変換では、一方または両方のデータ ストリームが十分に小さくワーカー ノードのメモリに収まる場合、ブロードキャストを有効にすることでパフォーマンスを最適化できます。 ブロードキャストは、クラスター内のすべてのノードに小さなデータ フレームを送信するときに行います。 これにより、Spark エンジンで大きなストリーム内のデータを再シャッフルすることなく結合を実行できます。 既定では、結合の一方をブロードキャストするかどうかは、Spark エンジンによって自動的に決定されます。 受信データをよく知っていて、一方のストリームがもう一方のストリームよりも小さくなることがわかっている場合は、固定ブロードキャストを選択できます。 固定ブロードキャストを使用すると、選択したストリームが Spark で強制的にブロードキャストされます。
ブロードキャストされたデータのサイズが Spark ノードに対して大きすぎると、メモリ不足エラーが発生する可能性があります。 メモリ不足エラーを回避するには、メモリ最適化クラスターを使用します。 データ フローの実行中にブロードキャスト タイムアウトが発生する場合は、ブロードキャストの最適化をオフにすることができます。 ただし、これにより、データ フローのパフォーマンスが低下します。
大規模なデータベース クエリのように、クエリに時間がかかる可能性のあるデータ ソースを使用する場合は、結合のブロードキャストをオフにすることをお勧めします。 クエリ時間が長いソースでは、クラスターが計算ノードにブロードキャストしようとしたときに Spark タイムアウトが発生する可能性があります。 ブロードキャストを無効にすることをお勧めするもう 1 つの状況として、後で参照変換に使用するために値を集計するストリームがデータ フロー内に存在する場合があります。 このパターンでは、Spark オプティマイザーが混乱し、タイムアウトが発生する可能性があります。
クロス結合
結合条件でリテラル値を使用する場合、または結合の両側に複数の一致がある場合、結合は Spark でクロス結合として実行されます。 クロス結合は、結合された値を除外する完全なデカルト積です。 これは、他の結合の種類よりも遅くなります。 パフォーマンスへの影響を回避するために、結合条件の両側に必ず列参照があるようにします。
結合前の並べ替え
SSIS などのツールでのマージ結合とは異なり、結合変換は強制的なマージ結合操作ではありません。 結合キーを使用する場合、変換前に並べ替えを行う必要はありません。 マッピング データ フローでの並べ替え変換の使用は推奨されません。
ウィンドウ変換のパフォーマンス
マッピング データ フローでのウィンドウ変換では、変換設定の over() 句の一部として選択された列の値によってデータがパーティション分割されます。 ウィンドウ変換で公開されている非常に一般的な集計関数と分析関数が多数あります。 ただし、rank() または行番号 rowNumber() の順位付けのためにデータセット全体に対するウィンドウを生成するユースケースの場合は、代わりにランク変換と代理キー変換を使用することをお勧めします。 これらの変換のほうが、これらの関数を使用した完全なデータセットに対する操作のパフォーマンスが優れています。
非対称のデータのパーティション再分割
結合や集計などの特定の変換によってデータ パーティションが再シャッフルされるため、非対称のデータが生じることがあります。 非対称のデータは、パーティション間でデータが均等に分散されていないことを意味します。 データが大幅に非対称であると、ダウンストリーム変換とシンク書き込みの速度が低下する可能性があります。 データ フロー実行の任意の時点でデータの歪度を確認するには、監視画面で変換をクリックします。
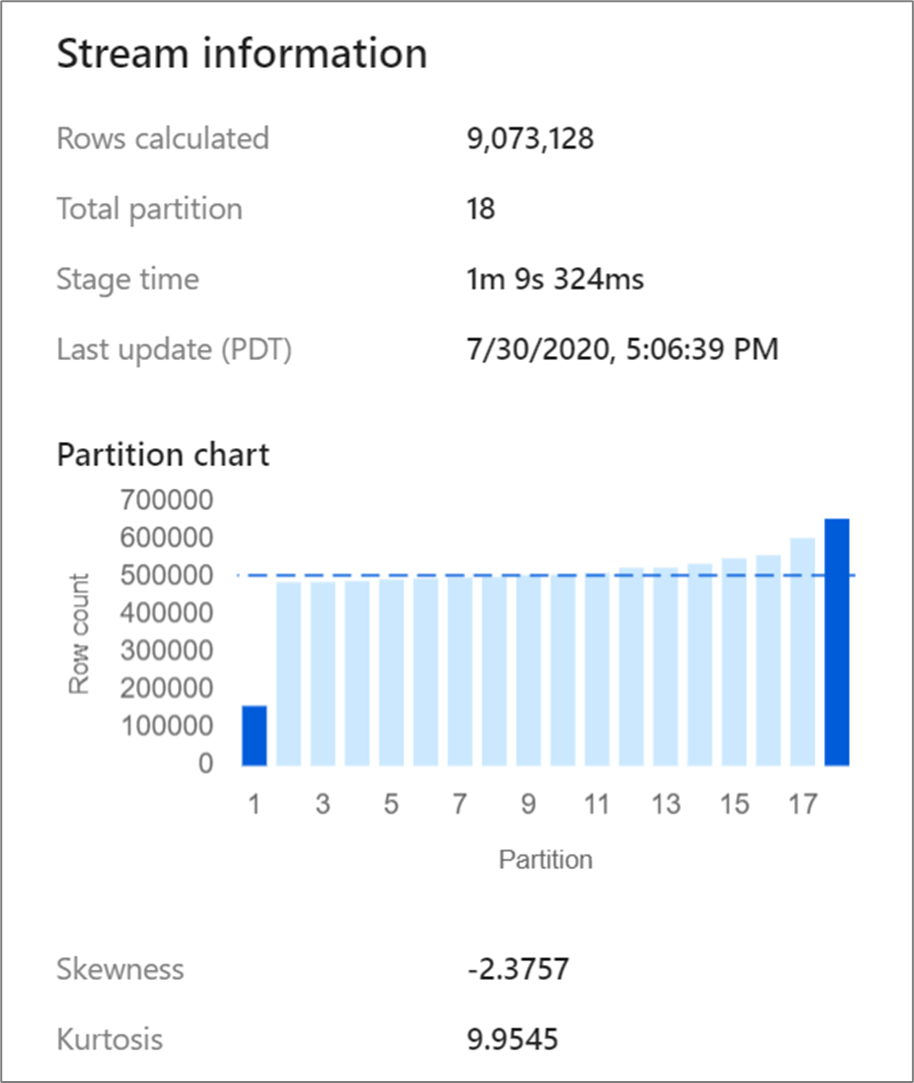
監視画面には、各パーティションにデータがどのように分散されているかが、歪度と尖度という 2 つのメトリックと共に示されます。 歪度は、データがどの程度非対称であるかを示す尺度であり、正、0、負、または未定義の値を持つことができます。 負の歪度は、左端が右側より長いことを意味します。 尖度は、データが大幅に非対称であるか、または軽度に非対称であるかを示す尺度です。 高い尖度値は望ましくありません。 理想的な歪度の範囲は -3 から 3 の範囲で、尖度の範囲は 10 未満です。 これらの数値を解釈する簡単な方法として、パーティション チャートを見て、1 つの棒が残りよりも大きいかどうかを確認します。
変換後にデータが均等に分割されていない場合は、[最適化] タブを使用してパーティションを再分割できます。 データの再シャッフルは時間がかかり、データ フローのパフォーマンス向上につながらない場合があります。
ヒント
データのパーティションを再分割するが、データを再シャッフルするダウンストリーム変換がある場合は、結合キーとして使用される列に対してハッシュ パーティション分割を使用します。
注意
データ フロー内の変換 (シンク変換を除く) によって、保存データのファイルとフォルダーのパーティション分割は変更されません。 各変換のパーティション分割により、データ フローの実行ごとに ADF が管理する一時的なサーバーレス Spark クラスターのデータ フレーム内のデータが再分割されます。
関連するコンテンツ
パフォーマンスに関する Data Flow のその他の記事を参照してください。