Azure HDInsight を使用した Apache Spark のトラブルシューティング
Apache Ambari で Apache Spark ペイロードを操作するときに発生する主な問題とその解決策について説明します。
クラスター上の Apache Ambari を使用して Apache Spark アプリケーションを構成する方法
Spark 構成値を調整して、Apache Spark アプリケーションの OutofMemoryError 例外を回避できます。 次の手順では、Azure HDInsight での既定の Spark 構成値を示します。
クラスターの資格情報を使用して Ambari (
https://CLUSTERNAME.azurehdidnsight.net) にログインします。 初期画面に概要ダッシュボードが表示されます。 HDInsight 4.0 では、画面にわずかな違いがあります。Spark2>[構成] に移動します。
![[Configs] タブをクリックします。](media/apache-troubleshoot-spark/apache-spark-ambari-config2.png)
構成の一覧で [Custom-spark2-defaults] を選択して展開します。
[spark.executor.memory] など、調整する必要のある値の設定を見つけます。 この場合、9728m という値は大きすぎます。
![[Custom-spark-defaults] を選択します。](media/apache-troubleshoot-spark/apache-spark-ambari-config4.png)
この値を推奨される値に設定します。 この設定では 2048m が推奨値です。
値を保存してから、構成を保存します。 [保存] を選択します。
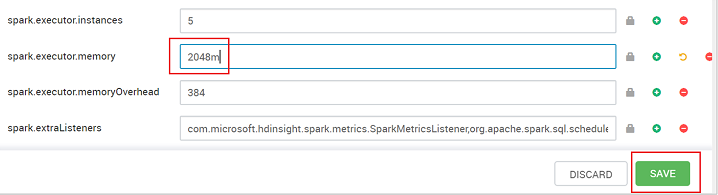
構成の変更内容に関するメモを入力して、 [Save](保存) をクリックします。
注意の必要な値がある場合は警告が表示されます。 各項目を確認したうえで [Proceed Anyway](警告を無視して続行) をクリックします。
![[Proceed Anyway]\(警告を無視して続行\) を選択します。](media/apache-troubleshoot-spark/apache-spark-ambari-config6b.png)
構成を保存すると、サービスを再起動するように求められます。 [Restart](再起動) をクリックします。
![[再起動] を選択します。](media/apache-troubleshoot-spark/apache-spark-ambari-config7a.png)
再起動を確定します。
 を選択します。](media/apache-troubleshoot-spark/apache-spark-ambari-config7b.png)
実行中のプロセスを確認できます。
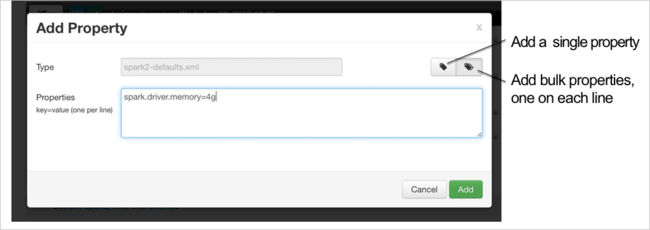
構成を追加することもできます。 構成の一覧で [Custom-spark2-defaults] を選択し、 [Add Property](プロパティの追加) をクリックします。
![[プロパティの追加] を選択します。](media/apache-troubleshoot-spark/apache-spark-ambari-config8.png)
新しいプロパティを定義します。 データ型など特定の設定用のダイアログ ボックスを使用して 1 つのプロパティを定義することができます。 または、1 行につき 1 つの定義を使用して、複数のプロパティを定義することもできます。
この例では、spark.driver.memory プロパティの値を 4g に定義しています。
構成を保存し、手順 6 と 7 の説明に従ってサービスを再起動します。
これらの変更はクラスター全体に適用されますが、Spark ジョブを送信するとオーバーライドできます。
クラスター上の Jupyter Notebook を使用して Apache Spark アプリケーションを構成する方法
%%configure ディレクティブの後にある最初の Jupyter Notebook セルに、Spark 構成を有効な JSON 形式で指定します。 必要に応じて、実際の値に変更します。

クラスター上の Apache Livy を使用して Apache Spark アプリケーションを構成する方法
cURL などの REST クライアントを使用して、Spark アプリケーションを Livy に送信します。 次のようなコマンドを使用します。 必要に応じて、実際の値に変更します。
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
クラスター上の spark-submit を使用して Apache Spark アプリケーションを構成する方法
次のようなコマンドを使用して、spark-shell を起動します。 必要に応じて、構成を実際の値に変更します。
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
その他の資料
HDInsight クラスターでの Apache Spark ジョブの送信
次のステップ
問題がわからなかった場合、または問題を解決できない場合は、次のいずれかのチャネルでサポートを受けてください。
Azure コミュニティのサポートを通じて Azure エキスパートから回答を得る。
カスタマー エクスペリエンスを向上させるための Microsoft Azure の公式アカウントの @AzureSupport に連絡する。 Azure コミュニティで適切なリソース (回答、サポート、エキスパートなど) につながる。
さらにヘルプが必要な場合は、Azure portal からサポート リクエストを送信できます。 メニュー バーから [サポート] を選択するか、 [ヘルプとサポート] ハブを開いてください。 詳細については、「Azure サポート要求を作成する方法」を参照してください。 サブスクリプション管理と課金サポートへのアクセスは、Microsoft Azure サブスクリプションに含まれていますが、テクニカル サポートはいずれかの Azure のサポート プランを通して提供されます。