Azure HDInsight での Apache Spark の OutOfMemoryError 例外
この記事では、Azure HDInsight クラスターで Apache Spark コンポーネントを使用するときのトラブルシューティングの手順と考えられる解決策について説明します。
シナリオ: Apache Spark の OutOfMemoryError 例外
問題
Apache Spark アプリケーションが OutOfMemoryError のハンドルされない例外で失敗しました。 次のようなエラー メッセージが表示される場合があります。
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
原因
この例外の最も可能性が高い原因として考えられるのは、Java 仮想マシン (JVM) に割り当てられたヒープ メモリの不足です。 これらの JVM は、Apache Spark アプリケーションの一部として、Executor またはドライバーとして起動されます。
解決方法
Spark アプリケーションによって処理されるデータの最大サイズを決定します。 入力データ、入力データの変換によって生成される中間データ、および中間データの変換によって生成される出力データの各最大サイズに基づいてサイズを推測します。 最初の推定値が十分でない場合は、サイズを少し増やし、メモリ エラーが治まるまで繰り返します。
使用する HDInsight クラスターにメモリや、Spark アプリケーションに対応できるコアなどのリソースが十分にあることを確認してください。 この判断は、クラスターの YARN UI の [Cluster Metrics](クラスター メトリック) セクションで、 [Memory Used](使用中のメモリ) の値と [Memory Total](メモリ合計) の値、および [VCores Used](使用中の VCore) の値と [VCores Total](VCore 合計) の値を比較することで行うことができます。

次の Spark 構成を適切な値に設定します。 アプリケーションの要件とクラスター内の使用可能なリソースとのバランスを調整します。 これらの値は、YARN によって表示される使用可能なメモリとコアの 90% を超えてはならず、Spark アプリケーションの最小メモリ要件も満たしている必要があります。
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)すべての実行プログラムで使用されるメモリの合計は次のとおりです。
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)ドライバーによって使用されるメモリの合計は次のとおりです。
spark.driver.memory + spark.yarn.driver.memoryOverhead
シナリオ: Apache Spark History Server を開こうとすると Java ヒープ スペース エラーが発生する
問題
Spark History Server でイベントを開くと、次のエラーが表示されます。
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
原因
この問題は多くの場合、大きな Spark イベント ファイルを開くときにリソースが不足していることが原因で発生します。 既定では、Spark ヒープ サイズは 1 GB に設定されていますが、大きな Spark イベント ファイルではこれ以上が要求される場合もあります。
読み込もうとしているファイルのサイズを確認するには、次のコマンドを実行します。
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
解決方法
Spark 構成の SPARK_DAEMON_MEMORY プロパティを編集し、すべてのサービスを再起動することで、Spark History Server のメモリを増やすことができます。
これを行うには、Ambari ブラウザー UI で、Spark2/Config/Advanced spark2-env セクションを選択します。
![[Advanced spark2-env] セクション。](media/apache-spark-ts-outofmemory-heap-space/apache-spark-image01.png)
Spark History Server メモリを 1G から 4G に変更するには、次のプロパティを追加します。SPARK_DAEMON_MEMORY=4g
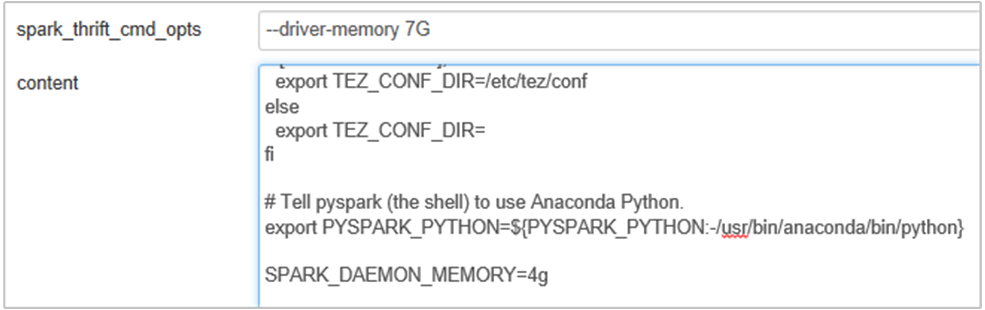
Ambari から、影響を受けるすべてのサービスを再起動してください。
シナリオ: Apache Spark クラスター上で Livy Server が起動しない
問題
Apache Spark 上で Livy Server を起動できません [(Linux 上の Spark 2.1 (HDI 3.6))]。 再起動しようとすると、Livy ログから次のエラー スタックが生成されます。
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
原因
java.lang.OutOfMemoryError: unable to create new native thread には、OS で、これ以上のネイティブ スレッドを JVM に割り当てることができないことが示されています。 この例外は、プロセスごとのスレッド数制限に違反したために発生したことを確認できます。
Livy Server が予期せず終了すると、Spark クラスターへの接続もすべて終了します。つまり、すべてのジョブと関連するデータが失われることになります。 HDP 2.6 で、セッションの復旧メカニズムが導入され、Livy Server が復帰すると、Livy では、復旧される Zookeeper にそのセッションの詳細が格納されます。
Livy から大量のジョブが送信されると、Livy Server の高可用性の一環として、これらのセッション状態が ZK (HDInsight クラスター上) に格納され、Livy サービスの再起動時にそれらのセッションが復旧されます。 予期しない終了後に再起動すると、Livy では、セッションごとに 1 つのスレッドが作成されます。このため、復旧対象のかなりのセッションが累積され、作成されるスレッドの数が非常に多くなります。
解像度
次の手順に従って、すべてのエントリを削除します。
以下を使用して、Zookeeper ノードの IP アドレスを取得します。
grep -R zk /etc/hadoop/conf上記のコマンドでは、クラスターの Zookeeper がすべて一覧表示されます
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>ping を使用して Zookeeper ノードの IP アドレスをすべて取得するか、Zookeeper 名を使用してヘッドノードから Zookeeper に接続することもできます
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Zookeeper に接続したら、次のコマンドを実行して、再起動しようとしたセッションをすべて一覧表示します。
ほとんどの場合、この一覧に 8000 個を超えるセッションが含まれる可能性があります ####
ls /livy/v1/batch次のコマンドでは、復旧対象のセッションがすべて削除されます。 #####
rmr /livy/v1/batch
上記のコマンドが完了し、カーソルがプロンプトに戻るまで待って、Ambari から Livy サービスを再起動すると、今回は成功するはずです。
注意
Livy セッションは、実行が完了したら削除 (DELETE) します。 Livy バッチ セッションは、spark アプリが完了直後に自動的に削除されることはありません。これは仕様です。 Livy セッションは、Livy REST サーバーに対する POST 要求によって作成されるエンティティです。 DELETE 呼び出しは、そのエンティティを削除するために必要です。 または、GC が開始されるまで待機する必要があります。
次のステップ
問題がわからなかった場合、または問題を解決できない場合は、次のいずれかのチャネルでサポートを受けてください。
Azure コミュニティのサポートを通じて Azure エキスパートから回答を得る。
カスタマー エクスペリエンスを向上させるための Microsoft Azure の公式アカウントの @AzureSupport に連絡する。 Azure コミュニティで適切なリソース (回答、サポート、エキスパートなど) につながる。
さらにヘルプが必要な場合は、Azure portal からサポート リクエストを送信できます。 メニュー バーから [サポート] を選択するか、 [ヘルプとサポート] ハブを開いてください。 詳細については、「Azure サポート要求を作成する方法」を参照してください。 サブスクリプション管理と課金サポートへのアクセスは、Microsoft Azure サブスクリプションに含まれていますが、テクニカル サポートはいずれかの Azure のサポート プランを通して提供されます。