Apache Spark Structured Streaming の概要
Apache Spark Structured Streaming を使用すると、データ ストリームを処理するためのスケーラブルで、かつ高スループットのフォールト トレラント アプリケーションを実装できます。 Structured Streaming は Spark SQL エンジンに基づいて構築されており、ストリーミング クエリをバッチ クエリと同じ方法で記述できるように、Spark SQL データ フレームおよびデータセットからの構造を機能強化しています。
Structured Streaming アプリケーションは HDInsight Spark クラスター上で実行され、Apache Kafka、TCP ソケット (デバッグのため)、Azure Storage、または Azure Data Lake Storage からのストリーミング データに接続します。 外部のストレージ サービスに依存する後者の 2 つのオプションを使用すると、ストレージに追加された新しいファイルを監視し、それらのファイルがストリーミングされているかのようにその内容を処理できます。
Structured Streaming は、入力データに選択、プロジェクション、集計、ウィンドウ化、ストリーミング データフレームの参照データフレームとの結合などの操作を適用するための、実行時間の長いクエリを作成します。 次に、その結果をファイル ストレージ (Azure Storage BLOB や Data Lake Storage) に、またはカスタム コード (SQL Database や Power BI など) を使用して任意のデータストアに出力します。 Structured Streaming ではまた、ローカルでのデバッグのためにコンソールに出力したり、HDInsight でのデバッグのために生成されたデータを表示できるようにインメモリ テーブルに出力したりする機能も提供されます。
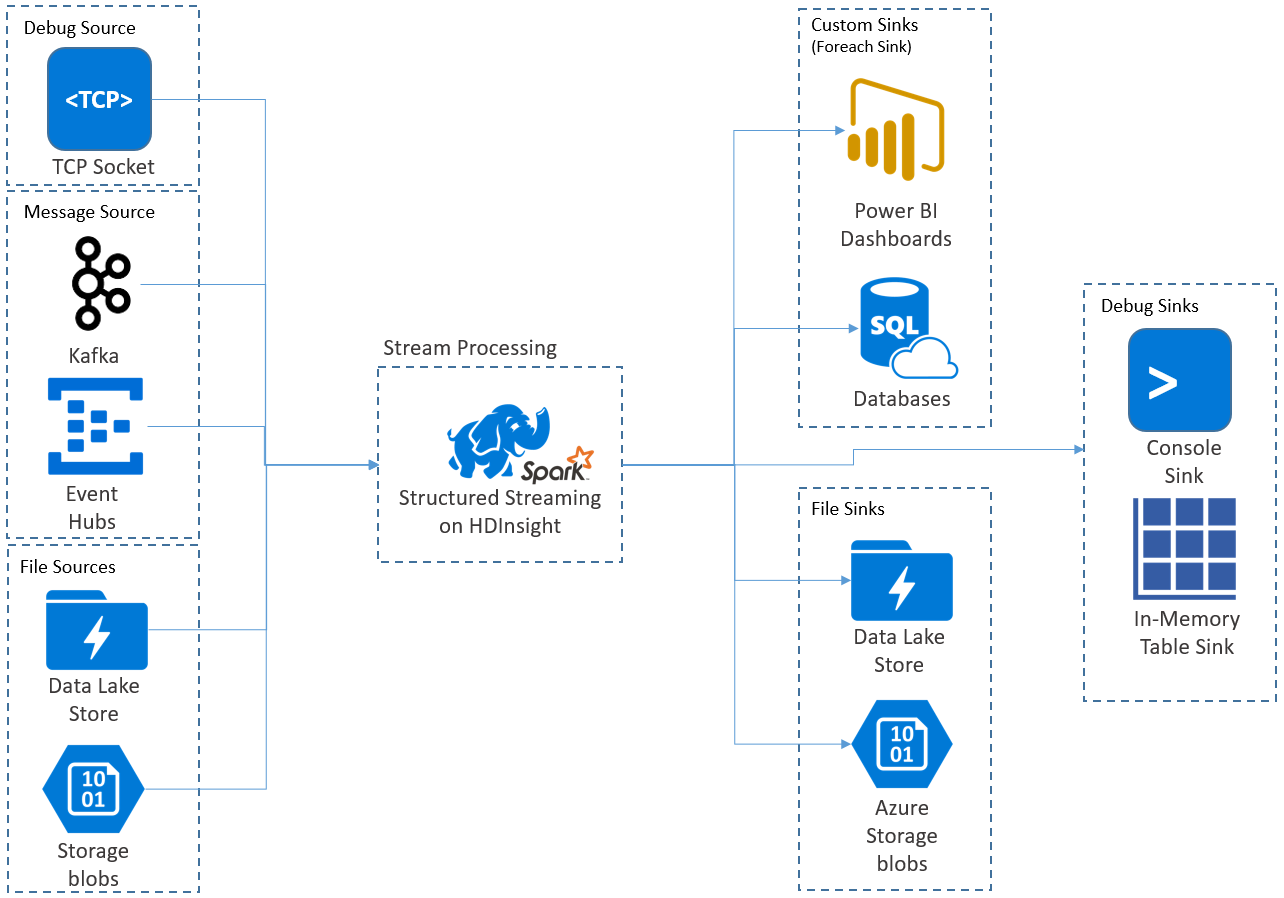
Note
Spark Structured Streaming は、Spark ストリーミング (DStreams) に代わるものです。 将来的には、Structured Streaming が拡張機能やメンテナンスを受けるのに対して、DStreams はメンテナンス モードのみになります。 Structured Streaming は現在、標準でサポートされるソースやシンクに関して DStreams ほど機能が充実していないため、実際の要件を評価して適切な Spark ストリーム処理オプションを選択してください。
テーブルとしてのストリーム
Spark Structured Streaming は、データのストリームを深さが無限のテーブルとして表します。つまり、このテーブルは新しいデータが到着するたびに増大し続けます。 この入力テーブルは実行時間の長いクエリによって継続的に処理され、その結果が出力テーブルに送信されます。

Structured Streaming では、データがシステムに到着すると、直ちに入力テーブルに取り込まれます。 この入力テーブルに対して操作を実行するクエリを (データフレームおよびデータセット API を使用して) 記述します。 このクエリの出力により、別のテーブルである結果テーブルが生成されます。 結果テーブルにはクエリの結果が含まれており、そこから、データをリレーショナル データベースなどの外部のデータストアに取り出します。 入力テーブルのデータが処理されるタイミングは、トリガー間隔によって制御されます。 既定では、トリガー間隔は 0 であるため、Structured Streaming はデータが到着するとすぐに処理しようとします。 これは、実際には、Structured Streaming が前のクエリの処理を完了するとすぐに、新しく受信したデータに対する別の処理を開始することを示します。 ストリーミング データが時間ベースのバッチで処理されるように、トリガーを一定の間隔で実行されるように構成することができます。
結果テーブル内のデータに、最後にクエリが処理されてからの新しいデータのみを含めることも (追加モード)、新しいデータが到着するたびにテーブルを更新して、そのテーブルにストリーミング クエリが開始されてからのすべての出力データが含まれるようにすることもできます (完全モード)。
追加モード
追加モードでは、最後のクエリ実行の後に結果テーブルに追加された行のみが結果テーブル内に存在し、外部ストレージに書き込まれます。 たとえば、最も単純なクエリは、すべてのデータを入力テーブルから結果テーブルにそのままコピーするだけです。 トリガー間隔が経過するたびに、新しいデータが処理され、その新しいデータを表す行が結果テーブルに現れます。
サーモスタットなどの温度センサーからのテレメトリを処理しているシナリオを考えてみます。 最初のトリガーで、温度の読み取りが 95 度のデバイス 1 に関して時間 00:01 に 1 つのイベントが処理されたとします。 クエリの最初のトリガーでは、時間 00:01 の行のみが結果テーブルに現れます。 別のイベントが到着した時間 00:02 には、新しい行は時間 00:02 の行だけであるため、結果テーブルにはその 1 行のみが含まれます。
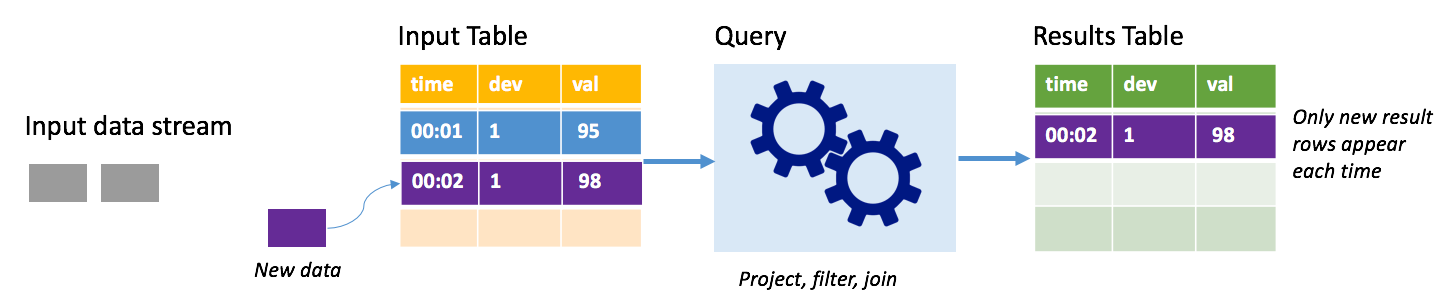
追加モードを使用しているとき、クエリはプロジェクションを適用している (対象の列を選択している) か、フィルター処理している (特定の条件に一致する行のみを選択している) か、結合している (静的ルックアップ テーブルからのデータを含むデータを増やしている) かのいずれかです。 追加モードにより、関連する新しいデータ ポイントのみを外部ストレージにプッシュすることが容易になります。
完全モード
同じシナリオを考えますが、今回は完全モードを使用します。 完全モードでは、テーブルに最新のトリガー実行だけでなく、すべての実行のデータが含まれるように、トリガーごとに出力テーブル全体が更新されます。 完全モードを使用すると、データを入力テーブルから結果テーブルにそのままコピーすることもできます。 トリガーが実行されるたびに、新しい結果行が以前のすべての行と共に現れます。 出力結果テーブルには最終的に、クエリが開始されてから収集されたすべてのデータが格納され、最後はメモリ不足になります。 完全モードは受信データを何らかの方法で集計する集計クエリで使用されることを目的にしているため、トリガーが実行されるたびに、結果テーブルは新しい集計値で更新されます。
これまでに既に 5 秒分のデータが処理されており、これから 6 秒目のデータが処理されるものとします。 入力テーブルには、時間 00:01 と時間 00:03 のイベントが含まれています。 このクエリ例の目標は、5 秒ごとにデバイスの平均温度を示すことです。 このクエリの実装では、各 5 秒間ウィンドウに含まれるすべての値を取得する集計を適用し、温度を平均して、その間隔の平均温度の行を生成します。 最初の 5 秒間ウィンドウの最後には、(00:01, 1, 95) と (00:03, 1, 98) の 2 組が存在します。 そのため、00:00-00:05 ウィンドウに対して、この集計では 96.5 度の平均温度を含む組が生成されます。 次の 5 秒間では、データ ポイントが時間 00:06 に 1 つしか存在しないため、結果として得られる平均温度は 98 度です。 時間 00:10 には、完全モードを使用しており、このクエリが新しい行だけでなく、集計されたすべての行を出力するため、結果テーブルには 00:00-00:05 と 00:05-00:10 の両方のウィンドウの行が含まれます。 そのため、結果テーブルは、新しいウィンドウが追加されるたびに増大し続けます。
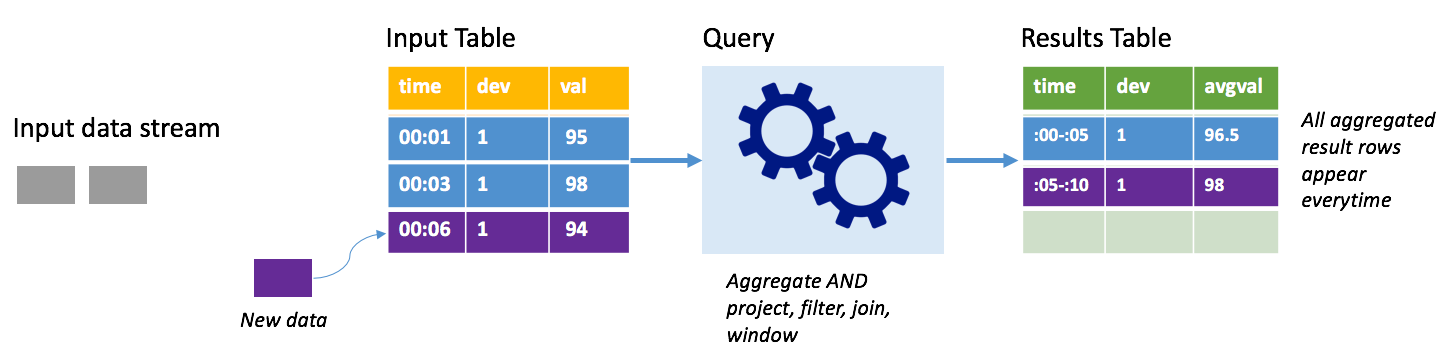
完全モードを使用するすべてのクエリでテーブルが制限なく増大するわけではありません。 前の例で、温度を時間ウィンドウで平均するのではなく、代わりにデバイス ID で平均したものと考えてみます。 結果テーブルには、各デバイスから受信されたすべてのデータ ポイントにわたるそのデバイスの平均温度を含む固定された行数 (デバイスごとに 1 行) が含まれます。 新しい温度が受信されると、結果テーブルは、そのテーブル内の平均が常に最新の状態になるように更新されます。
Spark Structured Streaming アプリケーションのコンポーネント
単純なクエリ例では、温度の読み取りを 1 時間ウィンドウで集計できます。 この場合、データは (HDInsight クラスターの既定のストレージとしてアタッチされた) Azure Storage 内の JSON ファイルに格納されます。
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
これらの JSON ファイルは、HDInsight クラスターのコンテナーの下にある temps サブフォルダに格納されます。
入力ソースを定義する
最初に、データのソースとそのソースに必要なすべての設定を記述したデータフレームを構成します。 この例では、Azure Storage 内の JSON ファイルから取り出し、読み取り時にそれらのファイルにスキーマを適用します。
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
クエリを適用する
次に、ストリーミング データフレームに対する目的の操作を含むクエリを適用します。 この場合は、集計によってすべての行が 1 時間ウィンドウにグループ化された後、その 1 時間ウィンドウ内の最低、平均、および最高温度が計算されます。
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
出力シンクを定義する
次に、各トリガー間隔内の結果テーブルに追加された行の宛先を定義します。 この例では、すべての行を、後で SparkSQL でクエリを適用できるインメモリ テーブル temps に出力するだけです。 完全出力モードでは、すべてのウィンドウのすべての行が毎回確実に出力さます。
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
クエリを起動する
ストリーミング クエリを起動し、終了シグナルが受信されるまで実行します。
val query = streamingOutDF.start()
結果を表示する
クエリの実行中に、同じ SparkSession で、クエリの結果が格納される temps テーブルに対して SparkSQL クエリを実行できます。
select * from temps
このクエリにより、次のような結果が生成されます。
| window | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Spark Structured Stream API と、それがサポートする入力データ ソース、操作、および出力シンクの詳細については、Apache Spark Structured Streaming プログラミング ガイドを参照してください。
チェックポイント機能と先書きログ
回復性とフォールト トレランスを実現するために、Structured Streaming はチェックポイント機能を使用して、ノード障害が発生した場合でもストリーム処理を中断なく続行できるようにします。 HDInsight では、Spark はチェックポイントを持続性のあるストレージ (Azure Storage または Data Lake Storage のどちらか) に作成します。 これらのチェックポイントでは、ストリーミング クエリに関する進行状況の情報を格納します。 さらに、Structured Streaming では先書きログ (WAL) も使用します。 WAL は、受信されたが、まだクエリによって処理されていない取り込まれたデータをキャプチャします。 障害が発生し、WAL から処理が再開された場合でも、ソースから受信されたどのイベントも失われません。
Spark ストリーミング アプリケーションのデプロイ
通常、Spark Streaming アプリケーションは JAR ファイルにローカルに構築した後、その JAR ファイルを HDInsight クラスターに接続された既定のストレージにコピーすることによって HDInsight 上の Spark にデプロイします。 そのアプリケーションは、POST 操作を使用して、クラスターから使用可能な Apache Livy REST API で起動できます。 POST の本文には、JAR へのパス、メイン メソッドがストリーミング アプリケーションを定義して実行するクラスの名前、オプションでジョブのリソース要件 (実行プログラム、メモリ、コアの数など)、およびアプリケーション コードに必要なすべての構成設定を指定する JSON ドキュメントが含まれています。
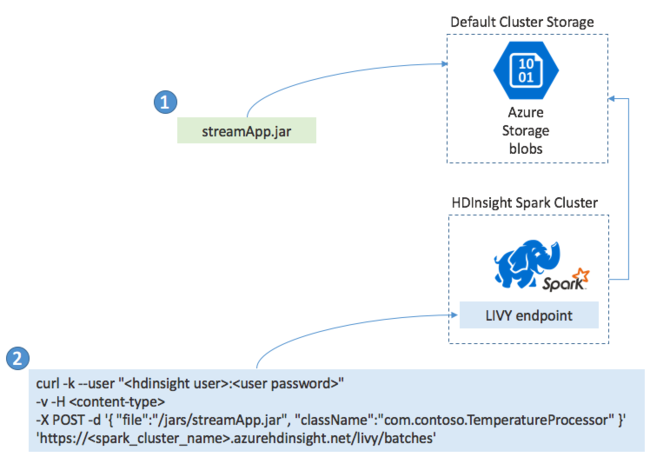
GET 要求を使用して、LIVY エンドポイントに対してすべてのアプリケーションの状態をチェックすることもできます。 最後に、LIVY エンドポイントに対して DELETE 要求を発行することによって、実行中のアプリケーションを終了できます。 LIVY API の詳細については、Apache LIVY を使用したリモート ジョブに関するページを参照してください