Azure HDInsight クラスターを自動的にスケール調整する
Azure HDInsight の無料の自動スケーリング機能を使用すると、お客様が採用したクラスターのメトリックとスケーリング ポリシーに基づいて、クラスター内のワーカー ノードの数を自動的に増減できます。 自動スケーリング機能は、パフォーマンス メトリックまたはスケールアップ操作やスケールダウン操作の定義されたスケジュールに基づいて、事前設定された制限内でノードの数をスケーリングすることで機能します。
しくみ
自動スケーリング機能では、スケーリング イベントをトリガーするために 2 種類の条件を使用します。さまざまなクラスター パフォーマンス メトリックのしきい値 ("負荷ベースのスケーリング" と呼ばれます) と、時間ベースのトリガー ("スケジュール ベースのスケーリング" と呼ばれます) です。 負荷ベースのスケーリングでは、ユーザーが設定した範囲内でクラスター内のノードの数が変更され、最適な CPU 使用率と最小のランニング コストが保証されます。 スケジュール ベースのスケーリングでは、スケールアップ操作やスケールダウン操作のスケジュールに基づいて、クラスター内のノードの数が変更されます。
次のビデオでは、自動スケーリングによって解決される課題の概要と、HDInsight を使用したコストの管理にそれがどのように役立つかについて説明します。
負荷ベースまたはスケジュール ベースのスケーリングを選択する
スケジュールに基づくスケーリングは次のような場合に使用できます。
- ジョブが固定されたスケジュールで予測可能な期間実行されることが予想されるか、1 日のうちの特定の時間帯に使用頻度が低いことが予想されるとき。 たとえば、業務時間後のテストおよび開発環境、1 日の終わりのジョブなどです。
負荷ベースのスケーリングは次のような場合に使用できます。
- ロード パターンが 1 日のうちで大きく変動し、予測不能である場合。 たとえば、さまざまな要因に基づいてロード パターンのランダムな変動がある注文データ処理などです。
クラスターのメトリック
自動スケールはクラスターを継続的に監視し、次のメトリックを収集します。
| メトリック | 説明 |
|---|---|
| 保留中の CPU の合計 | すべての保留中のコンテナーの実行を開始するために必要なコアの総数。 |
| 保留中のメモリの合計 | すべての保留中のコンテナーの実行を開始するために必要なメモリの合計 (MB 単位)。 |
| 空き CPU の合計 | アクティブなワーカー ノード上のすべての未使用のコアの合計。 |
| 空きメモリの合計 | アクティブなワーカー ノード上の未使用のメモリの合計 (MB 単位)。 |
| ノードごとの使用済みメモリ | ワーカー ノード上の負荷。 10 GB のメモリが使用されているワーカー ノードは、使用済みメモリが 2 GB のワーカー ノードより多くの負荷がかかっていると見なされます。 |
| ノードごとのアプリケーション マスターの数 | ワーカー ノード上で実行されているアプリケーション マスター (AM) コンテナーの数。 2 つの AM コンテナーをホストしているワーカー ノードは、ホストしている AM コンテナーがないワーカー ノードより重要であると見なされます。 |
上のメトリックは 60 秒ごとにチェックされます。 自動スケーリングでは、これらのメトリックに基づいてスケールアップおよびスケールダウンの決定が行われます。
クラスター メトリックの完全な一覧については、「Microsoft.HDInsight/clusters でサポートされてうるメトリック」を参照してください。
負荷ベースのスケール条件
次の条件が検出されると、自動スケーリングによりスケーリング要求が発行されます。
| スケールアップ | スケールダウン |
|---|---|
| 保留中の CPU の合計が、空き CPU の合計を超えて 3-5 分以上が経過した。 | 保留中の CPU の合計が空き CPU の合計を下回って 3 分から 5 分以上が経過した。 |
| 保留中のメモリの合計が、空きメモリの合計を超えて 3-5 分以上が経過した。 | 保留中のメモリの合計が空きメモリの合計を下回って 3 分から 5 分以上が経過した。 |
スケールアップの場合、自動スケーリングは、必要な数のノードを追加するスケールアップ要求を発行します。 スケールアップは、現在の CPU とメモリの要件を満たすために必要な新しいワーカー ノード数に基づいて行われます。
スケールダウンの場合、自動スケーリングでは、いくつかのノードを削除する要求が発行されます。 スケールダウンは、ノードあたりのアプリケーション マスター (AM) コンテナーの数に基づいて行われます。 現在の CPU とメモリの要件にもです。 また、サービスでは、現在のジョブの実行に基づいて、削除候補のノードも検出されます。 スケールダウン操作では、最初にノードの使用が停止された後、クラスターから削除されます。
自動スケーリングのための Ambari DB のサイズ設定に関する考慮事項
自動スケーリングの利点を得るために、Ambari DB のサイズを正しく設定することをお勧めします。 お客様は、正しい DB 層を使用し、大規模なクラスターに対してカスタム Ambari DB を使用する必要があります。 データベースとヘッドノードのサイズ設定の推奨事項に関するページをお読みください。
クラスターの互換性
重要
Azure HDInsight 自動スケーリング機能は、Spark および Hadoop クラスター向けに 2019 年 11 月 7 日に一般提供され、プレビュー バージョンの機能では利用できない機能強化が追加されました。 2019 年 11 月 7 日より前に Spark クラスターを作成済みで、クラスター上で自動スケーリング機能を使用する場合、推奨されるパスは、新しいクラスターを作成し、新しいクラスター上で enable Autoscale ことです。
Interactive Query (LLAP) の自動スケーリングは、2020 年 8 月 27 日に HDI 4.0 用に一般公開されました。 自動スケーリングは、Spark、Hadoop、Interactive Query、およびクラスター上でのみ使用できます。
次の表では、自動スケーリング機能と互換性のあるクラスターの種類とバージョンについて説明します。
| Version | Spark | Hive | Interactive Query | hbase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 (ESP なし) | はい | はい | はい* | いいえ | いいえ |
| HDInsight 4.0 (ESP あり) | はい | はい | はい* | いいえ | いいえ |
| HDInsight 5.0 (ESP なし) | はい | はい | はい* | いいえ | いいえ |
| HDInsight 5.0 (ESP あり) | はい | はい | はい* | いいえ | いいえ |
* Interactive Query クラスターは、負荷ベースではなく、スケジュールベースのスケーリングの場合にのみ構成できます。
はじめに
負荷ベースの自動スケーリングでクラスターを作成する
負荷ベースのスケーリングで自動スケーリング機能を有効にするには、通常のクラスターの作成プロセスの一部として、次の手順を行います。
[構成と価格] タブで、
Enable autoscaleチェック ボックスをオンにします。[Autoscale type](自動スケーリングの種類) で、 [Load-based](負荷ベース) を選択します。
次のプロパティに対して目的の値を入力します。
- [ワーカー ノード] の初期の [Number of nodes](ノードの数) 。
- ワーカー ノードの [最小] の数。
- ワーカー ノードの [最大] の数。
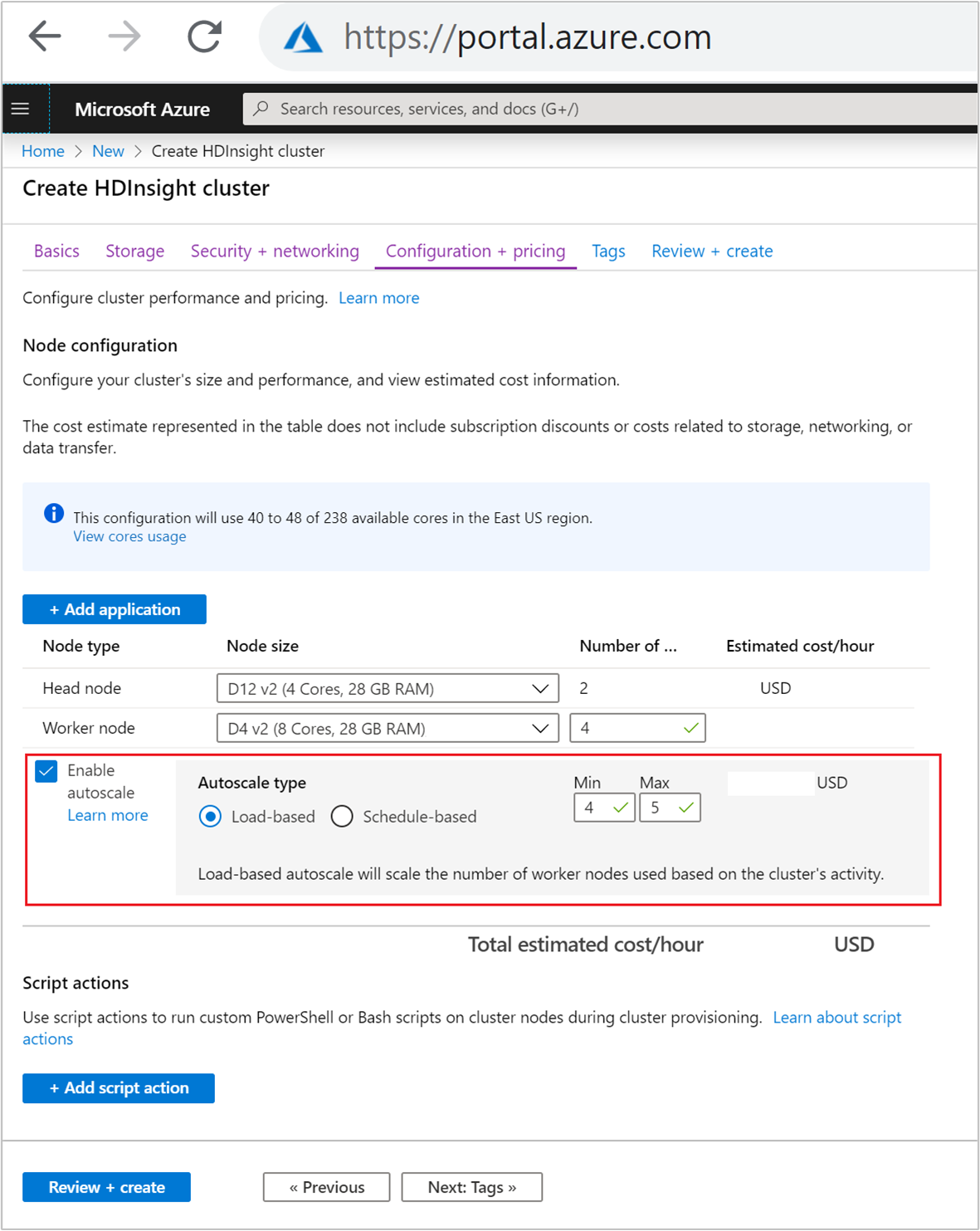
ワーカー ノードの初期の数には、最小数から最大数までの数を指定する必要があります。 この値によって、クラスターが作成されるときのその初期サイズが定義されます。 ワーカー ノードの最小数は、3 以上に設定する必要があります クラスターを 3 つ未満のノードにスケーリングすると、ファイル レプリケーションが不十分なためにセーフ モードでスタックする場合があります。 詳細については、「セーフ モードでスタックする」を参照してください。
スケジュール ベースの自動スケーリングでクラスターを作成する
スケジュール ベースのスケーリングで自動スケーリング機能を有効にするには、通常のクラスターの作成プロセスの一部として、次の手順を行います。
[構成と価格] タブで、
Enable autoscaleチェック ボックスをオンにします。[ワーカー ノード] の [Number of nodes](ノードの数) を入力します。これは、クラスターのスケールアップの制限を制御します。
[Autoscale type](自動スケーリングの種類) で、 [Schedule-based](スケジュール ベース) オプションを選択ます。
[構成] を選択して [Autoscale configuration](自動スケーリングの構成) ウィンドウを開きます。
タイムゾーンを選択し、 [+ Add condition](+ 条件の追加) をクリックします
新しい条件を適用する曜日を選択します。
条件を有効にする時刻と、クラスターのスケーリング後のノード数を編集します。
必要に応じて、さらに条件を追加します。
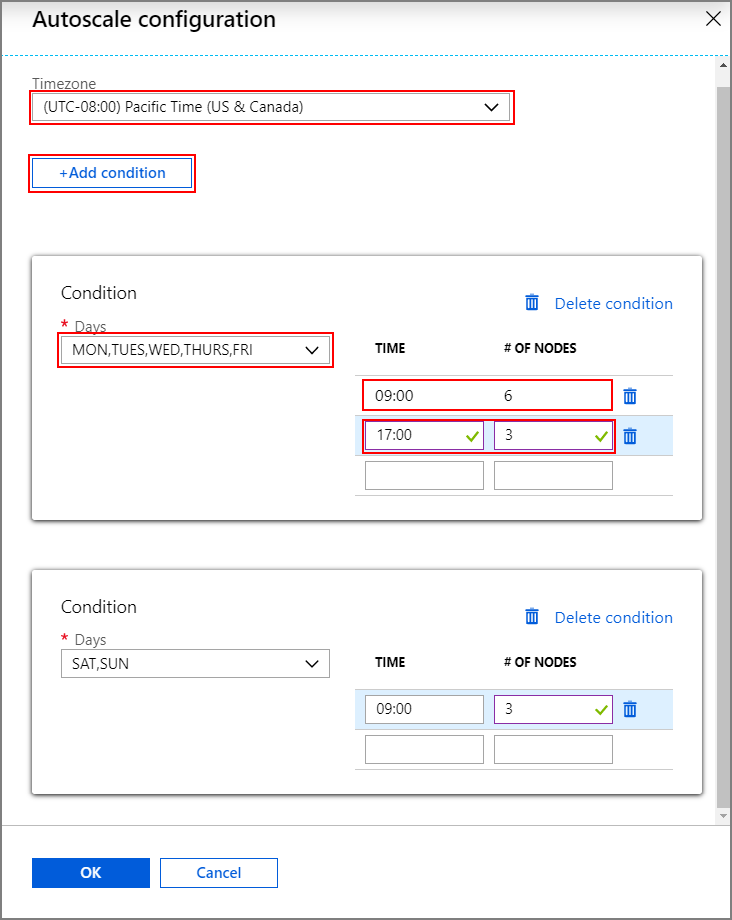
ノードの数は、3 から条件追加前に入力したワーカー ノードの最大数の間にする必要があります。
最後の作成手順
[ノード サイズ] の下のドロップダウン リストから VM を選択して、ワーカー ノードの VM の種類を選択します。 ノードの種類ごとに VM の種類を選択すると、クラスター全体の概算のコスト範囲を表示できるようになります。 予算に合わせて VM の種類を調整します。
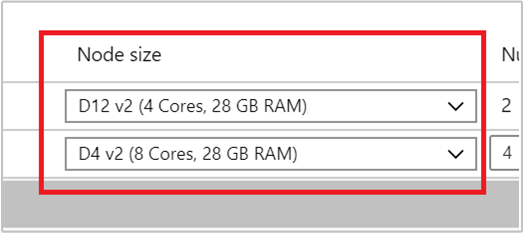
サブスクリプションには、リージョンごとに容量のクォータがあります。 ヘッド ノードのコアの総数とワーカー ノードの最大数の合計が容量のクォータを超えることはできません。 ただし、このクォータはソフト制限です。それを簡単に増やすためのサポート チケットをいつでも作成できます。
注意
合計のコア クォータ制限を超えた場合は、"最大ノードがこのリージョン内の使用可能なコア数を超えました。別のリージョンを選択するか、またはサポートに連絡してクォータを増やしてください" というエラー メッセージが表示されます。
Azure portal を使用した HDInsight クラスターの作成に関する詳細については、「Azure Portal を使用した HDInsight の Linux ベースのクラスターの作成」を参照してください。
Resource Manager テンプレートでクラスターを作成する
負荷ベースの自動スケーリング
JSON スニペットに示すように、プロパティ minInstanceCount と maxInstanceCount で computeProfile>workernode セクションに autoscale ノードを追加することで、Azure Resource Manager テンプレートで負荷ベースの自動スケーリングを使用する HDInsight クラスターを作成できます。 完全なリソース マネージャー テンプレートについては、負荷ベースの自動スケーリングを有効にして Spark クラスターをデプロイするクイックスタート テンプレートを参照してください。
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
スケジュール ベースの自動スケーリング
computeProfile>workernode セクションに autoscale ノードを追加することで、Azure Resource Manager テンプレートでスケジュール ベースの自動スケーリングを使用する HDInsight クラスターを作成できます。 autoscale ノードには、timezone および変更が行われるタイミングが記述されている schedule がある recurrence が含まれます。 完全な Resource Manager テンプレートについては、「Deploy Spark Cluster with schedule-based Autoscale Enabled」 (スケジュールベースの自動スケーリングを有効にして Spark クラスターをデプロイする) を参照してください。
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
実行中のクラスターの自動スケーリングの有効化および無効化
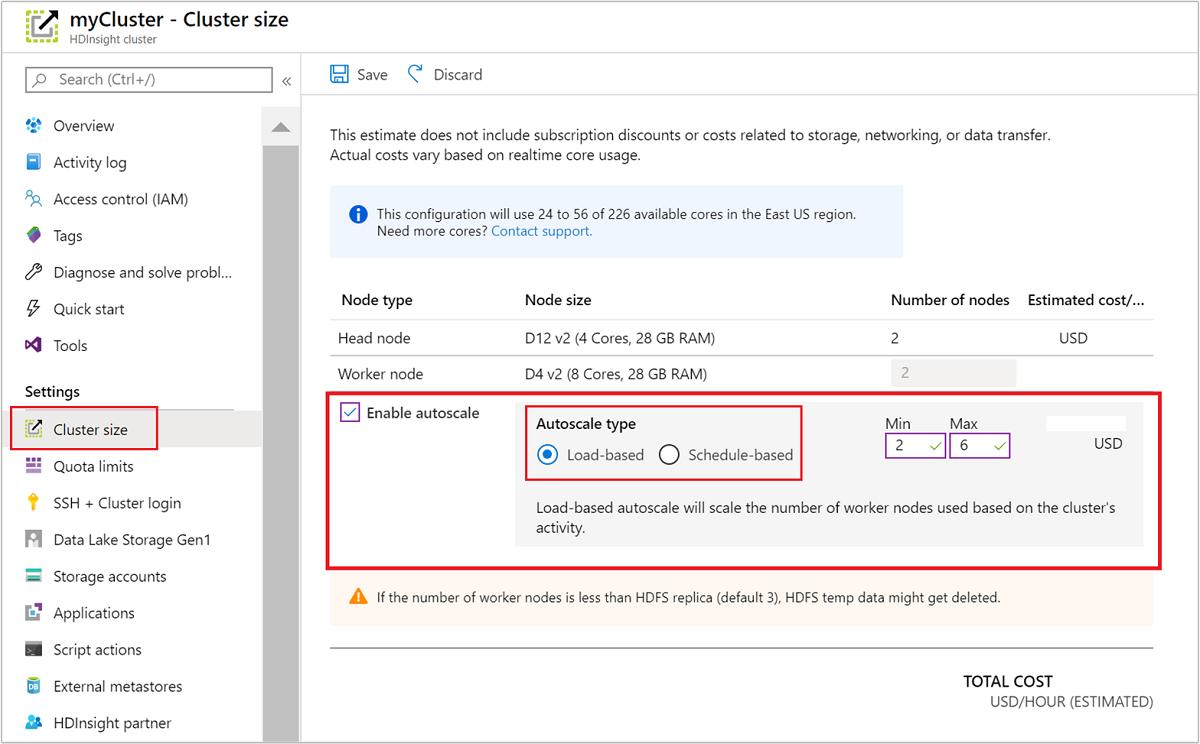
Azure ポータルの使用
実行中のクラスターで自動スケーリングを有効にするには、 [設定] の [クラスター サイズ] を選択します。 次に、Enable autoscale を選択します。 使用する自動スケーリングの種類を選択し、負荷ベースまたはスケジュール ベースのスケーリングのオプションを入力します。 最後に、 [保存] を選択します。
REST API の使用
REST API を使用して、実行中のクラスターで自動スケーリングを有効または無効にするには、自動スケーリング エンドポイントに POST 要求を行います。
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
要求ペイロードでは適切なパラメーターを使用します。 enable Autoscale には、次の json ペイロードを使用できます。 自動スケーリングを無効にするには、ペイロード {autoscale: null} を使用します。
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
すべてのペイロード パラメーターの完全な説明については、前のセクションの負荷ベースの自動スケーリングの有効化を参照してください。 実行中のクラスターで自動スケーリング サービスを強制的に無効にすることはお勧めしません。
自動スケーリング アクティビティの監視
クラスターの状態
Azure portal に表示されるクラスターの状態は、自動スケーリング アクティビティの監視に役立ちます。
表示される可能性があるすべてのクラスター状態メッセージを、次の一覧で説明します。
| クラスターの状態 | 説明 |
|---|---|
| 実行中 | クラスターは正常に動作しています。 以前のすべての自動スケーリング アクティビティは、正常に完了しました。 |
| 更新中 | クラスターの自動スケーリング構成は更新されています。 |
| HDInsight 構成 | クラスターのスケールアップまたはスケールダウン操作が進行中です。 |
| 更新エラー | 自動スケーリング構成の更新中に HDInsight で問題が発生しました。 お客様は、更新の再試行または自動スケーリングの無効化を選択できます。 |
| エラー | クラスターに何らかの問題があり、使用できません。 このクラスターを削除し、新しいクラスターを作成してください。 |
クラスター内の現在のノード数を表示するには、クラスターの [概要] ページにある [クラスター サイズ] グラフに移動します。 または、 [設定] で [クラスター サイズ] を選択します。
操作の履歴
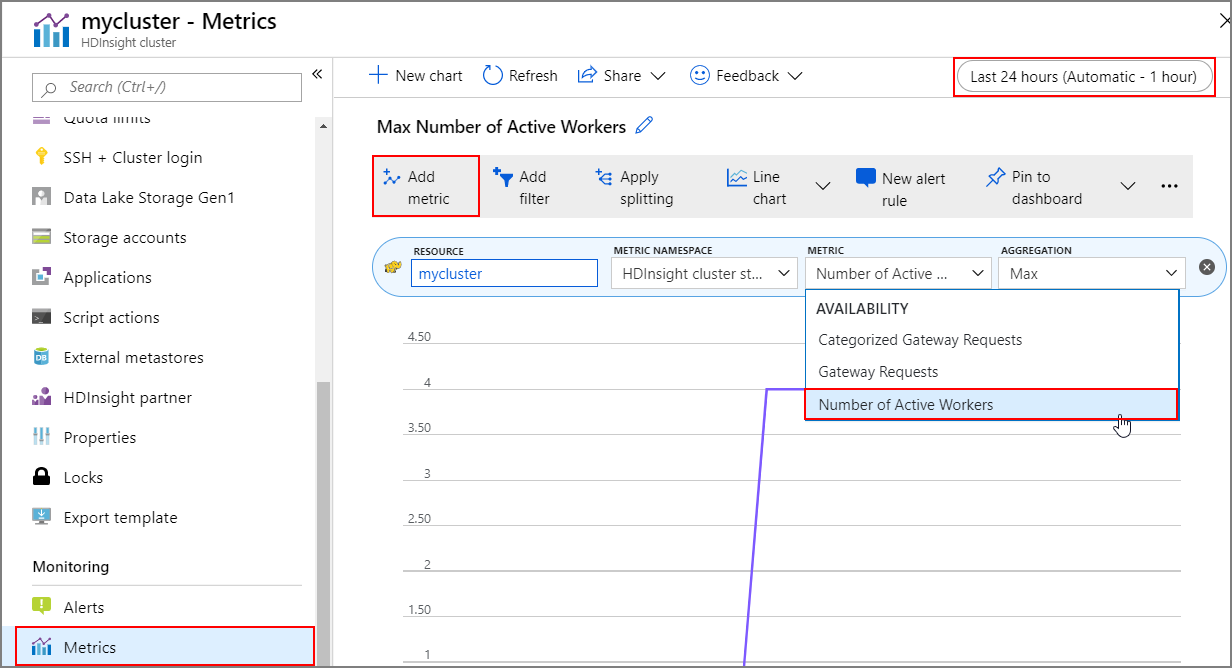
クラスター メトリックの一部として、クラスターのスケールアップおよびスケールダウンの履歴を表示できます。 また、過去の 1 日、1 週間、またはその他の期間中のすべてのスケーリング アクションを一覧表示することもできます。
[監視] で [メトリック] を選択します。 その後、 [メトリックの追加] を選択し、 [メトリック] ドロップダウン ボックスから [Number of Active Workers](アクティブなワーカーの数) を選択します。 右上にあるボタンを選択して、時間の範囲を変更します。
ベスト プラクティス
スケールアップ操作およびスケールダウン操作の待ち時間について検討する
スケーリング操作全体が完了するまでに、10 分から 20 分かかる場合があります。 カスタマイズしたスケジュールを設定する場合は、この遅延を考慮してください。 たとえば、午前 9 時にクラスター サイズを 20 にする必要がある場合は、スケーリング操作が午前 9 時までに完了するように、スケジュールのトリガーを午前 8 時 30 分以前などの早い時刻に設定する必要があります。
スケール ダウンを準備する
クラスターのスケール ダウン プロセス中、自動スケーリングはターゲット サイズを満たすためにノードを使用停止にします。 負荷ベースの自動スケーリングで、それらのノードでタスクが実行中の場合、自動スケーリングでは Spark および Hadoop クラスターに対するタスクが完了するまで待機します。 各ワーカー ノードは HDFS でのロールも果たすため、一時データは残りのワーカー ノードに移動されます。 残りのノードに、すべての一時データをホストするのに十分なスペースがあることを確認します。
Note
スケジュールに基づく自動スケーリングのスケールダウンの場合、正常な使用停止はサポートされていません。 これにより、スケールダウン操作中にジョブが失敗する可能性があります。予想されるジョブ スケジュール パターンに基づいてスケジュールを計画し、進行中のジョブが完了するための十分な時間を含めることをお勧めします。 ジョブの失敗を回避するために、完了時刻の履歴の分布を確認してスケジュールを設定できます。
使用パターンに基づいてスケジュールベースの自動スケーリングを構成する
スケジュールベースの自動スケーリングを構成する場合、クラスターの使用パターンを把握しておく必要があります。 Grafana ダッシュボードは、クエリの負荷と実行スロットを理解するのに役立ちます。 このダッシュボードから、利用可能な実行プログラム スロットと実行プログラム スロットの合計数を取得できます。
ここでは、必要なワーカー ノードの数を見積もる方法を示します。 変動するワークロードを処理するために、さらに 10% のバッファーを追加することをお勧めします。
使用される実行プログラム スロットの数 = 実行プログラム スロットの合計数 - 使用可能な実行プログラム スロットの合計数。
必要なワーカー ノードの数 = 実際に使用される実行プログラム スロットの数 / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size)。
*hive.llap.daemon.num.executors は構成可能であり、既定値は 4 です。
*hive.llap.daemon.task.scheduler.wait.queue.size は構成可能であり、既定値は 10 です。
カスタム スクリプトの操作
カスタム スクリプト アクションは、主にノード (HeadNode/WorkerNode) をカスタマイズするために使用されます。これにより、お客様が使用している特定のライブラリとツールを構成できます。 一般的な使用例の 1 つは、クラスター上で実行されるジョブが、顧客が所有するサードパーティ ライブラリに対して何らかの依存関係がある可能性があり、ジョブが成功するにはそれをノードで使用できる必要がある場合です。 現在、自動スケーリングでは、永続化されるカスタム スクリプト アクションがサポートされます。そのため、スケールアップ操作の一環として新しいノードがクラスターに追加されるたびに、これらの永続化されたスクリプト アクションが実行され、コンテナーまたはジョブがそれらに割り当てられることがポストされます。 カスタム スクリプト アクションを使用すると、新しいノードをブートストラップするのに役立ちますが、スケールアップの全体的な待機時間が長くなり、スケジュールされたジョブに影響を与える可能性があるので、最小限に抑えることをお勧めします。
クラスターの最小サイズに注意する
クラスターを 3 つ未満のノードにスケールダウンしないでください。 クラスターを 3 つ未満のノードにスケーリングすると、ファイル レプリケーションが不十分なためにセーフ モードでスタックする場合があります。 詳細については、「セーフ モードでスタックする」を参照してください。
Microsoft Entra Domain Services とスケーリング操作
Microsoft Entra Domain Services マネージド ドメインに参加している Enterprise セキュリティ パッケージ (ESP) で HDInsight クラスターを使用する場合は、Microsoft Entra Domain Services の負荷を調整することをお勧めします。 複雑なディレクトリ構造のスコープ付き同期では、スケーリング操作への影響を避けることをお勧めします。
ピーク時の使用状況シナリオに対する Hive 構成の同時実行クエリの最大合計数を設定する
Ambari では、Hive 構成の同時実行クエリの最大合計数は、自動スケーリング イベントによって変更されません。 つまり Hive Server 2 Interactive Service では、Interactive Query デーモンの数が負荷やスケジュールに基づいてスケールアップまたはスケールダウンされた場合でも、任意の時点で指定された数の同時実行クエリのみを処理できます。 一般的には、手動による介入を避けられるように、ピーク時の使用状況シナリオに合わせてこの構成を設定することをお勧めします。
ただし、ワーカー ノードが少数しかなく、同時実行クエリの最大合計数の値が非常に高く構成されている場合に、Hive Server 2 の再起動エラーが発生することがあります。 少なくとも、指定された数の Tez Ams に対応できるワーカー ノードの最小数が必要です (同時実行クエリの最大合計数の構成と同じ)。
制限事項
Interactive Query デーモン数
自動スケーリングが有効な Interactive Query クラスターの場合は、自動スケーリングのアップまたはダウン イベントによって、アクティブなワーカー ノードの数に合わせて Interactive Query デーモンの数もスケールアップまたはスケールダウンされます。 デーモンの数の変化は、Ambari の num_llap_nodes 構成には保持されません。 Hive サービスが手動で再起動された場合は、Ambari の構成に従って Interactive Query デーモンの数がリセットされます。
Interactive Query サービスが手動で再起動された場合、Advanced hive-interactive-env の下の num_llap_node 構成 (Hive Interactive Query デーモンを実行するために必要なノードの数) を手動で変更し、現在アクティブなワーカー ノードの数と一致させる必要があります。 Interactive Query クラスターでは、スケジュールベースの自動スケーリングのみがサポートされます。
次のステップ
クラスターを手動でスケーリングするためのガイドラインについては、スケーリングのガイドラインに関するページをお読みください。