Azure HDInsight にサードパーティ製 Apache Hadoop アプリケーションをインストールする
Azure HDInsight にサードパーティ製 Apache Hadoop アプリケーションをインストールする方法について説明します。 独自のアプリケーションのインストール手順については、カスタム HDInsight アプリケーションのインストールのページを参照してください。
HDInsight アプリケーションは、ユーザーが HDInsight クラスターにインストールできるアプリケーションです。 マイクロソフトや独立系ソフトウェア ベンダー (ISV) によって作成されるほか、ユーザーが独自に作成することもできます。
以下に、公開されているアプリケーションの一覧を示します。
| Application | クラスターのタイプ | 説明 |
|---|---|---|
| AtScale Intelligence Platform | Hadoop | AtScale では、HDInsight クラスターがスケールアウト OLAP サーバーに変換され、Microsoft Excel、Power BI、Tableau Software、QlikView など、ユーザーが既に所有し慣れ親しんでいる BI ツールを使用して、何十億ものデータ行を対話形式でクエリすることができます。 |
| Datameer | Hadoop | 分析用のデータを準備、調査、および管理するための Datameer のセルフサービスかつスケーラブルなプラットフォームでは、複雑なマルチソース データのビジネスに即応できる貴重な情報への転換を加速することにより、エンタープライズ クラスのより迅速で、より高度な洞察が可能になります。 |
| Dataiku DSS on HDInsight | Hadoop、Spark | エンタープライズ データ サイエンス プラットフォームの Dataiku DSS では、データ サイエンティストやデータ アナリストが共同作業を行い、新しいデータ製品およびサービスをより効率的に設計し実行して、生データをインパクトのある予測に変換することができます。 |
| WANdisco Fusion HDI App | Hadoop、Spark、HBase、Kafka | 分散環境でデータの一貫性を維持することは、データ操作における非常に重要な課題です。 WANdisco Fusion はエンタープライズクラスのソフトウェア プラットフォームであり、任意の環境全体で非構造化データの整合性を実現することにより、この問題を解決します。 |
| H2O SparklingWater for HDInsight | Spark | H2O Sparkling Water では、次の分散アルゴリズムがサポートされます。GLM、Naïve Bayes、Distributed Random Forest、Gradient Boosting Machine、Deep Neural Networks、Deep learning、K-means、PCA、Generalized Low Rank Models、Anomaly Detection、Autoencoders。 |
| Striim for Real-Time Data Integration to HDInsight | Hadoop、HBase、Spark、Kafka | Striim (発音は "ストリーム") は、エンド ツー エンドのストリーミング データ統合およびインテリジェンス プラットフォームで、これにより、異種のデータ ストリームの連続した取り込み、処理、および分析が可能になります。 |
| Jumbune Enterprise-Accelerating BigData Analytics | Hadoop、Spark | 大まかに言えば、Jumbune は次のように企業を支援します。1. Tez、MapReduce および Spark エンジン ベースの Hive、Java、Scala のワークロード パフォーマンスの加速化。 2. プロアクティブな Hadoop クラスターの監視。3. 分散ファイル システムでのデータ品質管理の確立。 |
| Kyligence Enterprise | Hadoop、HBase、Spark | Kyligence Enterprise では、Apache Kylin を活用して、ビッグ データでの BI を可能にします。 Hadoop 上のエンタープライズ OLAP エンジンである Kyligence Enterprise により、ビジネス アナリストは、業界標準のデータ ウェアハウスと BI 手法を使用して Hadoop で BI を設計することができます。 |
| StreamSets Data Collector for HDInsight Cloud | Hadoop、HBase、Spark、Kafka | StreamSets Data Collector は、リアルタイムでデータをストリーミングする軽量かつ強力なエンジンです。 Data Collector を使用して、データ ストリーム内のデータをルーティングおよび処理します。 30 日間の試用版ライセンスが付与されています。 |
| Trifacta Wrangler Enterprise | Hadoop、Spark、HBase | Trifacta Wrangler Enterprise for HDInsight では、あらゆる規模のデータに対して、エンタープライズ全体のデータ ラングリングがサポートされています。 Azure で Trifacta を実行するコストは、Trifacta サブスクリプションのコストと、仮想マシン用の Azure インフラストラクチャのコストとの組み合わせになります。 |
| Unifi Data Platform | Hadoop、HBase、Spark | Unifi Data Platform は、ビジネス ユーザーが増分収益を向上させ、コストや運用の複雑さを削減するというデータの課題に取り組めるように設計された、シームレスに統合されたセルフサービス データ ツールのスイートです。 |
この記事で説明する手順では、Azure Portal を使用します。 また、ポータルから Azure Resource Manager テンプレートをエクスポートしたり、ベンダーから Resource Manager テンプレートのコピーを入手したりして、Azure PowerShell と Azure クラシック CLI を使ってテンプレートをデプロイすることもできます。 「Apache Resource Manager テンプレートを使用して HDInsight に Hadoop クラスターを作成する」をご覧ください。
前提条件
既存の HDInsight クラスターに HDInsight アプリケーションをインストールする場合は、対象となる HDInsight クラスターが必要です。 新たに作成する場合は、「 クラスターの作成」を参照してください。 HDInsight クラスターを作成するときに HDInsight アプリケーションをインストールすることもできます。
既存のクラスターへのアプリケーションのインストール
次の手順では、既存の HDInsight クラスターに HDInsight アプリケーションをインストールする方法について説明します。
HDInsight アプリケーションをインストールする
Azure portal にサインインします。
左側のメニューで、 [すべてのサービス]>[分析]>[HDInsight クラスター] に移動します。
リストから HDInsight クラスターを選択します。 HDInsight クラスターがない場合は、最初に作成する必要があります。 「 クラスターの作成」を参照してください。
[設定] カテゴリで、[アプリケーション] を選択します。 メイン ウィンドウに、インストールされているアプリケーションの一覧が表示されます。
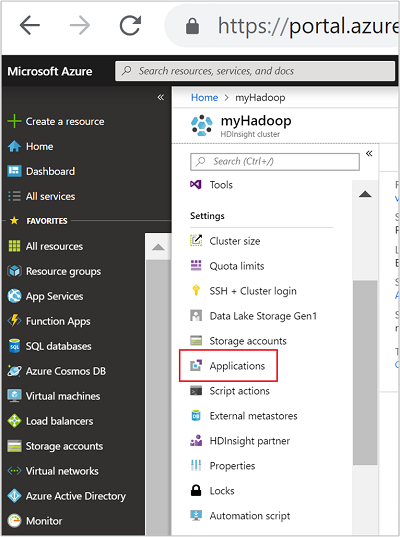
メニューで [+追加] を選択します。 使用できるアプリケーションの一覧が表示されます。 [+追加] が淡色表示されている場合は、このバージョンの HDInsight クラスターに対応するアプリケーションがないことを意味します。

いずれかの使用可能なアプリケーションを選択し、指示に従って法律条項を受け入れます。
インストールの状態はポータル通知で確認できます (ポータル上部のベル アイコンを選択)。 アプリケーションのインストール後、[インストール済みアプリ] 一覧にアプリケーションが表示されます。
クラスター作成時のアプリケーションのインストール
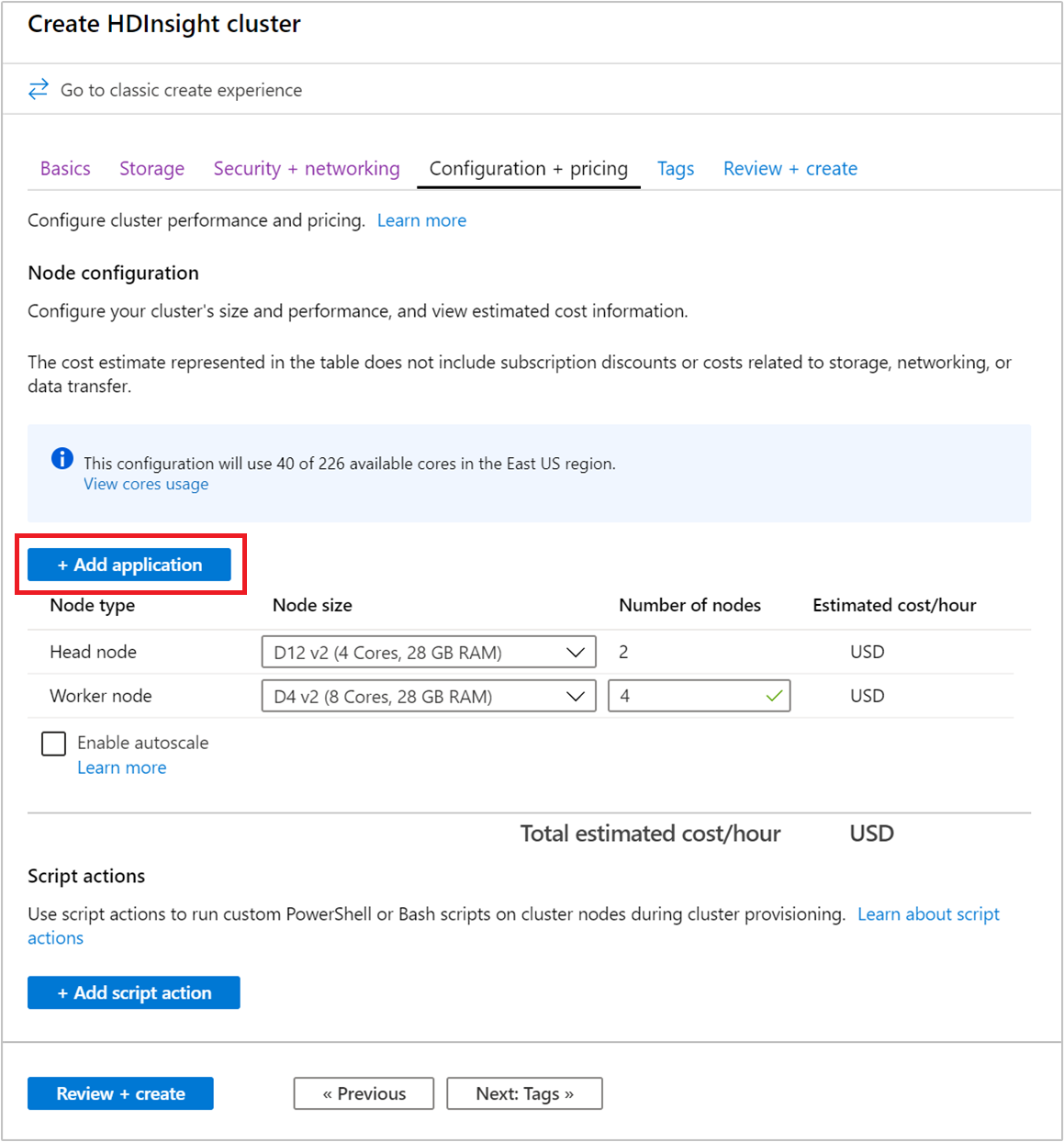
クラスターの作成時に HDInsight アプリケーションをインストールすることもできます。 このプロセスでは、クラスターが作成されて実行状態になった後に HDInsight アプリケーションがインストールされます。 Azure portal を使用してクラスターの作成中にアプリケーションをインストールするには、[構成と価格] タブで [+ アプリケーションの追加] を選択します。
インストール済み HDInsight アプリとプロパティの一覧表示
ポータルには、クラスターのインストール済み HDInsight アプリケーションのほか、インストール済みの各アプリケーションのプロパティが一覧で表示されます。
HDInsight アプリケーションを一覧表示し、プロパティを表示する
Azure portal にサインインします。
左側のメニューで、 [すべてのサービス]>[分析]>[HDInsight クラスター] に移動します。
リストから HDInsight クラスターを選択します。
[設定] カテゴリで、[アプリケーション] を選択します。 メイン ウィンドウに、インストールされているアプリケーションの一覧が表示されます。
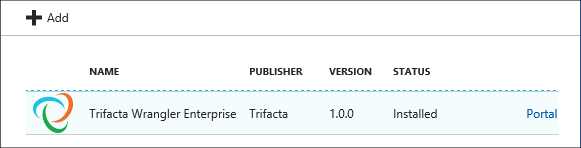
インストール済みのアプリケーションのいずれかを選択し、プロパティを表示します。 プロパティには次の項目が一覧表示されます。
プロパティ [説明] アプリ名 アプリケーション名。 Status アプリケーション ステータス。 Web ページ エッジ ノードにデプロイした Web アプリケーションの URL。 資格情報は、クラスター向けに構成した HTTP ユーザーの資格情報と同じです。 SSH エンドポイント SSH を使用してエッジ ノードに接続できます。 SSH 資格情報は、クラスター向けに構成した SSH ユーザーの資格情報と同じです。 詳細については、HDInsight での SSH の使用に関するページを参照してください。 説明 アプリケーションの説明。 アプリケーションを削除するには、アプリケーションを右クリックし、コンテキスト メニューの [削除] をクリックします。
エッジ ノードへの接続
HTTP と SSH を使用してエッジ ノードに接続できます。 エンドポイント情報は ポータルから確認できます。 詳細については、HDInsight での SSH の使用に関するページを参照してください。
HTTP エンドポイント資格情報は、HDInsight クラスター用に構成された HTTP ユーザー資格情報です。 SSH エンドポイント資格情報は、HDInsight クラスター用に構成された SSH 資格情報です。
トラブルシューティング
「 インストールのトラブルシューティング」を参照してください。
次のステップ
- カスタム HDInsight アプリケーションをインストールする: 未発行の HDInsight アプリケーションを HDInsight にデプロイする方法について確認します。
- HDInsight アプリケーションを発行する:カスタム HDInsight アプリケーションを Azure Marketplace に発行する方法について確認します。
- MSDN:HDInsight アプリケーションをインストールする:HDInsight アプリケーションを定義する方法を確認します。
- スクリプト アクションを使用して Linux ベースの HDInsight クラスターをカスタマイズする: スクリプト アクションを使用してアプリケーションを追加インストールする方法を確認します。
- Resource Manager テンプレートを使用して HDInsight で Linux ベースの Apache Hadoop クラスターを作成する: Resource Manager テンプレートを呼び出して HDInsight クラスターを作成する方法を確認します。
- HDInsight で空のエッジ ノードを使用する: HDInsight クラスター、テスト HDInsight アプリケーション、およびホスティング HDInsight アプリケーションにアクセスするために空のエッジ ノードを使用する方法を確認します。