HDInsight 上の Apache Hadoop の Apache Hive と Apache Pig で C# のユーザー定義関数を使用する
HDInsight 上の Apache Hive と Apache Pig で C# のユーザー定義関数 (UDF) を使用する方法について説明します。
重要
このドキュメントの手順は、Linux ベースの HDInsight クラスターに対してのみ有効です。 Linux は、バージョン 3.4 以上の HDInsight で使用できる唯一のオペレーティング システムです。 詳細については、「HDInsight コンポーネントのバージョン管理」を参照してください。
Hive と Pig では、両方とも、外部のアプリケーションにデータを渡して処理できます。 このプロセスは ストリーミング と呼ばれます。 .NET アプリケーションを使用する場合、データは STDIN 上のアプリケーションに渡され、そのアプリケーションから結果が STDOUT に返されます。 STDIN および STDOUT から読み取りと書き込みを実行する場合は、Console.ReadLine() と Console.WriteLine() をコンソール アプリケーションから使用できます。
前提条件
.NET Framework 4.5 を対象にした C# コードの記述と構築に精通していること。
必要なすべての IDE を使用します。 Visual Studioまたは Visual Studio Code をお勧めします。 このドキュメントの手順では、Visual Studio 2019 を使用します。
.exe ファイルをクラスターにアップロードして Pig と Hive のジョブを実行する方法。 Data Lake Tools for Visual Studio、Azure PowerShell、Azure CLI をお勧めします。 このドキュメントの手順では、Visual Studio の Data Lake ツールを使用して、ファイルをアップロードし、サンプルの Hive クエリを実行します。
Hive クエリを実行する他の方法については、「Azure HDInsight における Apache Hive と HiveQL」を参照してください。
HDInsight クラスターでの Hadoop。 クラスターの作成の詳細については、「HDInsight クラスターの作成」を参照してください。
HDInsight の .NET
Linux ベースの HDInsight クラスターでは、Mono (https://mono-project.com) を使用して .NET アプリケーションを実行します。 Mono バージョン 4.2.1 は HDInsight バージョン 3.6 に付属しています。
.NET Framework のバージョンと Mono の互換性の詳細については、「Mono compatibility」 (Mono の互換性) を参照してください。
HDInsight バージョンに付属する Mono と .NET Framework のバージョンの詳細については、HDInsight コンポーネントのバージョンに関するページを参照してください。
C# プロジェクトを作成する
以下のセクションでは、Apache Hive UDF と Apache Pig UDF 用に Visual Studio で C# プロジェクトを作成する方法について説明します。
Apache Hive UDF
Apache Hive UDF の C# プロジェクトを作成するには、次のようにします。
Visual Studio を起動します。
[新しいプロジェクトの作成] を選択します。
[新しいプロジェクトの作成] ウィンドウで、[コンソール アプリ (.NET Framework)] テンプレート (C# バージョン) を選択します。 次に、[次へ] を選択します。
[新しいプロジェクトを構成します] ウィンドウで、HiveCSharp のプロジェクト名を入力し、新しいプロジェクトを保存する場所に移動または場所を作成します。 [作成] を選択します。
Visual Studio IDE で、Program.cs の内容を次のコードに置き換えます。
using System; using System.Security.Cryptography; using System.Text; using System.Threading.Tasks; namespace HiveCSharp { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Parse the string, trimming line feeds // and splitting fields at tabs line = line.TrimEnd('\n'); string[] field = line.Split('\t'); string phoneLabel = field[1] + ' ' + field[2]; // Emit new data to stdout, delimited by tabs Console.WriteLine("{0}\t{1}\t{2}", field[0], phoneLabel, GetMD5Hash(phoneLabel)); } } /// <summary> /// Returns an MD5 hash for the given string /// </summary> /// <param name="input">string value</param> /// <returns>an MD5 hash</returns> static string GetMD5Hash(string input) { // Step 1, calculate MD5 hash from input MD5 md5 = System.Security.Cryptography.MD5.Create(); byte[] inputBytes = System.Text.Encoding.ASCII.GetBytes(input); byte[] hash = md5.ComputeHash(inputBytes); // Step 2, convert byte array to hex string StringBuilder sb = new StringBuilder(); for (int i = 0; i < hash.Length; i++) { sb.Append(hash[i].ToString("x2")); } return sb.ToString(); } } }メニュー バーで [ビルド]>[ソリューションのビルド] の順に選択して、プロジェクトをビルドします。
ソリューションを閉じます。
Apache Pig UDF
Apache Hive UDF の C# プロジェクトを作成するには、次のようにします。
Visual Studio を開きます。
[開始] ウィンドウで、 [新しいプロジェクトの作成] を選択します。
[新しいプロジェクトの作成] ウィンドウで、[コンソール アプリ (.NET Framework)] テンプレート (C# バージョン) を選択します。 次に、[次へ] を選択します。
[新しいプロジェクトを構成します] ウィンドウで、PigUDF のプロジェクト名を入力し、新しいプロジェクトを保存する場所に移動または場所を作成します。 [作成] を選択します。
Visual Studio IDE で、Program.cs の内容を次のコードに置き換えます。
using System; namespace PigUDF { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Fix formatting on lines that begin with an exception if(line.StartsWith("java.lang.Exception")) { // Trim the error info off the beginning and add a note to the end of the line line = line.Remove(0, 21) + " - java.lang.Exception"; } // Split the fields apart at tab characters string[] field = line.Split('\t'); // Put fields back together for writing Console.WriteLine(String.Join("\t",field)); } } } }このコードは、Pig から送信された行を解析し、
java.lang.Exceptionで始まる行を再フォーマットします。メニュー バーから [ビルド]>[ソリューションのビルド] を選択してプロジェクトをビルドします。
ソリューションを開いたままにしておきます。
ストレージにアップロードする
次に、Hive と Pig の UDF アプリケーションを HDInsight クラスター上のストレージにアップロードします。
Visual Studio で、 [表示]>[サーバー エクスプローラー] の順に移動します。
[サーバー エクスプローラー] で、[Azure] を右クリックし、[Microsoft Azure サブスクリプションへの接続] を選択し、サインイン処理を完了します。
このアプリケーションをデプロイする HDInsight クラスターを展開します。 エントリとテキスト (既定のストレージ アカウント) が一覧表示されます。
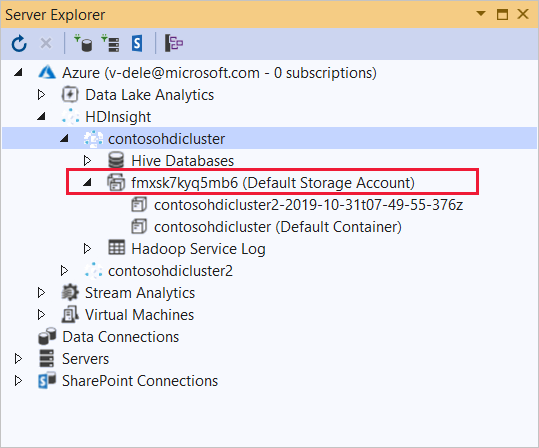
このエントリを展開できる場合は、クラスターの既定のストレージとして Azure ストレージ アカウントを使用します。 クラスターの既定のストレージにファイルを表示するには、エントリを展開し、[(既定のコンテナー)] をダブルクリックします。
このエントリを展開できない場合は、クラスターの既定のストレージとして Azure Data Lake Storage を使用します。 クラスターの既定のストレージにファイルを表示するには、 (既定のストレージ アカウント) エントリをダブルクリックします。
.exe ファイルをアップロードするには、次のいずれかの方法を使用します。
Azure ストレージ アカウントを使用している場合は、 [BLOB のアップロード] アイコンを選択します。

[新しいファイルのアップロード] ダイアログ ボックスの [ファイル名] で、 [参照] を選択します。 [BLOB のアップロード] ダイアログ ボックスで、HiveCSharp プロジェクトの
bin\debugフォルダーに移動し、HiveCSharp.exe ファイルを選択します。 最後に、 [開く] を選択し、 [OK] を選択してアップロードを完了します。Azure Data Lake Storage を使用している場合は、ファイルの一覧の空の領域を右クリックし、[アップロード] を選択します。 最後に、HiveCSharp.exe ファイルを選び、[OK] を選択します。
HiveCSharp.exe のアップロードが完了したら、PigUDF.exe ファイルのアップロード プロセスを繰り返します。
Apache Hive クエリを実行する
Hive UDF アプリケーションを使用する Hive クエリを実行できるようになりました。
Visual Studio で、 [表示]>[サーバー エクスプローラー] の順に移動します。
[Azure] を展開して、[HDInsight] を展開します。
HiveCSharp アプリケーションをデプロイしたクラスターを右クリックし、[Write a Hive Query] を選択します。
Hive クエリには、次のテキストを使用します。
-- Uncomment the following if you are using Azure Storage -- add file wasbs:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen1 -- add file adl:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen2 -- add file abfs:///HiveCSharp.exe; SELECT TRANSFORM (clientid, devicemake, devicemodel) USING 'HiveCSharp.exe' AS (clientid string, phoneLabel string, phoneHash string) FROM hivesampletable ORDER BY clientid LIMIT 50;重要
クラスターに使用した既定のストレージの種類に一致する
add fileステートメントのコメントを解除します。このクエリは、
hivesampletableからclientid、devicemake、devicemodelの各フィールドを選択し、HiveCSharp.exe アプリケーションに選択したフィールドを渡します。 クエリはアプリケーションが 3 つのフィールドを返すことを想定し、これはclientid、phoneLabel、phoneHashとして格納されます。 このクエリでは、既定のストレージ コンテナーのルートで HiveCSharp.exe が見つかることを想定しています。既定の [対話型] を [バッチ] に切り替えてから、[送信] を選択して、ジョブを HDInsight クラスターに送信します。 [Hive ジョブの概要] ウィンドウが開きます。
[更新] を選択し、[ジョブの状態] が [完了] に変わるまで概要を更新します。 ジョブの出力を表示するには、[ジョブの出力] を選択します。
Apache Pig ジョブを実行する
Pig UDF アプリケーションを使用する Pig ジョブを実行することもできます。
SSH を使用して、HDInsight クラスターに接続します。 (たとえば、コマンド
ssh sshuser@<clustername>-ssh.azurehdinsight.netを実行します。) 詳細については、HDInsight での SSH の使用に関するページを参照してください。次のコマンドを使用して、Pig コマンド ラインを開始します。
piggrunt>プロンプトが表示されます。.NET Framework アプリケーションを使用する Pig ジョブを実行するには、次のように入力します。
DEFINE streamer `PigUDF.exe` CACHE('/PigUDF.exe'); LOGS = LOAD '/example/data/sample.log' as (LINE:chararray); LOG = FILTER LOGS by LINE is not null; DETAILS = STREAM LOG through streamer as (col1, col2, col3, col4, col5); DUMP DETAILS;DEFINEステートメントで PigUDF.exe アプリケーションのstreamerというエイリアスを作成し、それをCACHEでクラスターの既定のストレージから読み込みます。 その後、streamerがSTREAM演算子で使用され、LOGに含まれる単一行が処理されて、一連の列としてデータが返されます。注意
ストリーミングで使用されるアプリケーション名は、エイリアスを使用する場合は
`(バッククォート) 文字、SHIPで使用する場合は'(一重引用符) 文字で囲む必要があります。最後の行を入力すると、ジョブが開始されます。 次のテキストのような出力が返されます。
(2019-07-15 16:43:25 SampleClass5 [WARN] problem finding id 1358451042 - java.lang.Exception) (2019-07-15 16:43:25 SampleClass5 [DEBUG] detail for id 1976092771) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1317358561) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1737534798) (2019-07-15 16:43:25 SampleClass7 [DEBUG] detail for id 1475865947)exitを使用して、pig を終了します。
次のステップ
このドキュメントでは、HDInsight の Hive と Pig から .NET Framework アプリケーションを使用する方法について説明しました。 Hive と Pig で Python を使用する方法について学習するには、HDInsight における Apache Hive および Apache Pig での Python の使用に関するページを参照してください。
Hive を使用する他の方法と、MapReduce の使用方法については、以下の記事をご覧ください。