Esercitazione per l'API WebNN
Per un'introduzione a WebNN, incluse informazioni sul supporto del sistema operativo, sul supporto dei modelli e altro ancora, visitare la panoramica di WebNN.
Questa esercitazione illustra come usare l'API WebNN per creare un sistema di classificazione delle immagini sul Web accelerato tramite GPU su dispositivo. Verrà usato il modello MobileNetv2 , che è un modello open source in Hugging Face usato per classificare le immagini.
Per visualizzare ed eseguire il codice finale di questa esercitazione, è possibile trovarlo in GitHub webNN Developer Preview.
Nota
L'API WebNN è una raccomandazione per i candidati W3C e si trova nelle prime fasi di un'anteprima per sviluppatori. Alcune funzionalità sono limitate. È disponibile un elenco dello stato corrente di supporto e implementazione.
Requisiti e configurazione:
Configurazione di Windows
Assicurarsi di disporre delle versioni corrette dei driver edge, Windows e hardware, come descritto nella sezione Requisiti WebNN.
Configurazione di Edge
Scaricare e installare Microsoft Edge Dev.
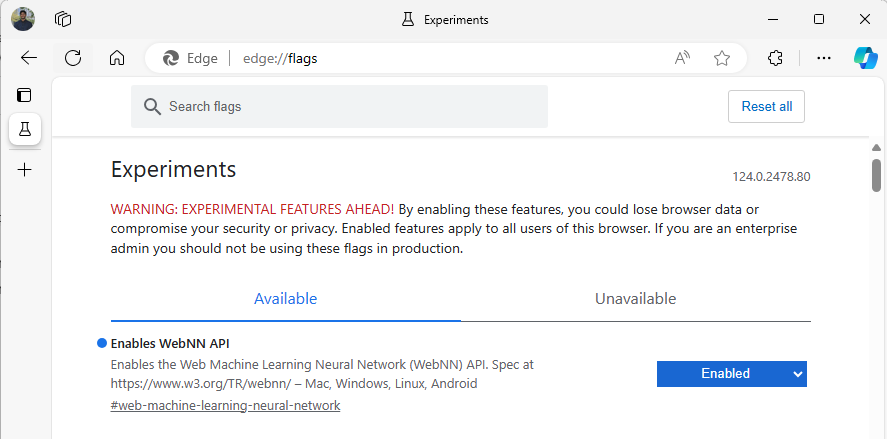
Avviare Edge Beta e passare a
about:flagsnella barra degli indirizzi.Cercare "API WebNN", fare clic sull'elenco a discesa e impostare su "Enabled".
Riavviare Edge, come richiesto.
Configurazione dell'ambiente per sviluppatori
Scaricare e installare Visual Studio Code (VSCode).
Avviare VSCode.
Scaricare e installare l'estensione Live Server per VSCode all'interno di VSCode.
Selezionare
File --> Open Foldere creare una cartella vuota nel percorso desiderato.
Passaggio 1: Inizializzare l'app Web
- Per iniziare, creare una nuova
index.htmlpagina. Aggiungere il codice boilerplate seguente alla nuova pagina:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
</head>
<body>
<main>
<h1>Welcome to My Website</h1>
</main>
</body>
</html>
- Verificare che il codice boilerplate e la configurazione dello sviluppatore funzionino selezionando il pulsante Go Live sul lato inferiore destro di VSCode. Verrà avviato un server locale in Edge Beta che esegue il codice boilerplate.
- Creare ora un nuovo file denominato
main.js. Questo conterrà il codice javascript per l'app. - Creare quindi una sottocartella dalla directory radice denominata
images. Scaricare e salvare qualsiasi immagine all'interno della cartella. Per questa demo si userà il nome predefinito diimage.jpg. - Scaricare il modello mobilenet dallo zoo del modello ONNX. Per questa esercitazione si userà il file mobilenet2-10.onnx . Salvare questo modello nella cartella radice dell'app Web.
- Infine, scaricare e salvare il file delle classi di immagini,
imagenetClasses.js. In questo modo sono disponibili 1000 classificazioni comuni di immagini da usare per il modello.
Passaggio 2: Aggiungere elementi dell'interfaccia utente e funzione padre
- Nel corpo dei
<main>tag HTML aggiunti nel passaggio precedente sostituire il codice esistente con gli elementi seguenti. Verranno creati un pulsante e verrà visualizzata un'immagine predefinita.
<h1>Image Classification Demo!</h1>
<div><img src="./images/image.jpg"></div>
<button onclick="classifyImage('./images/image.jpg')" type="button">Click Me to Classify Image!</button>
<h1 id="outputText"> This image displayed is ... </h1>
- A questo punto, si aggiungerà ONNX Runtime Web alla pagina, ovvero una libreria JavaScript che verrà usata per accedere all'API WebNN. All'interno del corpo dei
<head>tag HTML aggiungere i collegamenti di origine javascript seguenti.
<script src="./main.js"></script>
<script src="imagenetClasses.js"></script>
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.18.0-dev.20240311-5479124834/dist/ort.webgpu.min.js"></script>
- Aprire il
main.jsfile e aggiungere il frammento di codice seguente.
async function classifyImage(pathToImage){
var imageTensor = await getImageTensorFromPath(pathToImage); // Convert image to a tensor
var predictions = await runModel(imageTensor); // Run inference on the tensor
console.log(predictions); // Print predictions to console
document.getElementById("outputText").innerHTML += predictions[0].name; // Display prediction in HTML
}
Passaggio 3: Pre-elaborare i dati
- La funzione appena aggiunta chiama
getImageTensorFromPath, un'altra funzione da implementare. Verrà aggiunto di seguito, oltre a un'altra funzione asincrona che chiama per recuperare l'immagine stessa.
async function getImageTensorFromPath(path, width = 224, height = 224) {
var image = await loadImagefromPath(path, width, height); // 1. load the image
var imageTensor = imageDataToTensor(image); // 2. convert to tensor
return imageTensor; // 3. return the tensor
}
async function loadImagefromPath(path, resizedWidth, resizedHeight) {
var imageData = await Jimp.read(path).then(imageBuffer => { // Use Jimp to load the image and resize it.
return imageBuffer.resize(resizedWidth, resizedHeight);
});
return imageData.bitmap;
}
- È anche necessario aggiungere la
imageDataToTensorfunzione a cui si fa riferimento in precedenza, che eseguirà il rendering dell'immagine caricata in un formato tensore che funzionerà con il modello ONNX. Questa è una funzione più coinvolta, anche se potrebbe sembrare familiare se si è lavorato con app di classificazione delle immagini simili in precedenza. Per una spiegazione estesa, è possibile visualizzare questa esercitazione ONNX.
function imageDataToTensor(image) {
var imageBufferData = image.data;
let pixelCount = image.width * image.height;
const float32Data = new Float32Array(3 * pixelCount); // Allocate enough space for red/green/blue channels.
// Loop through the image buffer, extracting the (R, G, B) channels, rearranging from
// packed channels to planar channels, and converting to floating point.
for (let i = 0; i < pixelCount; i++) {
float32Data[pixelCount * 0 + i] = imageBufferData[i * 4 + 0] / 255.0; // Red
float32Data[pixelCount * 1 + i] = imageBufferData[i * 4 + 1] / 255.0; // Green
float32Data[pixelCount * 2 + i] = imageBufferData[i * 4 + 2] / 255.0; // Blue
// Skip the unused alpha channel: imageBufferData[i * 4 + 3].
}
let dimensions = [1, 3, image.height, image.width];
const inputTensor = new ort.Tensor("float32", float32Data, dimensions);
return inputTensor;
}
Passaggio 4: Chiamare WebNN
- A questo punto sono state aggiunte tutte le funzioni necessarie per recuperare l'immagine ed eseguirne il rendering come tensore. A questo punto, usando la libreria Web ONNX Runtime caricata in precedenza, si eseguirà il modello. Si noti che per usare WebNN, è sufficiente specificare
executionProvider = "webnn": il supporto di ONNX Runtime rende molto semplice abilitare WebNN.
async function runModel(preprocessedData) {
// Set up environment.
ort.env.wasm.numThreads = 1;
ort.env.wasm.simd = true;
ort.env.wasm.proxy = true;
ort.env.logLevel = "verbose";
ort.env.debug = true;
// Configure WebNN.
const executionProvider = "webnn"; // Other options: webgpu
const modelPath = "./mobilenetv2-7.onnx"
const options = {
executionProviders: [{ name: executionProvider, deviceType: "gpu", powerPreference: "default" }],
freeDimensionOverrides: {"batch": 1, "channels": 3, "height": 224, "width": 224}
};
modelSession = await ort.InferenceSession.create(modelPath, options);
// Create feeds with the input name from model export and the preprocessed data.
const feeds = {};
feeds[modelSession.inputNames[0]] = preprocessedData;
// Run the session inference.
const outputData = await modelSession.run(feeds);
// Get output results with the output name from the model export.
const output = outputData[modelSession.outputNames[0]];
// Get the softmax of the output data. The softmax transforms values to be between 0 and 1.
var outputSoftmax = softmax(Array.prototype.slice.call(output.data));
// Get the top 5 results.
var results = imagenetClassesTopK(outputSoftmax, 5);
return results;
}
Passaggio 5: Post-elaborazione dei dati
- Infine, si aggiungerà una
softmaxfunzione, quindi si aggiungerà la funzione finale per restituire la classificazione delle immagini più probabile. Trasformasoftmaxi valori in modo che siano compresi tra 0 e 1, ovvero il formato di probabilità necessario per questa classificazione finale.
Aggiungere prima di tutto i file di origine seguenti per le librerie helper Jimp e Lodash nel tag head di main.js.
<script src="https://cdnjs.cloudflare.com/ajax/libs/jimp/0.22.12/jimp.min.js" integrity="sha512-8xrUum7qKj8xbiUrOzDEJL5uLjpSIMxVevAM5pvBroaxJnxJGFsKaohQPmlzQP8rEoAxrAujWttTnx3AMgGIww==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
Aggiungere ora queste funzioni seguenti a main.js.
// The softmax transforms values to be between 0 and 1.
function softmax(resultArray) {
// Get the largest value in the array.
const largestNumber = Math.max(...resultArray);
// Apply the exponential function to each result item subtracted by the largest number, using reduction to get the
// previous result number and the current number to sum all the exponentials results.
const sumOfExp = resultArray
.map(resultItem => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
// Normalize the resultArray by dividing by the sum of all exponentials.
// This normalization ensures that the sum of the components of the output vector is 1.
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp
});
}
function imagenetClassesTopK(classProbabilities, k = 5) {
const probs = _.isTypedArray(classProbabilities)
? Array.prototype.slice.call(classProbabilities)
: classProbabilities;
const sorted = _.reverse(
_.sortBy(
probs.map((prob, index) => [prob, index]),
probIndex => probIndex[0]
)
);
const topK = _.take(sorted, k).map(probIndex => {
const iClass = imagenetClasses[probIndex[1]]
return {
id: iClass[0],
index: parseInt(probIndex[1].toString(), 10),
name: iClass[1].replace(/_/g, " "),
probability: probIndex[0]
}
});
return topK;
}
- Sono stati aggiunti tutti gli script necessari per eseguire la classificazione delle immagini con WebNN nell'app Web di base. Usando l'estensione Live Server per VS Code, è ora possibile avviare la pagina Web di base in-app per visualizzare automaticamente i risultati della classificazione.