Problema con la rimozione dei nodi dall'appartenenza al cluster di failover attivo
Questo articolo illustra come risolvere i problemi in cui i nodi vengono rimossi dall'appartenenza al cluster di failover attiva in modo casuale.
Sintomi
Quando si verifica il problema, vengono visualizzati eventi come questo evento registrato nel registro eventi di sistema:
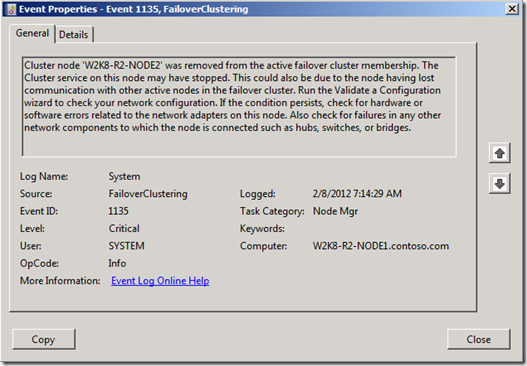
Questo evento viene registrato in tutti i nodi del cluster, ad eccezione del nodo rimosso. Il motivo di questo evento è dovuto al fatto che uno dei nodi nel cluster ha contrassegnato il nodo come inattivo. Invia quindi una notifica a tutti gli altri nodi dell'evento. Quando i nodi ricevono una notifica, interrompono e eliminano le connessioni heartbeat al nodo inattivo.
Cosa ha causato la chiusura del nodo
Tutti i nodi di un cluster di failover di Windows Server comunicano tra loro sulle reti impostate per consentire la comunicazione di rete del cluster in questa rete. I nodi inviano pacchetti heartbeat tra queste reti a tutti gli altri nodi. Questi pacchetti devono essere ricevuti dagli altri nodi e quindi viene inviata una risposta. Ogni nodo del cluster ha heartbeat propri che monitorerà per assicurarsi che la rete sia attivata e che gli altri nodi siano in funzione. L'esempio seguente dovrebbe aiutare a chiarire questo comportamento:
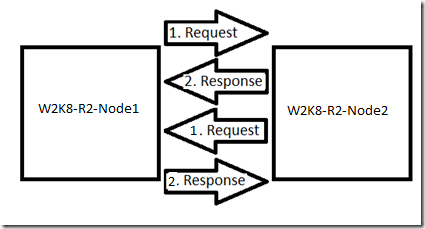
Se uno di questi pacchetti non viene restituito, l'heartbeat specifico viene considerato non riuscito. Ad esempio, W2K8-R2-NODE2 invia una richiesta e riceve una risposta da W2K8-R2-NODE1 a un pacchetto heartbeat in modo da determinare la rete e il nodo è attivo. Se W2K8-R2-NODE1 invia una richiesta a W2K8-R2-NODE2 e W2K8-R2-NODE1 non ottiene la risposta, viene considerato un heartbeat perso e W2K8-R2-NODE1 ne tiene traccia. Questa risposta persa può avere W2K8-R2-NODE1 mostrare la rete come inattiva fino a quando non viene ricevuta un'altra richiesta heartbeat.
Per impostazione predefinita, i nodi del cluster hanno un limite di cinque errori in 5 secondi prima che la connessione venga contrassegnata come inattiva. Pertanto, se W2K8-R2-NODE1 non riceve la risposta cinque volte nel periodo di tempo, considera che una particolare route a W2K8-R2-NODE2 sia inattiva. Se altre route sono ancora considerate attive, W2K8-R2-NODE2 rimarrà come membro attivo.
Se tutte le route sono contrassegnate come inattivi per W2K8-R2-NODE2, vengono rimosse dall'appartenenza al cluster di failover attivo e viene registrato l'evento 1135 visualizzato nella prima sezione. In W2K8-R2-NODE2 il servizio cluster viene terminato e quindi riavviato in modo da poter provare a ricongiurre il cluster.
Per altre informazioni su come gestire route specifiche inattiva con tre o più nodi, vedere il blog "Partitioned" Cluster Networks (Reti cluster partizionate) scritto da Jeff Hughes.
Ora che sappiamo come funziona il processo heartbeat, quali sono alcune delle cause note che causano l'esito negativo del processo
Errori hardware di rete effettivi. Se il pacchetto viene perso in transito tra i nodi, gli heartbeat hanno esito negativo. Verrà visualizzata una traccia di rete da entrambi i nodi coinvolti.
Il profilo per le connessioni di rete potrebbe essere di nuovo in grado di passare da Dominio a Pubblico e tornare a Dominio. Durante la transizione di queste modifiche, le operazioni di I/O di rete possono essere bloccate. È possibile verificare se questo è il caso esaminando il log operativo del profilo di rete. È possibile trovare questo log aprendo il Visualizzatore eventi e passando a Registri applicazioni e servizi\Microsoft\Windows\NetworkProfile\Operational. Esaminare gli eventi in questo log sul nodo menzionato nell'ID evento 1135 e verificare se il profilo è stato modificato in questo momento. In tal caso, vedi Il profilo del percorso di rete passa da "Dominio" a "Pubblico" in Windows 7 o in Windows Server 2008 R2.
IPv6 è abilitato nei server, ma sono disabilitate le due regole seguenti per Inbound e Outbound in Windows Firewall:
- Rete principale - Annuncio individuazione adiacente
- Core Networking - Neighbor Discovery Solicitation
Anche il software antivirus potrebbe interferire con questo processo. Se si sospetta questo problema, eseguire il test disabilitando o disinstallando il software. Fai questo a tuo rischio perché sei non protetto da virus a questo punto.
La latenza nella rete potrebbe anche causare questo problema. I pacchetti potrebbero non andare persi tra i nodi, ma potrebbero non arrivare ai nodi abbastanza velocemente prima della scadenza del periodo di timeout.
IPv6 è il protocollo predefinito che clustering di failover userà per i relativi heartbeat. L'heartbeat stesso è un pacchetto di rete unicast UDP che comunica sulla porta 3343. Se sono presenti commutatori, firewall o router non configurati correttamente per consentire questo traffico, è possibile riscontrare problemi come questo.
Gli aggiornamenti dei criteri di sicurezza IPsec possono anche causare questo problema. Il problema specifico è che durante l'aggiornamento di criteri di gruppo IPSec tutte le associazioni di sicurezza IPsec (SA) vengono eliminate da Windows Firewall con sicurezza avanzata (WFAS). In questo caso, tutta la connettività di rete è bloccata. Quando si rinegoziano le associazioni di sicurezza in caso di ritardi nell'esecuzione dell'autenticazione con Active Directory, questi ritardi (in cui tutte le comunicazioni di rete sono bloccate) bloccano anche l'attraversamento degli heartbeat del cluster e causano il rilevamento dell'integrità del cluster come inattivo se non rispondono entro la soglia di 5 secondi.
Driver e/o firmware delle schede di rete precedenti o non aggiornati. A volte, una semplice configurazione errata della scheda di rete o del commutatore può anche causare la perdita di heartbeat.
Le schede di rete e le schede di rete virtuali moderne potrebbero riscontrare perdite di pacchetti. È possibile tenere traccia aprendo Monitor prestazioni e aggiungendo il contatore "Network Interface\Packets Received Discarded". Questo contatore è cumulativo e aumenta solo fino al riavvio del server. La visualizzazione di un numero elevato di pacchetti eliminati qui potrebbe essere un segno che i buffer di ricezione nella scheda di rete sono impostati troppo bassi o che il server sta eseguendo lentamente e non è in grado di gestire il traffico in ingresso. Ogni produttore di schede di rete sceglie se esporre queste impostazioni nelle proprietà della scheda di rete, pertanto è necessario fare riferimento al sito Web del produttore per informazioni su come aumentare questi valori e i valori consigliati devono essere usati. Se si esegue VMware, il blog seguente illustra questo aspetto in modo più dettagliato, tra cui come stabilire se si tratta del problema, oltre a fare riferimento all'articolo VMware sulle impostazioni da modificare.
Nodi rimossi dall'appartenenza al cluster di failover in VMware ESX
Questi sono i motivi più comuni per cui questi eventi vengono registrati, ma potrebbero esserci anche altri motivi. Il punto di questo blog è stato quello di fornire alcune informazioni dettagliate sul processo e anche dare idee su cosa cercare. Alcuni genereranno i valori seguenti ai valori massimi per tentare di arrestare il problema.
| Parametro | Predefiniti | Intervallo |
|---|---|---|
| SameSubnetDelay | 1000 millisecondi | 250-2000 millisecondi |
| CrossSubnetDelay | 1000 millisecondi | 250-4000 millisecondi |
| SameSubnetThreshold | 5 | 3-10 |
| CrossSubnetThreshold | 5 | 3-10 |
Aumentando questi valori al massimo, è possibile che l'evento e la rimozione del nodo vengano rimossi, ma maschera il problema. Non risolve nulla. La cosa migliore da fare è scoprire la causa radice degli errori di heartbeat e ottenere il problema risolto. L'unica vera necessità di aumentare questi valori è in uno scenario multisito in cui i nodi si trovano in posizioni diverse e la latenza di rete non possono essere superate.