Risolvere i problemi relativi alle query lente interessate dal timeout di Query Optimizer
Si applica a: SQL Server
Questo articolo presenta il timeout di Optimizer, come può influire sulle prestazioni delle query e come ottimizzare le prestazioni.
Che cos'è il timeout di Optimizer?
SQL Server usa query Optimizer (QO) basato sui costi. Per informazioni su QO, vedere Guida all'architettura di elaborazione delle query. Query Optimizer basato sui costi seleziona un piano di esecuzione di query con il costo più basso dopo la compilazione e la valutazione di più piani di query. Uno degli obiettivi di SQL Server Query Optimizer consiste nel dedicare un tempo ragionevole all'ottimizzazione delle query rispetto all'esecuzione di query. L'ottimizzazione di una query deve essere molto più veloce rispetto all'esecuzione. Per raggiungere questa destinazione, QO ha una soglia predefinita di attività da considerare prima di arrestare il processo di ottimizzazione. Quando la soglia viene raggiunta prima che QO abbia considerato tutti i piani possibili, raggiunge il limite di timeout di Optimizer. Un evento timeout di Optimizer viene segnalato nel piano di query come TimeOut in Motivo della chiusura anticipata dell'ottimizzazione delle istruzioni. È importante comprendere che questa soglia non è basata sull'ora dell'orologio, ma sul numero di possibilità considerate dall'ottimizzatore. Nelle versioni correnti di QO di SQL Server, oltre mezzo milione di attività vengono considerate prima che venga raggiunto un timeout.
Il timeout di Optimizer è progettato in SQL Server e, in molti casi, non è un fattore che influisce sulle prestazioni delle query. In alcuni casi, tuttavia, la scelta del piano di query SQL potrebbe essere influenzata negativamente dal timeout di Optimizer e le prestazioni delle query più lente potrebbero risultare. Quando si verificano problemi di questo tipo, comprendere il meccanismo di timeout di Optimizer e il modo in cui è possibile influire sulle query complesse può essere utile per risolvere i problemi e migliorare la velocità delle query.
Il risultato del raggiungimento della soglia di timeout di Optimizer è che SQL Server non ha considerato l'intero set di possibilità di ottimizzazione. Ciò significa che potrebbero non essere stati pianificati che potrebbero produrre tempi di esecuzione più brevi. QO si arresterà alla soglia e considererà il piano di query meno costoso a quel punto, anche se potrebbero esserci opzioni migliori e inesplorate. Tenere presente che il piano selezionato dopo il raggiungimento di un timeout di Optimizer può produrre una durata di esecuzione ragionevole per la query. In alcuni casi, tuttavia, il piano selezionato potrebbe comportare un'esecuzione di query non ottimale.
Come rilevare un timeout di Optimizer?
Ecco i sintomi che indicano un timeout di Optimizer:
Query complessa
Si dispone di una query complessa che coinvolge un numero elevato di tabelle unite ( ad esempio, otto o più tabelle sono unite in join).
Query lenta
La query può essere eseguita lentamente o più lenta rispetto all'esecuzione in un'altra versione o sistema di SQL Server.
Il piano di query mostra StatementOptmEarlyAbortReason=Timeout
Il piano di query viene visualizzato
StatementOptmEarlyAbortReason="TimeOut"nel piano di query XML.<?xml version="1.0" encoding="utf-16"?> <ShowPlanXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" Version="1.518" Build="13.0.5201.2" xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan"> <BatchSequence> <Batch> <Statements> <StmtSimple ..." StatementOptmLevel="FULL" StatementOptmEarlyAbortReason="TimeOut" ......> ... <Statements> <Batch> <BatchSequence>Controllare le proprietà dell'operatore di piano più a sinistra in Microsoft SQL Server Management Studio. Il valore di Reason For Early Termination of Statement Optimization è TimeOut.
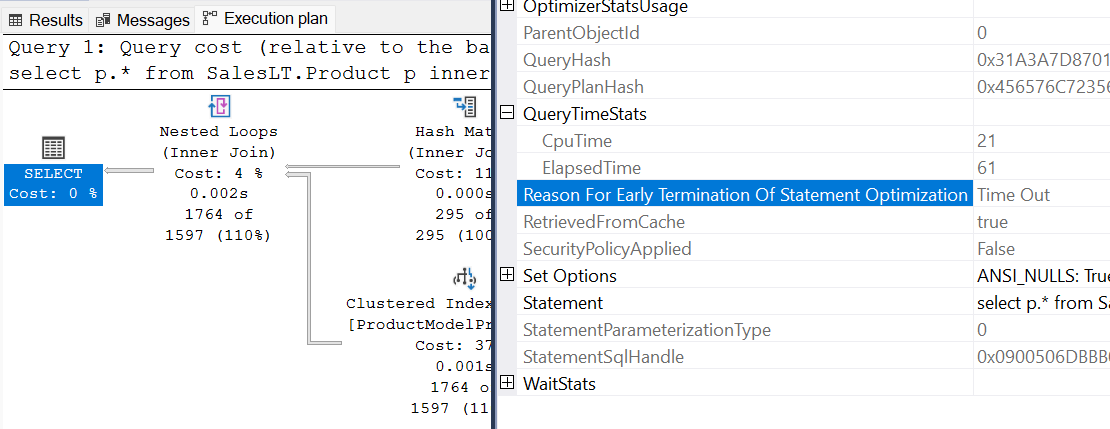
Che cosa causa un timeout di Optimizer?
Non esiste un modo semplice per determinare quali condizioni causerebbero il raggiungimento o il superamento della soglia dell'utilità di ottimizzazione. Le sezioni seguenti sono alcuni fattori che influiscono sul numero di piani esplorati dal QO quando si cerca il piano migliore.
In quale ordine devono essere unite tabelle?
Di seguito è riportato un esempio delle opzioni di esecuzione di join a tre tabelle (
Table1,Table2,Table3):- Creare un join
Table1conTable2e il risultato conTable3 - Creare un join
Table1conTable3e il risultato conTable2 - Creare un join
Table2conTable3e il risultato conTable1
Nota: maggiore è il numero di tabelle, maggiori sono le possibilità.
- Creare un join
Quale struttura di accesso ad heap o albero binario (HoBT) usare per recuperare le righe da una tabella?
- Indice cluster
- Indice non cluster1
- Indice non cluster2
- Heap tabella
Quale metodo di accesso fisico usare?
- Ricerca nell'indice
- Analisi dell'indice
- Analisi tabella
Quale operatore di join fisico usare?
- Join a cicli annidati (NJ)
- Hash join (HJ)
- Merge join (MJ)
- Join adattivo (a partire da SQL Server 2017 (14.x))
Per altre informazioni, vedere Join.
Eseguire parti della query in parallelo o serialmente?
Per altre informazioni, vedere Elaborazione di query parallele.
Sebbene i fattori seguenti riducano il numero di metodi di accesso considerati e quindi le possibilità considerate:
- Predicati di query (filtri nella
WHEREclausola) - Esistenza di vincoli
- Combinazioni di statistiche ben progettate e aggiornate
Nota: il fatto che QO raggiunga la soglia non significa che finirà con una query più lenta. Nella maggior parte dei casi, la query avrà prestazioni buone, ma in alcuni casi potrebbe verificarsi un'esecuzione di query più lenta.
Esempio di come vengono considerati i fattori
Per illustrare, si prenda un esempio di join tra tre tabelle (t1, t2e t3) e ogni tabella ha un indice cluster e un indice non cluster.
Prima di tutto, prendere in considerazione i tipi di join fisico. Ci sono due join coinvolti qui. Inoltre, poiché esistono tre possibilità di join fisico (NJ, HJ e MJ), la query può essere eseguita in 32 = 9 modi.
- NJ - NJ
- NJ - HJ
- NJ - MJ
- HJ - NJ
- HJ - HJ
- HJ - MJ
- MJ - NJ
- MJ - HJ
- MJ - MJ
Prendere quindi in considerazione l'ordine di join, calcolato usando permutazioni: P (n, r). L'ordine delle prime due tabelle non è rilevante, quindi può esistere P(3,1) = 3 possibilità:
- Partecipa
t1cont2e poi cont3 - Partecipa
t1cont3e poi cont2 - Partecipa
t2cont3e poi cont1
Si considerino quindi gli indici cluster e non cluster che possono essere usati per il recupero dei dati. Inoltre, per ogni indice sono disponibili due metodi di accesso, ricerca o analisi. Ciò significa che per ogni tabella sono disponibili 2 2 = 4 scelte. Sono disponibili tre tabelle, quindi possono essere disponibili 43 = 64 scelte.
Infine, considerando tutte queste condizioni, possono esserci 9*3*64 = 1728 piani possibili.
Si supponga ora che nella query siano presenti n tabelle unite e ogni tabella abbia un indice cluster e un indice non cluster. Prendere in considerazione i fattori seguenti:
- Ordini di join: P(n,n-2) = n!/2
- Tipi di join: 3n-1
- Tipi di indice diversi con metodi di ricerca e analisi: 4n
Moltiplicare tutti questi elementi sopra e ottenere il numero di possibili piani: 2*n!*12n-1. Quando n = 4, il numero è 82.944. Quando n = 6, il numero è 358.318.080. Quindi, con l'aumento del numero di tabelle coinvolte in una query, il numero di possibili piani aumenta geometricamente. Inoltre, se si include la possibilità di parallelismo e altri fattori, è possibile immaginare quanti possibili piani verranno considerati. Di conseguenza, una query con un numero elevato di join è più probabile che raggiunga la soglia di timeout dell'utilità di ottimizzazione rispetto a una con un minor numero di join.
Si noti che i calcoli precedenti illustrano lo scenario peggiore. Come abbiamo sottolineato, esistono fattori che ridurranno il numero di possibilità, ad esempio predicati di filtro, statistiche e vincoli. Ad esempio, un predicato di filtro e statistiche aggiornate ridurrà il numero di metodi di accesso fisico perché potrebbe essere più efficiente usare una ricerca di indice rispetto a un'analisi. Ciò comporterà anche una selezione più piccola di join e così via.
Perché viene visualizzato un timeout di Optimizer con una query semplice?
Niente con Query Optimizer è semplice. Ci sono molti scenari possibili e il grado di complessità è così elevato che è difficile comprendere tutte le possibilità. Query Optimizer può impostare dinamicamente la soglia di timeout in base al costo del piano trovato in una determinata fase. Ad esempio, se viene trovato un piano relativamente efficiente, il limite di attività per la ricerca di un piano migliore potrebbe essere ridotto. Di conseguenza, la stima della cardinalità sottovalutata (CE) può essere uno scenario per raggiungere un timeout di Optimizer in anticipo. In questo caso, l'obiettivo dell'indagine è ce. È un caso più raro rispetto allo scenario relativo all'esecuzione di una query complessa descritta nella sezione precedente, ma è possibile.
Risoluzioni
Un timeout di Optimizer visualizzato in un piano di query non significa necessariamente che sia la causa delle prestazioni delle query scarse. Nella maggior parte dei casi, potrebbe non essere necessario eseguire alcuna operazione su questa situazione. Il piano di query con cui SQL Server termina potrebbe essere ragionevole e la query in esecuzione potrebbe risultare ottimale. È possibile che non si sappia mai che si è verificato un timeout di Optimizer.
Provare i passaggi seguenti se si trova la necessità di ottimizzare e ottimizzare.
Passaggio 1: Stabilire una linea di base
Controllare se è possibile eseguire la stessa query con lo stesso set di dati in una build diversa di SQL Server, usando una configurazione ce diversa o in un sistema diverso (specifiche hardware). Un principio guida nell'ottimizzazione delle prestazioni è "non c'è alcun problema di prestazioni senza una baseline". Pertanto, sarebbe importante stabilire una linea di base per la stessa query.
Passaggio 2: Cercare le condizioni "nascoste" che portano al timeout di Optimizer
Esaminare in dettaglio la query per determinarne la complessità. Al momento dell'esame iniziale, potrebbe non essere ovvio che la query è complessa e comporta molti join. Uno scenario comune è che sono coinvolte viste o funzioni con valori di tabella. Ad esempio, sulla superficie, la query potrebbe sembrare semplice perché unisce due visualizzazioni. Tuttavia, quando si esaminano le query all'interno delle viste, è possibile che ogni vista unisce sette tabelle. Di conseguenza, quando le due viste vengono unite in join, si ottiene un join di 14 tabelle. Se la query usa gli oggetti seguenti, eseguire il drill-down in ogni oggetto per visualizzare l'aspetto delle query sottostanti all'interno:
- Visualizzazioni
- Funzioni con valori di tabella (TFV)
- Sottoquery o tabelle derivate
- Espressioni di tabella comuni (CTE)
- Operatori UNION
Per tutti questi scenari, la risoluzione più comune consiste nel riscrivere la query e suddividerla in più query. Per altri dettagli, vedere Passaggio 7: Perfezionare la query .
Sottoquery o tabelle derivate
La query seguente è un esempio che unisce due set separati di query (tabelle derivate) con 4-5 join in ognuno. Tuttavia, dopo l'analisi da parte di SQL Server, verrà compilato in una singola query con otto tabelle unite in join.
SELECT ...
FROM
( SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
) AS derived_table1
INNER JOIN
( SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
) AS derived_table2
ON derived_table1.Co1 = derived_table2.Co10
AND derived_table1.Co2 = derived_table2.Co20
Espressioni di tabella comuni
L'uso di più espressioni di tabella comuni non è una soluzione appropriata per semplificare una query ed evitare timeout di Optimizer. Più CTE aumentano solo la complessità della query. Pertanto, è controproducente usare le TTE durante la risoluzione dei timeout dell'ottimizzatore. Le CTE sembrano suddividere una query in modo logico, ma verranno combinate in una singola query e ottimizzate come singolo join di tabelle di grandi dimensioni.
Ecco un esempio di CTE che verrà compilato come singola query con molti join. Potrebbe sembrare che la query sul my_cte sia un join semplice a due oggetti, ma in realtà sono presenti sette altre tabelle unite in CTE.
WITH my_cte AS (
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
WHERE ... )
SELECT ...
FROM my_cte
JOIN t8 ON ...
Visualizzazioni
Assicurarsi di aver controllato le definizioni di visualizzazione e di aver ottenuto tutte le tabelle coinvolte. Analogamente alle ctes e alle tabelle derivate, i join possono essere nascosti all'interno delle visualizzazioni. Ad esempio, un join tra due viste può essere una singola query con otto tabelle coinvolte:
CREATE VIEW V1 AS
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE VIEW V2 AS
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM V1
JOIN V2 ON ...
Funzioni con valori di tabella (TVFS)
Alcuni join potrebbero essere nascosti all'interno di TFV. L'esempio seguente mostra cosa appare come join tra due tfv e una tabella può essere un join di nove tabelle.
CREATE FUNCTION tvf1() RETURNS TABLE
AS RETURN
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE FUNCTION tvf2() RETURNS TABLE
AS RETURN
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM tvf1()
JOIN tvf2() ON ...
JOIN t9 ON ...
Union
Gli operatori union combinano i risultati di più query in un singolo set di risultati. Combinano anche più query in una singola query. È quindi possibile ottenere una singola query complessa. Nell'esempio seguente verrà visualizzato un singolo piano di query che include 12 tabelle.
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
UNION ALL
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
UNION ALL
SELECT ...
FROM t9
JOIN t10 ON ...
JOIN t11 ON ...
JOIN t12 ON ...
Passaggio 3: Se si dispone di una query di base che viene eseguita più velocemente, usare il piano di query
Se si determina che un piano di base specifico ottenuto dal passaggio 1 è migliore per la query tramite test, usare una delle opzioni seguenti per forzare QO a selezionare tale piano:
- Stored procedure query store (QDS)
- Suggerimento per la query: OPTION (USE PLAN N'XML_Plan<>')
- Guide di piano
Passaggio 4: Ridurre le scelte dei piani
Per ridurre la probabilità di un timeout di Optimizer, provare a ridurre le possibilità che il QO deve prendere in considerazione nella scelta di un piano. Questo processo comporta il test della query con diverse opzioni di hint. Come accade con la maggior parte delle decisioni con QO, le scelte non sono sempre deterministiche sulla superficie perché esiste una grande varietà di fattori da considerare. Pertanto, non esiste una singola strategia di successo garantita e il piano selezionato può migliorare o ridurre le prestazioni della query selezionata.
Forzare un ordine JOIN
Usare OPTION (FORCE ORDER) per eliminare le permutazioni degli ordini:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
OPTION (FORCE ORDER)
Ridurre le possibilità join
Se altre alternative non sono state aiutate, provare a ridurre le combinazioni del piano di query limitando le scelte degli operatori di join fisici con hint di join. Ad esempio: OPTION (HASH JOIN, MERGE JOIN)o OPTION (HASH JOIN, LOOP JOIN) OPTION (MERGE JOIN).
Nota: è consigliabile prestare attenzione quando si usano questi hint.
In alcuni casi, la limitazione dell'ottimizzatore con un minor numero di scelte di join può causare la mancata disponibilità dell'opzione di join migliore e potrebbe effettivamente rallentare la query. In alcuni casi, inoltre, un join specifico è richiesto da un ottimizzatore (ad esempio, obiettivo di riga) e la query potrebbe non generare un piano se tale join non è un'opzione. Pertanto, dopo aver destinato gli hint di join per una query specifica, verificare se si trova una combinazione che offre prestazioni migliori ed elimina il timeout di Optimizer.
Di seguito sono riportati due esempi di come usare tali hint:
Usare
OPTION (HASH JOIN, LOOP JOIN)per consentire solo join hash e cicli ed evitare join di tipo merge nella query:SELECT ... FROM t1 JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ... OPTION (HASH JOIN, LOOP JOIN)Applicare un join specifico tra due tabelle:
SELECT ... FROM t1 INNER MERGE JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ...
Passaggio 5: Modificare la configurazione ce
Provare a modificare la configurazione ce passando da Ce legacy a New CE. La modifica della configurazione ce può comportare la selezione del QO di un percorso diverso quando SQL Server valuta e crea piani di query. Pertanto, anche se si verifica un problema di timeout di Optimizer, è possibile che si verifichi un piano che esegue in modo più ottimale rispetto a quello selezionato usando la configurazione ce alternativa. Per altre informazioni, vedere Come attivare il piano di query migliore (stima della cardinalità).
Passaggio 6: Abilitare le correzioni di Optimizer
Se le correzioni di Query Optimizer non sono state abilitate, è consigliabile abilitarle usando uno dei due metodi seguenti:
- Livello server: usare il flag di traccia T4199.
- Livello di database: usare
ALTER DATABASE SCOPED CONFIGURATION ..QUERY_OPTIMIZER_HOTFIXES = ONo modificare i livelli di compatibilità del database per SQL Server 2016 e versioni successive.
Le correzioni QO possono causare l'esecuzione di un percorso diverso nell'esplorazione del piano. Può quindi scegliere un piano di query più ottimale. Per altre informazioni, vedere Sql Server Query Optimizer hotfix trace flag 4199 servicing model .For more information, see SQL Server Query Optimizer hotfix trace flag 4199 servicing model.
Passaggio 7: Perfezionare la query
Valutare la possibilità di suddividere la singola query su più tabelle in più query separate usando tabelle temporanee. La suddivisione della query è solo uno dei modi per semplificare l'attività per l'ottimizzatore. Vedere l'esempio seguente:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
Per ottimizzare la query, provare a suddividere la singola query in due query inserendo parte dei risultati del join in una tabella temporanea:
SELECT ...
INTO #temp1
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
GO
SELECT ...
FROM #temp1
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...