Risolvere i problemi di failover dei gruppi di disponibilità AlwaysOn
Note
Per automatizzare l'analisi manuale descritta in questo articolo, vedere Usare AGDiag per diagnosticare gli eventi di integrità del gruppo di disponibilità.
Questo articolo illustra i passaggi per la risoluzione dei problemi per determinare il motivo per cui è stato eseguito il failover del gruppo di disponibilità.
Effetti dei problemi di integrità Always On o del failover
Always On implementa un solido monitoraggio dell'integrità tramite meccanismi diversi per garantire l'integrità dell'istanza di Microsoft SQL Server che ospita la replica primaria, il cluster sottostante e l'integrità del sistema. Il carico di lavoro di produzione viene interrotto momentaneamente quando viene identificato un cluster Windows o un problema di integrità Always On.
Quando viene rilevata una condizione di integrità, si verifica in genere la sequenza di eventi seguente. In questo strumento di risoluzione dei problemi, gli eventi di integrità vengono menzionati in riferimento agli eventi seguenti:
Le repliche e i database del gruppo di disponibilità passano dal ruolo primario alla risoluzione del ruolo.
I database del gruppo di disponibilità passano alla modalità offline e non sono più accessibili.
Cluster windows contrassegna la risorsa cluster del gruppo di disponibilità come non riuscita.
Cluster Windows tenta di riportare online il ruolo del gruppo di disponibilità (nella replica partner di failover originale o automatica).
Il ruolo del gruppo di disponibilità viene fornito online correttamente se viene rilevato come integro dal monitoraggio dell'integrità di Always On e del cluster Windows.
In caso di esito positivo, le repliche e i database del gruppo di disponibilità passano al ruolo primario e i database del gruppo di disponibilità vengono online e sono accessibili dall'applicazione.
Le applicazioni non possono accedere ai database del gruppo di disponibilità
Quando viene rilevata una condizione di integrità, la replica e i database del gruppo di disponibilità passano al ruolo Risoluzione e i database del gruppo di disponibilità vengono portati offline. Dopo che la replica viene online nel ruolo primario (nel server di replica originale o nel server di replica partner di failover), la replica e i database passano nuovamente online. Mentre la replica e i database vengono risolti e sono offline, tutte le applicazioni che tentano di accedere a tali database del gruppo di disponibilità hanno esito negativo e generano un messaggio "Errore 983": Unable to access availability database.... Questo errore viene registrato anche nel log degli errori di Microsoft SQL Server se SQL Server è configurato per registrare tentativi di accesso non riusciti:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
Periodo durante il quale il gruppo di disponibilità si trova nel ruolo di risoluzione prima che torni online nel ruolo primario in genere dura solo pochi secondi o anche meno di un secondo.
Identificare e diagnosticare gli eventi di integrità o il failover del gruppo di disponibilità AlwaysOn
1. Identificare le tendenze di integrità Always On
È possibile analizzare un singolo evento di integrità Always On oppure potrebbe verificarsi una tendenza recente o continuativa di problemi di integrità che interrompono in modo intermittente la produzione. Le domande seguenti consentono di limitare e correlare le modifiche recenti nell'ambiente di produzione che potrebbero essere correlate a questi problemi di integrità:
- Quando è iniziata la tendenza degli eventi di integrità Always On o del cluster?
- Gli eventi di integrità si verificano in un determinato giorno?
- Gli eventi di integrità si verificano in un determinato momento del giorno?
- Gli eventi di integrità si verificano in un determinato giorno o settimana del mese?
Se si rileva una tendenza, controllare la manutenzione pianificata nel sistema (il sistema host in un ambiente virtuale), i batch ETL e altri processi che potrebbero correlare con questi eventi di integrità. Se il sistema è una macchina virtuale, esaminare il sistema host per individuare le modifiche eventualmente introdotte al momento delle interruzioni.
Prendere in considerazione carichi di lavoro di produzione ad hoc occupati che potrebbero correlare all'ora dei problemi di integrità, ad esempio quando gli utenti accedono per la prima volta al sistema o dopo che gli utenti tornano dal pranzo.
Note
Questo è un buon momento per prendere in considerazione un piano per raccogliere i dati sulle prestazioni durante la settimana e il mese. Per comprendere meglio quando il sistema è più trafficato, è possibile misurare i contatori di Monitoraggio prestazioni di Windows, ad Processor Information::% Processor Timeesempio , Memory::Available MBytese MSSQLServer:SQL Statistics::Batch Requests/sec.
2. Esaminare il log del cluster
Il log del cluster di Windows è il log più completo da usare per identificare il tipo di evento di integrità Always On o cluster e anche la condizione di integrità rilevata che ha causato l'evento. Per generare e aprire il log del cluster, seguire questa procedura:
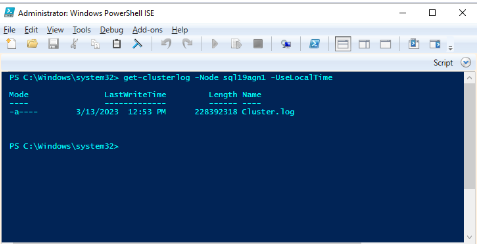
Usare Windows PowerShell per generare il log del cluster windows nel nodo del cluster che ospita la replica primaria al momento dell'evento di integrità. Ad esempio, eseguire il cmdlet seguente in una finestra di PowerShell con privilegi elevati usando 'sql19agn1' come nome del server basato su SQL Server:
get-clusterlog -Node sql19agn1 -UseLocalTime
Note
Per impostazione predefinita, il file di log viene creato in %WINDIR%\cluster\reports.
3. Trovare l'evento di integrità nel log del cluster
Always On usa diversi meccanismi di monitoraggio dell'integrità per monitorare l'integrità del gruppo di disponibilità. Oltre a un evento di integrità del cluster Windows (in cui Cluster Windows rileva un problema di integrità tra i nodi del cluster), Always On include quattro diversi tipi di controlli di integrità:
- Il servizio SQL Server non è in esecuzione
- Timeout lease di SQL Server
- Timeout del controllo integrità di SQL Server
- Un problema di integrità interno di SQL Server
È possibile individuare uno di questi eventi di integrità specifici di Always On eseguendo una ricerca nella stringa nel log del cluster. [hadrag] Resource Alive result 0 Questa stringa viene salvata nel log del cluster quando viene rilevato uno di questi eventi. Ad esempio:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
È possibile usare uno strumento per trovare tutti gli eventi di integrità nel log del cluster in modo da poter generare un report di riepilogo dei problemi di integrità Always On. Ciò può essere utile per identificare le tendenze cronologiche e determinare se una determinata condizione di integrità Always On è ricorrente. Lo screenshot seguente mostra come usare un editor di testo (NotePad++, in questo caso) per trovare tutte le righe nel log del cluster che contengono la [hadrag] Resource Alive result 0 stringa:

Identificare e risolvere il problema di integrità che ha attivato il failover
Per identificare i problemi di integrità nel log cluster della replica primaria, confrontarli con i problemi descritti nelle sezioni seguenti. I motivi comuni per il failover del gruppo di disponibilità includono:
- Evento di integrità del cluster
- Il servizio SQL Server è inattivo (evento di integrità Always On)
- Timeout lease (evento di integrità Always On)
- Timeout del controllo integrità (evento di integrità Always On)
- Integrità di SQL Server (evento di integrità Always On)
Eventi di integrità del cluster
Microsoft Windows Cluster monitora l'integrità dei server membri nel cluster. Se viene rilevato un problema di integrità, un server membro del cluster potrebbe essere rimosso dal cluster. Inoltre, le risorse del cluster (incluso il ruolo del gruppo di disponibilità ospitato nel server membro del cluster rimosso) verranno spostate nella replica partner di failover del gruppo di disponibilità se è configurata per il failover automatico.
Sintomi
Ecco un esempio di evento di integrità del cluster nel log del cluster. Per trovarla, è possibile cercare Lost quorum o Cluster service has terminated perché potrebbe essere presente durante la modifica o il failover del ruolo del gruppo di disponibilità.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Un altro modo per identificare questo evento consiste nel cercare nel registro eventi di sistema di Windows:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Diagnosticare un evento di integrità del cluster
Gli errori nel registro eventi di Windows (eventi 1135 e 1177) suggeriscono che la connettività di rete è una causa dell'evento. Questo è il motivo più comune per cui viene rilevato un problema di integrità del cluster. L'esempio seguente mostra che altri server membri del cluster non possono comunicare con questo server che ospita la replica primaria del gruppo di disponibilità e che questo problema ha attivato la rimozione del nodo del cluster dal cluster:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
È possibile cercare nel log del cluster l'evidenza di un errore di connessione al nodo. Dal percorso nel log del cluster in cui è stato trovato Lost quorum, cercare le stringhe, ad esempio Failed to connect to remote endpoint, unreachablee is broken.
Risoluzione
Assicurarsi che il monitoraggio dell'integrità del cluster sia appropriato per l'ambiente host. Per altre informazioni sui gruppi di disponibilità AlwaysOn di SQL Server ospitati in Microsoft Azure, vedere Panoramica del cluster di failover di Windows Server - SQL Server in macchine virtuali di Azure.
Se necessario, è consigliabile contattare il supporto per la disponibilità elevata di Microsoft Windows per aprire un evento imprevisto di supporto.
Servizio SQL Server inattivo: evento di integrità Always On
Il monitoraggio dell'integrità AlwaysOn può rilevare se il servizio SQL Server che ospita la replica primaria del gruppo di disponibilità non è più in esecuzione.
Sintomi
Di seguito è riportato un esempio del report del log del cluster per il ruolo del gruppo di disponibilità "ag" che indica un errore perché QueryServiceStatusEx è stato restituito un ID 0processo:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
Diagnosticare gli eventi di arresto del servizio SQL
Controllare il registro eventi di sistema di Windows e il log degli errori di SQL Server per un arresto imprevisto di SQL Server.
Se SQL Server è stato arrestato da un arresto del sistema o da un arresto amministrativo, nel log degli errori di SQL Server verrà visualizzata la voce seguente:
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
Il registro eventi di sistema di Windows visualizza la voce di errore seguente:
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
Il registro eventi di sistema di Windows mostra la voce di errore seguente se SQL Server si arresta in modo imprevisto:
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
Controllare la fine del log degli errori di SQL Server per individuare gli indizi. Se il log degli errori termina improvvisamente, significa che è stato arrestato forzatamente. Ad esempio, se SQL Server è stato terminato tramite Gestione attività, il report degli errori di SQL Server non rivelerà informazioni su eventuali problemi interni che potrebbero aver causato l'arresto del processo.
Risoluzione
Assicurarsi che gli amministratori di sistema e del database autorizzati abbiano accesso al sistema per ridurre al minimo le terminazioni impreviste del servizio SQL Server. Dopo aver esaminato i log eventi, esaminare il motivo per cui un servizio doveva essere terminato in modo imprevisto.
Se un problema di integrità interno di SQL Server ha causato l'interruzione imprevista di SQL Server, potrebbero esserci indizi di una possibile eccezione irreversibile (incluso un file di diagnostica del dump della memoria generato) alla fine del log degli errori SQL. Esaminare gli indizi e intraprendere l'azione necessaria. Se si trova un file di dump, è consigliabile contattare il supporto di Microsoft SQL Server e fornire il contenuto del file di dump e del log degli errori di SQL Server per ulteriori indagini.
Timeout lease: evento di integrità Always On
Always On usa un meccanismo di "lease" per monitorare l'integrità del computer in cui è installato SQL Server. Il timeout del lease predefinito è di 20 secondi.
Sintomi
Di seguito è riportato un output di esempio di timeout del lease Always On dal log del cluster. È possibile cercare queste stringhe per individuare un timeout del lease nel log del cluster.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Per altre informazioni sul timeout del lease, vedere la sezione Meccanismo di lease in Meccanica e linee guida sui timeout di lease, cluster e controllo dell'integrità per i gruppi di disponibilità AlwaysOn.
Diagnosticare e risolvere gli eventi di timeout del lease Always On
Esistono due problemi principali che possono attivare un timeout del lease:
Dump della memoria di SQL Server: quando SQL Server rileva determinati eventi di integrità interni, ad esempio una violazione di accesso, un'asserzione o un deadlock dell'utilità di pianificazione, genera un file di dump di diagnostica (mdmp) nella cartella SQL Server \LOG . Il processo di generazione di un dump della memoria sospende l'esecuzione di SQL Server per un breve periodo. In quel periodo il meccanismo di lease può rilevare la mancanza di risposta al servizio e l'azione di attivazione. Per altre informazioni, vedere Impatto della generazione di dump.
Un problema di prestazioni a livello di sistema: un timeout del lease non indica necessariamente un problema di integrità di SQL Server. Potrebbe invece indicare un problema di integrità a livello di sistema che influisce anche sull'integrità del server basato su SQL Server.
- Utilizzo elevato della CPU nel sistema (vicino al 100%).
- Condizioni di memoria insufficiente: memoria virtuale insufficiente e/o uno dei processi in fase di paging.
- WSFC in modalità offline a causa della perdita del quorum
- La limitazione delle macchine virtuali influisce sulle prestazioni e causa la scadenza del lease.
Risoluzione
Per informazioni dettagliate sulla risoluzione dei problemi, vedere MSSQLSERVER_19407. Ecco i due problemi più comuni:
diagnostica del file di dump del server 1. SQL
SQL Server potrebbe rilevare un problema di integrità interno, ad esempio una violazione di accesso, un'asserzione o utilità di pianificazione senza deadlock. In questo caso, il programma genera un mini file dump (con estensione mdmp) nella cartella SQL Server \LOG del processo di SQL Server per la diagnosi. Il processo di SQL Server viene bloccato per diversi secondi mentre il file di mini dump viene scritto su disco. Durante questo periodo di tempo, tutti i thread all'interno del processo di SQL Server si trovano in uno stato bloccato, che include il thread di lease monitorato dal monitoraggio dell'integrità AlwaysOn. Di conseguenza, Always On potrebbe rilevare un timeout del lease.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
Per risolvere questo problema, è necessario esaminare la diagnostica del file di dump della memoria per la causa radice. È consigliabile contattare il supporto di Microsoft SQL Server per fornire il contenuto del file di dump e del log degli errori di SQL Server per ulteriori indagini.
2. Utilizzo elevato della CPU o altro problema di prestazioni del sistema
Un timeout del lease indica un problema di prestazioni che interessa l'intero sistema, incluso SQL Server. Per diagnosticare il problema di sistema, la diagnostica dell'integrità Always On segnala i dati di monitoraggio delle prestazioni nel log del cluster e include l'evento di timeout del lease. I dati sulle prestazioni si estendono circa 50 secondi fino all'evento di timeout del lease, segnalando l'utilizzo della CPU, la memoria libera e la latenza del disco.
Di seguito è riportato un esempio dei dati sulle prestazioni segnalati che mostrano un timeout del lease nel log del cluster. In questo output di esempio, un utilizzo complessivo elevato della CPU che potrebbe essere correlato al timeout del lease.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Se i dati sulle prestazioni mostrano un utilizzo elevato della CPU, una condizione di memoria insufficiente o una latenza elevata del disco al momento di un timeout del lease, iniziare a raccogliere Monitor prestazioni dati per l'intero giorno nella replica primaria per analizzare questi sintomi. Acquisendo i dati di monitoraggio delle prestazioni in un periodo più lungo, è possibile identificare meglio i valori di base e di picco per queste risorse e monitorare le modifiche in queste risorse quando si verifica un timeout del lease. Durante la raccolta di questi dati, valutare se sono presenti determinati carichi di lavoro pianificati o ad hoc in SQL Server correlati all'ora di questi problemi di risorse ed eventi di integrità.
È anche necessario acquisire contatori che segnalano lo stesso utilizzo delle risorse di sistema, inclusi i seguenti:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Timeout del controllo integrità: evento di integrità Always On
Always On usa un meccanismo di controllo integrità per monitorare l'integrità di SQL Server e la possibilità per le applicazioni client di connettersi.
Sintomi
Quando una replica del gruppo di disponibilità passa al ruolo primario, il monitoraggio dell'integrità Always On stabilisce una connessione ODBC locale all'istanza di SQL Server. Mentre Always On è connesso e monitorato, se SQL Server non risponde alla connessione ODBC entro il periodo impostato per il timeout del controllo integrità del gruppo di disponibilità (il valore predefinito è 30 secondi), viene attivato un evento di timeout del controllo integrità. In questo caso, il gruppo di disponibilità passa dal ruolo primario al ruolo Risoluzione e avvia il failover, se è configurato per eseguire questa operazione.
Per altre informazioni sui timeout del controllo integrità, vedere la sezione "Operazione di timeout controllo integrità" in Meccanica e linee guida dei timeout di lease, cluster e controllo integrità per i gruppi di disponibilità AlwaysOn.
Di seguito è riportato un timeout del controllo integrità Always On come segnalato nel log del cluster:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Diagnosticare e risolvere l'evento di timeout del controllo integrità Always On
La sezione seguente consente di esaminare i log di SQL Server per gli eventi di tipo "bread crumb" che è possibile trovare e che sono correlati ai timeout del controllo integrità AlwaysOn rilevati e segnalati. I log esaminati includono il log del cluster (in cui viene confermato il timeout del controllo integrità), i system_health log eventi estesi e i log degli errori di SQL Server (entrambi presenti nella cartella SQL Server \LOG ) e il registro eventi di sistema di Windows. Usare questi e altri log per cercare eventi correlati che potrebbero aiutare a definire la causa del timeout del controllo integrità.
1. Verificare la presenza di eventi dell'utilità di pianificazione senza rendimento
Il timeout del controllo integrità Always On è spesso causato da eventi "non yielding" in SQL Server. Quando SQL Server rileva che un thread non è stato restituito in un'utilità di pianificazione, segnala che si è verificato un evento dell'utilità di pianificazione senza rendimento. Se nella stessa utilità di pianificazione vengono visualizzate altre attività che non ricevono tempo cpu, questo è il segno principale di un'utilità di pianificazione non che produce. Questo comportamento può causare un'esecuzione ritardata di tali attività e carichi di lavoro "starve" assegnati a un determinato utilità di pianificazione del tempo cpu.
Per verificare la presenza di eventi dell'utilità di pianificazione non restituiti, seguire questa procedura:
Controllare i registri eventi estesi di SQL Server
system_healthper determinare se è stato segnalato un evento dell'utilità di pianificazione non yield di qualche tipo circa il tempo dell'evento di timeout del controllo integrità Always On. Gli eventi che potrebbero non produrre potrebbero includere quanto segue:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Aprire i registri eventi estesi dell'integrità del sistema DI SQL Server nella replica primaria fino al timeout del sospetto timeout del controllo integrità.
In SQL Server Management Studio (SSMS) passare a File Open (File > Open) e selezionare Merge Extended Event Files (Unisci file di eventi estesi).
Seleziona il pulsante Aggiungi.
Nella finestra di dialogo Apri file passare ai file nella directory SQL Server \LOG.
Premere e tenere premuto Controllo, quindi selezionare i file i cui nomi iniziano con
system_health_xxx.xel.Selezionare Apri>OK.
Filtrare i risultati. Fare clic con il pulsante destro del mouse su un evento nella colonna nome e scegliere Filtra in base a questo valore.
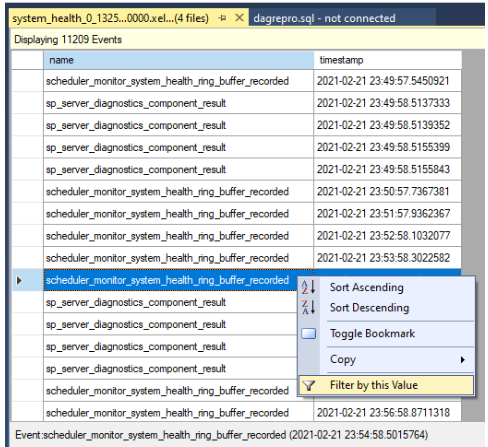
Definire un filtro per ordinare le righe in cui i valori nella colonna name contengono
yield, come illustrato nello screenshot seguente. In questo modo vengono restituiti tutti i tipi di eventi che potrebbero essere stati registrati neisystem_healthlog.
Confrontare i timestamp per verificare se al momento del timeout del controllo integrità sono presenti eventi non restituiti. Ecco il timeout del controllo integrità come indicato nel log del cluster:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.È possibile notare che al momento del timeout del controllo integrità si sono verificati eventi che non hanno restituito risultati.
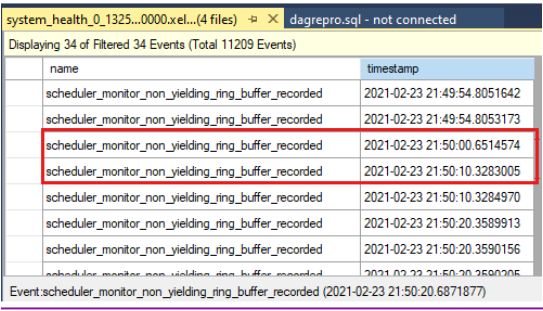
Se vengono rilevati eventi non restituiti, controllare la causa dell'evento che non produce. Prendere in considerazione la possibilità di contattare il team di supporto di SQL Server per esaminare gli eventi non restituiti.
2. Controllare il log degli errori di SQL Server
Controllare il log degli errori di SQL Server per verificare la correlazione degli eventi al momento del timeout del controllo integrità. Questi eventi potrebbero fornire "briciole di navigazione" che suggeriscono ulteriori passaggi per definire l'ambito della causa radice dei timeout del controllo integrità.
Ad esempio, la voce di log seguente mostra che si è verificato un timeout del controllo integrità nel log del cluster:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
Nel log degli errori di SQL Server, entro pochi secondi dal timeout del controllo integrità, SQL Server segnala che è stata rilevata una latenza di I/O grave:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Esaminare il registro eventi di sistema per individuare possibili indizi di sistema che potrebbero essere correlati all'evento di timeout del controllo integrità. Quando si esamina il registro eventi di sistema di Windows, è possibile che venga rilevato un problema di I/O segnalato contemporaneamente per lo stesso timeout del controllo integrità:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
Integrità di SQL Server: evento di integrità Always On
AlwaysOn monitora diversi tipi di eventi di integrità di SQL Server. Mentre ospita una replica primaria del gruppo di disponibilità, SQL Server esegue continuamente sp_server_diagnostics che segnala l'integrità di SQL Server usando componenti diversi. Quando vengono rilevati problemi di integrità, sp_server_diagnostics segnala un errore per quel particolare componente e quindi invia i risultati al processo di rilevamento dell'integrità Always On. Quando viene segnalato un errore, il ruolo Gruppo di disponibilità mostra lo stato di errore e il possibile failover se il gruppo di disponibilità è configurato per eseguire questa operazione.
Sintomi
Di seguito è riportato un esempio di un problema di integrità di SQL Server come segnalato nel sp_server_diagnostics log del cluster. SQL Server segnala uno stato di errore nel componente di sistema al monitoraggio dell'integrità Always On e il gruppo di disponibilità "contoso-ag" viene passato a uno stato di errore.
Note
Un problema di integrità di SQL Server genera un report simile a quello del timeout del controllo integrità. Entrambi gli eventi di integrità segnalano Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel. La distinzione per un evento di integrità di SQL Server è che segnala che il componente DI SQL Server è cambiato da "avviso" a "errore".
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
Diagnosticare gli eventi di integrità di SQL Server
Il tipo di problema di integrità segnalato dall'integrità di SQL Server deve determinare la direzione dell'analisi della causa radice.
Per impostazione predefinita, quando si distribuisce un gruppo di disponibilità, viene FAILURE_CONDITION_LEVEL impostato su tre. In questo modo viene attivato il monitoraggio di alcuni profili di integrità, ma non di tutti i profili di integrità di SQL Server. A livello predefinito, Always On attiva un evento di integrità quando SQL Server produce troppi file di dump, una violazione dell'accesso in scrittura o uno spinlock orfano. L'impostazione del gruppo di disponibilità fino al livello quattro o cinque espanderà i tipi di problemi di integrità di SQL Server monitorati. Per altre informazioni sui monitoraggi Always On di integrità di SQL Server, vedere Configurare criteri di failover automatico flessibili per un gruppo di disponibilità - SQL Server AlwaysOn.
Per identificare il problema di integrità specifico di Always On, seguire questa procedura:
Aprire i log eventi estesi di diagnostica del cluster SQL Server nella replica primaria al momento in cui si è verificato l'evento di integrità sospetto di SQL Server.
In SSMS passare a File Open (Apri file>) e quindi selezionare Merge Extended Event Files (Unisci file di eventi estesi).
Selezionare Aggiungi.
Nella finestra di dialogo Apri file passare ai file nella directory SQL Server \LOG.
Premere Ctrl, selezionare i file i cui nomi corrispondono
<servername>_<instance>_SQLDIAG_xxx.xela e quindi selezionare Apri>OK.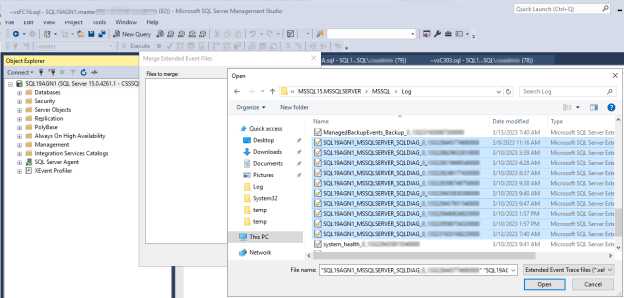
Verrà visualizzata una nuova finestra a schede in SSMS che include gli eventi estesi, come illustrato nello screenshot seguente.
Per analizzare un problema di integrità di SQL Server, individuare il
component_health_resultcuistate_descvalore èerror. Di seguito è riportato un esempio di evento del componente di sistema che ha segnalato un errore al monitoraggio dell'integrità Always On: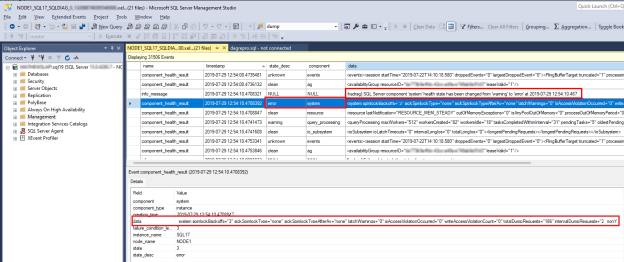
Fare doppio clic sulla colonna di dati nel riquadro inferiore. Verrà aperto il dettaglio dei dati dei componenti in un nuovo riquadro della finestra di SSMS da esaminare. Ecco l'aspetto dei dati dei componenti di sistema:

Si noti che i dati 'totalDumprequests=186' indicano che sono stati generati troppi eventi di diagnostica del file di dump in questo SQL Server. Questo è il motivo per cui il componente di sistema ha segnalato uno stato di errore. Quando il monitoraggio dell'integrità Always On riceve questo stato di errore, attiva un evento di integrità del gruppo di disponibilità. È anche possibile verificare che non siano state rilevate violazioni di accesso in scrittura o spinlock orfani dai dati forniti nei dati dei componenti di sistema.



Risoluzione
A seconda del tipo di problema rilevato, è necessario risolverlo di conseguenza. Poiché nell'articolo Configurare un criterio di failover automatico flessibile per un gruppo di disponibilità - SQL Server AlwaysOn viene illustrato, potrebbero verificarsi diversi problemi che portano a questo problema. Ecco alcuni esempi:
- Indisponibilità del servizio SQL Server.
- Timeout lease.
- La replica di disponibilità si trova in uno stato di errore.
- Dump della memoria generati da spinlock orfani, violazioni di accesso o troppi dump di memoria generati in un breve periodo di tempo.
- Condizione persistente di memoria insufficiente nel pool di risorse interno di SQL Server.
- Rilevamento di un deadlock nell'utilità di pianificazione.
- Rilevamento di un deadlock irrisolvibile.
Se necessario, contattare il supporto di SQL Server per aprire un evento imprevisto di supporto per ottenere ulteriore assistenza per trovare la causa radice per questi problemi di integrità interni di SQL Server