Risoluzione dei problemi di failover automatico negli ambienti AlwaysOn di SQL Server
Questo articolo illustra come risolvere i problemi che si verificano durante il failover automatico in Microsoft SQL Server.
Versione originale del prodotto: SQL Server
Numero KB originale: 2833707
Riepilogo
I gruppi di disponibilità AlwaysOn di SQL Server possono essere configurati per il failover automatico. Se viene rilevato un problema di integrità nell'istanza di SQL Server che ospita la replica primaria, è possibile eseguire la transizione del ruolo primario al partner di failover automatico (replica secondaria). Tuttavia, la replica secondaria non può sempre essere passata al ruolo primario. In alcuni casi, può essere eseguita la transizione solo al RESOLVING ruolo . In questo caso, nessuna replica avrà il ruolo primario a meno che la replica primaria non restituisca uno stato integro. Inoltre, i database di disponibilità non saranno accessibili.
Questo articolo elenca alcune cause comuni del failover automatico non riuscito e illustra i passaggi che è possibile eseguire per diagnosticare la causa di questi errori.
Sintomi se un failover automatico viene attivato correttamente
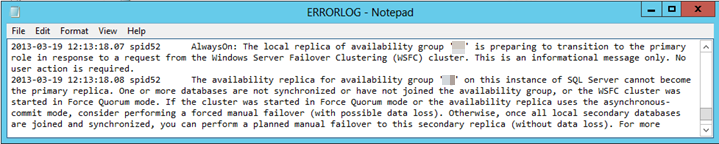
Quando viene attivato un failover automatico nell'istanza di SQL Server che ospita la replica primaria, la replica secondaria passa al RESOLVING ruolo e quindi al ruolo primario. Anche se il processo ha esito positivo, le voci di errore vengono registrate nel report del log di SQL Server simile al testo seguente:
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

Note
La replica secondaria passa correttamente da uno RESOLVING_NORMAL stato a uno PRIMARY_NORMAL stato.
Sintomi se un failover automatico non riesce
Se un evento di failover automatico non riesce, la replica secondaria non passa correttamente al ruolo primario. Di conseguenza, la replica di disponibilità segnala che la replica si trova in uno RESOLVING stato. Inoltre, i database di disponibilità segnalano che si trovano in NOT SYNCHRONIZING uno stato e le applicazioni non possono accedere a questi database.
Nell'immagine seguente, ad esempio, SQL Server Management Studio segnala che la replica secondaria si trova in uno RESOLVING stato perché il processo di failover automatico non è riuscito a eseguire la transizione della replica secondaria al ruolo primario.
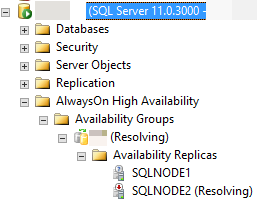
Le sezioni seguenti illustrano diversi motivi per cui il failover automatico potrebbe non riuscire e come diagnosticare ogni causa.
Caso 1: il valore "Numero massimo di errori nel periodo specificato" è esaurito
Il gruppo di disponibilità dispone di proprietà delle risorse cluster di Windows, ad esempio Il numero massimo di errori nella proprietà Periodo specificato. Questa proprietà viene usata per evitare lo spostamento indefinito di una risorsa cluster quando si verificano più errori del nodo.
Per analizzare e diagnosticare se si tratta della causa di un failover non riuscito, esaminare il log del cluster di Windows (Cluster.log) e quindi controllare la proprietà .
Passaggio 1: Esaminare i dati nel log del cluster di Windows (Cluster.log)
Usare Windows PowerShell per generare il log del cluster Windows nel nodo del cluster che ospita la replica primaria. A tale scopo, eseguire il cmdlet seguente in una finestra di PowerShell con privilegi elevati nell'istanza di SQL Server che ospita la replica primaria:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
[! NOTE SULLA]
- Il
-TimeSpan 15parametro in questo passaggio presuppone che si sia verificato il problema che si è verificato durante i 15 minuti precedenti. - Per impostazione predefinita, il file di log viene creato in %WINDIR%\cluster\reports.
- Il
Aprire il file Cluster.log nel Blocco note per esaminare il log del cluster di Windows.
Nel Blocco note selezionare Modifica>ricerca e quindi cercare la stringa "failoverCount" alla fine del file. Nei risultati dovrebbe essere visualizzato un messaggio simile al messaggio seguente:
Non eseguire il failover del nome> della risorsa del gruppo<, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2

Passaggio 2: Controllare il numero massimo di errori nella proprietà Periodo specificato
Avviare Gestione cluster di failover.
Nel riquadro di spostamento selezionare Ruoli.
Nel riquadro Ruoli fare clic con il pulsante destro del mouse sulla risorsa cluster e quindi scegliere Proprietà.
Selezionare la scheda Failover e selezionare il valore Massimo errori nel valore Periodo specificato.
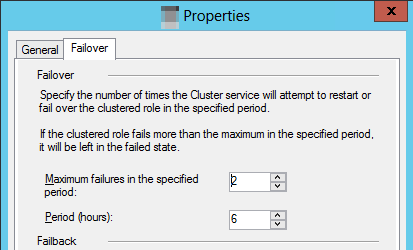
Note
Il comportamento predefinito specifica che se la risorsa cluster ha esito negativo tre volte entro sei ore, deve rimanere nello stato di errore. Per un gruppo di disponibilità, ciò significa che la replica viene lasciata nello
RESOLVINGstato .
Conclusione
Dopo aver analizzato il log, si scopre che il valore failoverCount pari a 3 è maggiore del valore computedFailoverThreshold pari a 2. Di conseguenza, il cluster Windows non può completare l'operazione di failover della risorsa del gruppo di disponibilità al partner di failover.
Risoluzione
Per risolvere questo problema, aumentare il valore Massimo errori nel valore Periodo specificato.
Note
L'aumento di questo valore potrebbe non risolvere il problema. Potrebbe verificarsi un problema più critico che causa l'esito negativo del gruppo di disponibilità più volte entro un breve periodo. Per impostazione predefinita, questo periodo è di 15 minuti. L'aumento di questo valore potrebbe semplicemente causare un errore del gruppo di disponibilità più volte e rimanere in uno stato di errore. È consigliabile usare una risoluzione dei problemi aggressiva per determinare il motivo per cui il failover automatico continua a verificarsi.
Caso 2: Autorizzazioni dell'account NT Authority\SYSTEM insufficienti
La DLL della risorsa di SQL Server motore di database si connette all'istanza di SQL Server che ospita la replica primaria tramite ODBC per monitorare l'integrità. Le credenziali di accesso usate per questa connessione sono l'account di accesso di SQL Server NT AUTHORITY\SYSTEM locale. Per impostazione predefinita, a questo account di accesso locale vengono concesse le autorizzazioni seguenti:
- Modificare qualsiasi gruppo di disponibilità
- Connettere SQL
- Visualizzare lo stato del server
Se l'account NT AUTHORITY\SYSTEM di accesso non dispone di queste autorizzazioni per il partner di failover automatico (replica secondaria), SQL Server non può avviare il rilevamento dell'integrità quando si verifica un failover automatico. Di conseguenza, la replica secondaria non può passare al ruolo primario. Per analizzare e diagnosticare se si tratta della causa, esaminare il log del cluster di Windows. A tale scopo, effettuare i passaggi seguenti:
Usare Windows PowerShell per generare il log del cluster Windows nel nodo del cluster. A tale scopo, eseguire il cmdlet seguente in una finestra di PowerShell con privilegi elevati nell'istanza di SQL Server che ospita la replica secondaria che non ha eseguito la transizione al ruolo primario:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
Aprire il file Cluster.log nel Blocco note per esaminare il log del cluster di Windows.
Trovare una voce di errore simile al testo seguente:
Impossibile eseguire il comando di diagnostica. L'utente non dispone dell'autorizzazione per l'esecuzione di questa azione.
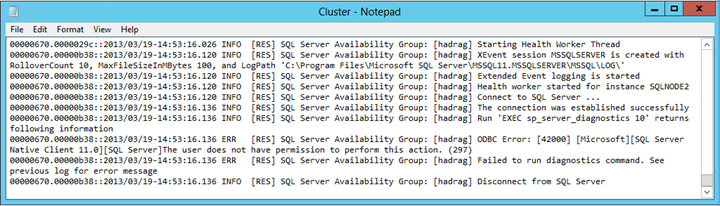
Conclusione
Il file Cluster.log segnala che esiste un problema di autorizzazioni quando SQL Server esegue il comando di diagnostica. In questo esempio l'errore è stato causato dalla rimozione dell'autorizzazione Visualizza stato del server dall'account di accesso nell'istanza NT AUTHORITY\SYSTEM di SQL Server che ospita la replica secondaria di una coppia di failover automatico.
Risoluzione
Per risolvere questo problema, concedere autorizzazioni sufficienti all'account di accesso per il rilevamento dell'integrità NT AUTHORITY\SYSTEM della DLL della risorsa di SQL Server motore di database.
Caso 3: I database di disponibilità non sono in uno stato SYNCHRONIZED
Per eseguire automaticamente il failover, tutti i database di disponibilità definiti nel gruppo di disponibilità devono trovarsi in uno SYNCHRONIZED stato tra la replica primaria e la replica secondaria. Quando si verifica un failover automatico, questa condizione di sincronizzazione deve essere soddisfatta per assicurarsi che non si verifichi alcuna perdita di dati. Pertanto, se un database di disponibilità nel gruppo di disponibilità è in fase di sincronizzazione o NOT SYNCHRONIZED stato, il failover automatico non eseguirà correttamente la transizione della replica secondaria al ruolo primario.
Per altre informazioni sulle condizioni necessarie per un failover automatico, vedere le condizioni necessarie per un failover automatico e le repliche con commit sincrono supportano due sezioni delle impostazioni di Failover e modalità di failover (gruppi di disponibilità AlwaysOn).
Per analizzare e diagnosticare se si tratta della causa del failover non riuscito, esaminare il log degli errori di SQL Server. Dovrebbe essere presente una voce di errore simile al testo seguente:
Uno o più database non sono sincronizzati o non sono stati aggiunti al gruppo di disponibilità.
Per verificare se i database di disponibilità erano nello SYNCHRONIZED stato, seguire questa procedura:
Connettersi alla replica secondaria.
Eseguire lo script SQL seguente per controllare il
is_failover_readyvalore di tutti i database di disponibilità nel gruppo di disponibilità che non ha eseguito il failover.Note
Un valore pari a zero per uno dei database di disponibilità può impedire il failover automatico. Questo valore indica che il database di disponibilità non
SYNCHRONIZEDera .SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)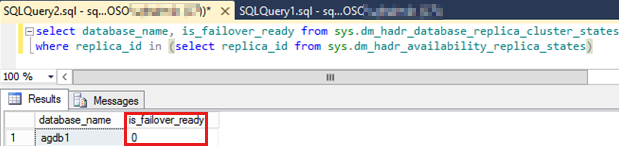
Conclusione
Un failover automatico riuscito del gruppo di disponibilità richiede che tutti i database di disponibilità siano nello SYNCHRONIZED stato . Per altre informazioni sulle modalità di disponibilità, vedere Modalità di disponibilità nei gruppi di disponibilità AlwaysOn.
Caso 4: la configurazione "Forza crittografia protocollo" è selezionata per i protocolli client nella replica secondaria (primaria di destinazione) anche se la replica non è configurata per la crittografia
Durante il failover, quando il server primario rileva un problema di integrità, la DLL del cluster nel partner di failover (replica secondaria) tenta di connettersi alla replica locale per avviare il monitoraggio dell'integrità. Questa è parte della transizione al ruolo primario. Se la replica secondaria non è configurata per la crittografia, ma l'impostazione Forza crittografia protocollo è impostata inavvertitamente nella configurazione client, la connessione avrà esito negativo e il failover non può verificarsi.
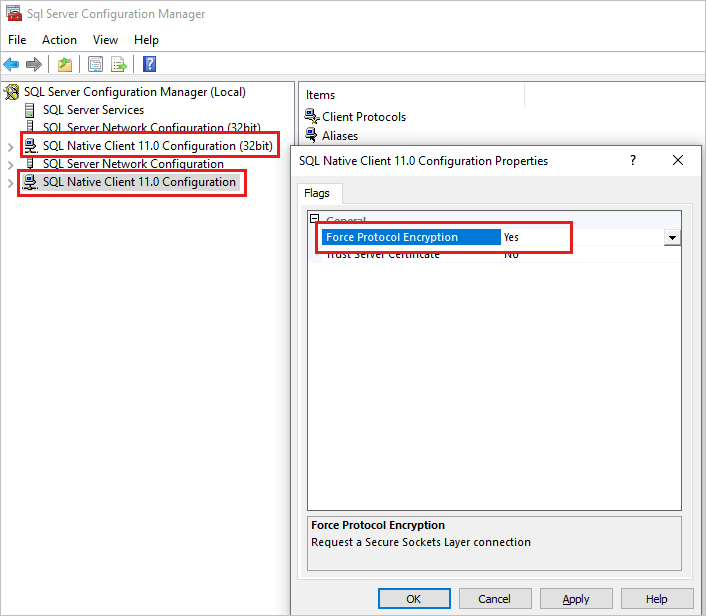
Per verificare la presenza di questa configurazione:
- Avviare Gestione configurazione SQL Server.
- Nel riquadro sinistro fare clic con il pulsante destro del mouse sulla configurazione di SQL Native Client 11.0 e quindi scegliere Proprietà.
- Nella finestra di dialogo selezionare l'impostazione Forza crittografia protocollo. Se è impostato su Sì, modificare il valore su No.
- Eseguire di nuovo il failover.
Conclusione
Il monitoraggio dell'integrità AlwaysOn di SQL Server usa una connessione ODBC locale per monitorare l'integrità di SQL Server. È consigliabile abilitare Force Protocol Encryption nella sezione Configurazione client di Gestione configurazione SQL Server solo se SQL Server è stato configurato per forzare la crittografia in Gestione configurazione SQL Server nella sezione Configurazione di rete di SQL Server. Per ulteriori informazioni, vedere Abilitare connessioni crittografate al motore di database.
Caso 5: i problemi di prestazioni nella replica secondaria o nel nodo causano l'esito negativo dei controlli di integrità AlwaysOn
Prima di eseguire il failover dalla replica primaria alla replica secondaria, SQL Server motore di database DLL di risorse si connette alla replica secondaria per verificare l'integrità della replica. Se la connessione non riesce a causa di problemi di prestazioni nella replica secondaria, il failover automatico non si verifica.
Per analizzare e diagnosticare se si tratta della causa, seguire questa procedura:
Esaminare il log del cluster nella replica secondaria per verificare la presenza del messaggio di errore "Impossibile completare il processo di accesso a causa di un ritardo nell'apertura della connessione al server".
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.Questa situazione può verificarsi se il failover viene eseguito in una replica secondaria di SQL Server con un carico di lavoro esistente occupato. Ciò potrebbe ritardare la risposta di SQL Server al tentativo di connessione all'integrità HADR e impedire un tentativo di failover riuscito.
Per determinare se sono presenti pressioni sulle utilità di pianificazione del sistema, usare SQL Server Management Studio per eseguire lo script seguente nella replica secondaria:
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' ENDDi seguito è riportato l'output di esempio della query precedente:
CurrentDate TotalThreads CurrentThreads AvailableThreads WorkersWaitingForCpu RequestWaitingForThreads 2020-10-06 01:27:01.337 1216 361 855 33 0 2020-10-06 01:27:08.340 1216 1412 -196 22 76 2020-10-06 01:27:15.340 1216 1304 -88 2 161 2020-10-06 01:27:22.340 1216 1242 26- 21 185 2020-10-06 01:27:29.343 1216 1346 -130 19 476 2020-10-06 01:27:36.350 1216 1350 -134 9 630 2020-10-06 01:27:43.353 1216 1346 -130 13 539 2020-10-06 01:27:50.360 1216 1378 -162 5 328 2020-10-06 01:27:57.360 1216 197 1019 0 0 Valori elevati segnalati per
WorkersWaitingForCpueRequestWaitingForThreadsindicano che si sta verificando una contesa di pianificazione e che SQL Server non è in grado di eseguire il servizio del carico di lavoro corrente in modo tempestivo.
Risoluzione
Se si verifica questo problema, ribilanciare il carico di lavoro nella replica secondaria o valutare la possibilità di aumentare la potenza di elaborazione (aggiungere processori) nei computer che eseguono questi carichi di lavoro.
Risolvere gli altri eventi di failover non riusciti
Per monitorare l'integrità della nuova replica primaria durante il failover, è necessario connettere localmente il monitoraggio dell'integrità AlwaysOn all'istanza di SQL Server che esegue la transizione al ruolo primario.
Oltre ai motivi più comuni descritti in questo articolo, esistono molti altri motivi per cui questo tentativo di connessione potrebbe non riuscire. Per esaminare ulteriormente un tentativo di failover non riuscito, esaminare il log del cluster nel partner di failover (la replica a cui non è stato possibile eseguire il failover):
Usare Windows PowerShell per generare il log del cluster Windows nel nodo del cluster. A tale scopo, eseguire il cmdlet seguente in una finestra di PowerShell con privilegi elevati nell'istanza di SQL Server che ospita la replica secondaria che non è stata eseguita la transizione al ruolo primario. Verrà generato un log del cluster per gli ultimi 60 minuti di attività.
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60Per esaminare il log del cluster di Windows, aprire il file Cluster.log nel Blocco note.
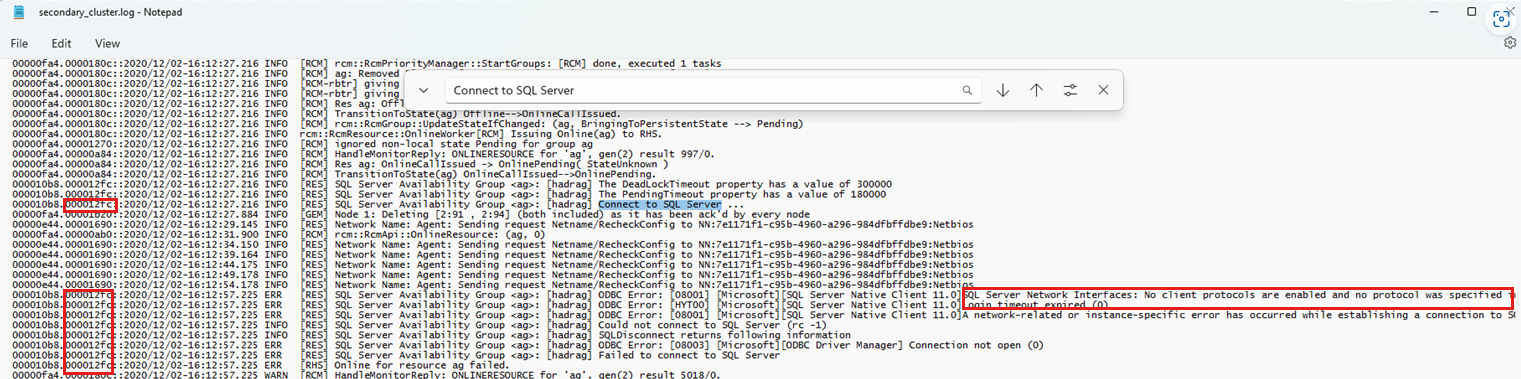
Cercare la stringa "Connetti a SQL Server" che cade durante l'evento di failover non riuscito.
Esaminare i messaggi di accesso successivi usando l'ID thread (vedere lo screenshot seguente) per correlare gli eventi correlati all'evento di accesso. L'esempio seguente mostra una ricerca "Connetti a SQL Server". Viene inoltre illustrato l'uso dell'ID thread (a sinistra) per individuare le altre diagnostica che descrivono il motivo per cui il tentativo di connessione non è riuscito.

Negli esempi seguenti vengono illustrati gli errori di connessione alla nuova replica primaria.
Set di esempio 1
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
Risoluzione
Avviare Gestione configurazione SQL Server e quindi verificare che la memoria condivisa o TCP/IP sia abilitata in Protocolli client per la configurazione di SQL Native Client.
Set di esempio 2
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
Risoluzione
Avviare Gestione configurazione SQL Server e quindi verificare che la memoria condivisa o TCP/IP sia abilitata in Protocolli client per la configurazione di SQL Native Client.
Set di esempio 3
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
Risoluzione
Esaminare il caso 2: Autorizzazioni dell'account NT Authority\SYSTEM insufficienti.