Ottimizzare le tabelle delta
Spark è un framework per l'elaborazione parallela, con i dati archiviati in uno o più nodi di lavoro. Inoltre, i file Parquet non sono modificabili e vengono scritti nuovi file per ogni aggiornamento o eliminazione. Questo processo può comportare l'archiviazione dei dati da parte di Spark in un numero elevato di file di piccole dimensioni, noto come problema dei file di piccole dimensioni. Ciò significa che le query su grandi quantità di dati possono essere eseguite lentamente o addirittura non essere completate.
Funzione OptimizeWrite
OptimizeWrite è una funzionalità di Delta Lake che riduce il numero di file durante la scrittura. Invece di scrivere molti file di piccole dimensioni, scrive meno file di grandi dimensioni. In questo modo si evita il problema dei file di piccole dimensioni e si garantisce che le prestazioni non vengano compromesse.
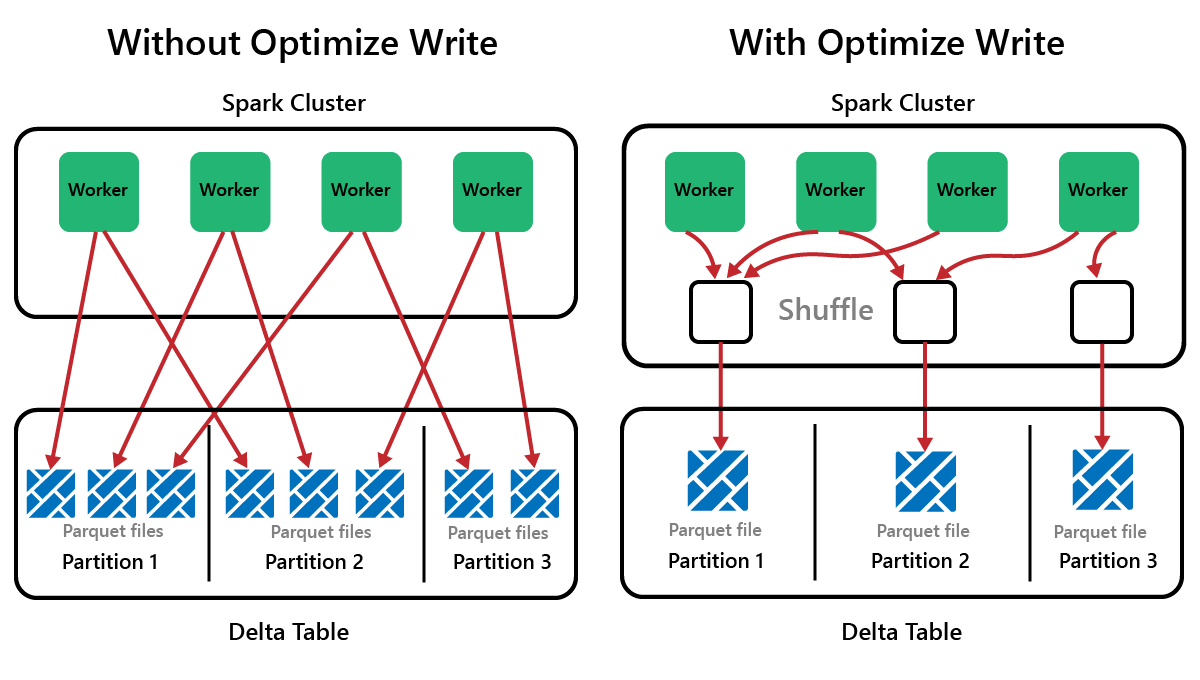
In Microsoft Fabric, OptimizeWrite è abilitato per impostazione predefinita. È possibile abilitarlo o disabilitarlo a livello di sessione Spark:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Nota
OptimizeWrite può essere impostato anche in Proprietà tabella e per i singoli comandi di scrittura.
Ottimizzazione
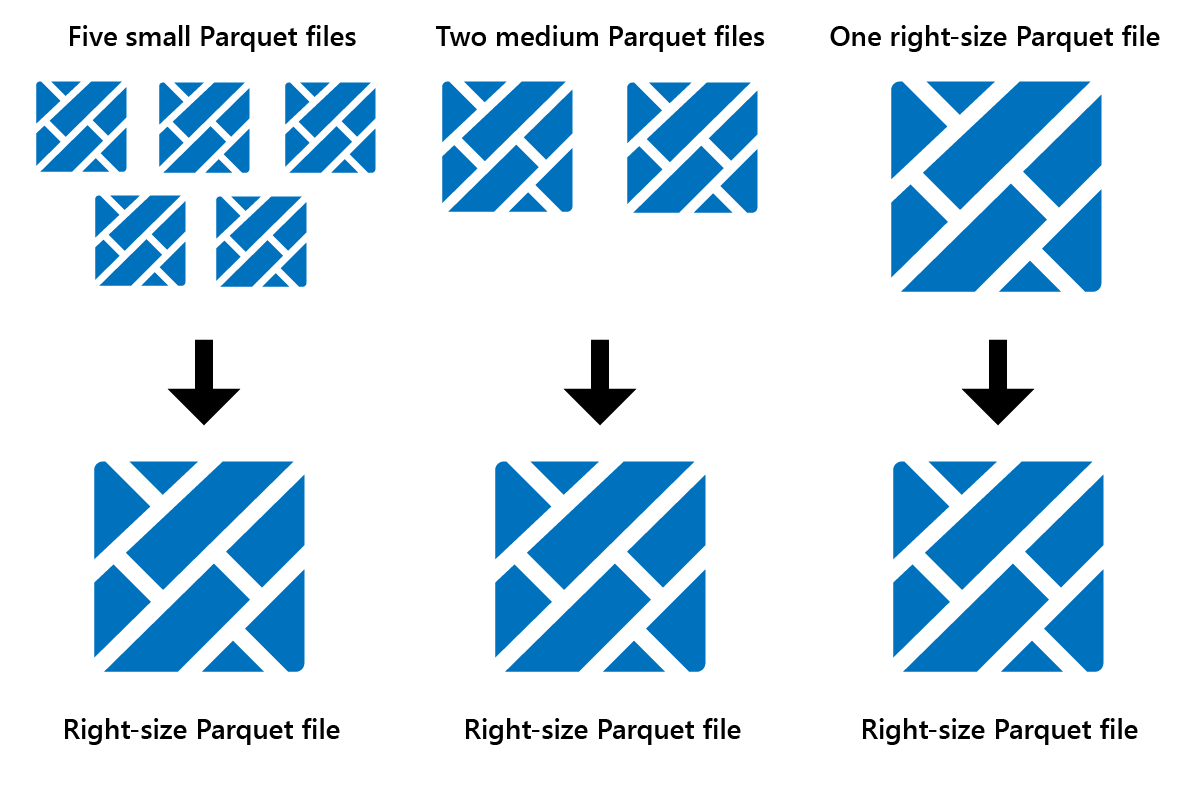
Ottimizza è una funzionalità di manutenzione delle tabelle che consolida i file Parquet di piccole dimensioni in un numero inferiore di file di grandi dimensioni. Si può eseguire Ottimizza dopo il caricamento di tabelle di grandi dimensioni, determinando:
- meno file di grandi dimensioni
- migliore compressione
- distribuzione efficiente dei dati tra nodi
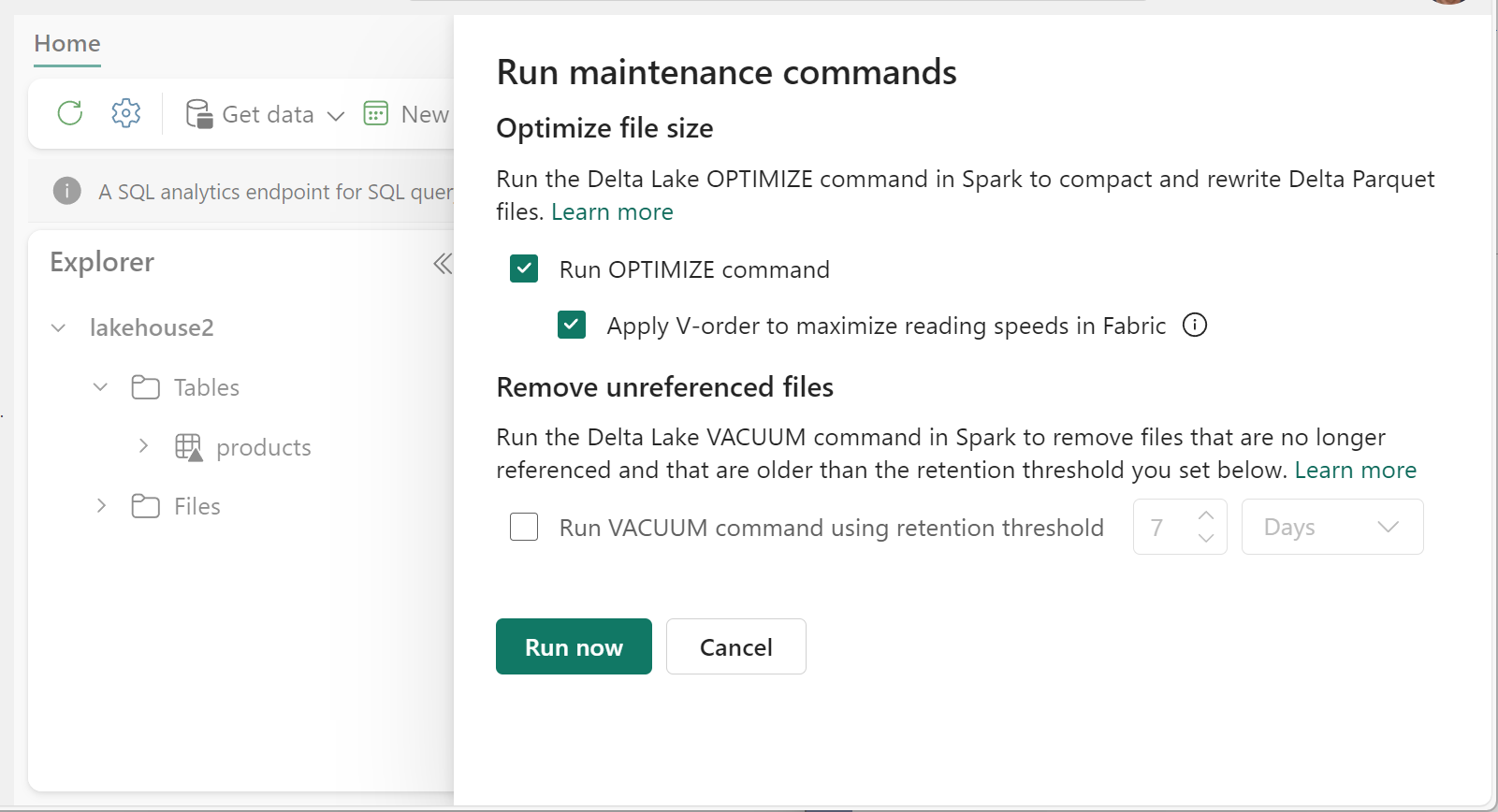
Per eseguire Ottimizza:
- In Lakehouse Explorer selezionare il menu ... accanto a un nome di tabella e selezionare Manutenzione.
- Selezionare Esegui il comando OPTIMIZE.
- Selezionare facoltativamente Applica V-Order per ottimizzare la velocità di lettura in Fabric.
- Selezionare Esegui ora.
Funzione V-Order
Quando si esegue Ottimizza, è possibile eseguire facoltativamente V-Order, progettato per il formato di file Parquet in Fabric. V-Order consente letture rapidissime, con tempi di accesso ai dati simili a quelli in memoria. Migliora inoltre l'efficienza dei costi in quanto riduce le risorse di rete, disco e CPU durante la lettura.
Il V-Order è abilitato per impostazione predefinita in Microsoft Fabric e viene applicato durante la scrittura dei dati. Comporta un piccolo sovraccarico di circa il 15% rendendo le scritture un po' più lente. Tuttavia, V-Order consente letture più veloci dai motori di calcolo di Microsoft Fabric, ad esempio Power BI, SQL, Spark e altri.
In Microsoft Fabric, i motori Power BI e SQL usano la tecnologia Microsoft Verti-Scan che sfrutta appieno l'ottimizzazione di V-Order per velocizzare le letture. Spark e altri motori non usano la tecnologia VertiScan, ma traggono comunque vantaggio dall'ottimizzazione V-Order con letture più veloci di circa il 10%, a volte fino al 50%.
V-Order funziona applicando ordinamento speciale, distribuzione di gruppi di righe, codifica del dizionario e compressione nei file Parquet. È conforme al 100% al formato Parquet open source e tutti i motori Parquet possono leggerlo.
Il V-Order potrebbe non essere utile per scenari ad alta intensità di scrittura, ad esempio gli archivi dati di staging in cui i dati vengono letti solo una o due volte. In queste situazioni, la disabilitazione di V-Order potrebbe ridurre il tempo di elaborazione complessivo per l'inserimento dati.
Applicare V-Order alle singole tabelle usando la funzione Manutenzione tabelle con il comando OPTIMIZE.
Vacuum
Il comando VACUUM consente di rimuovere i file di dati precedenti.
Ogni volta che viene eseguito un aggiornamento o un'eliminazione, viene creato un nuovo file Parquet e viene inserita una voce nel log delle transazioni. I file Parquet obsoleti vengono conservati per consentire i viaggi nel tempo, il che significa che i file Parquet si accumulano nel tempo.
Il comando VACUUM rimuove i vecchi file di dati Parquet, ma non i log delle transazioni. Quando si esegue VACUUM, non è possibile tornare indietro nel tempo prima del periodo di conservazione.
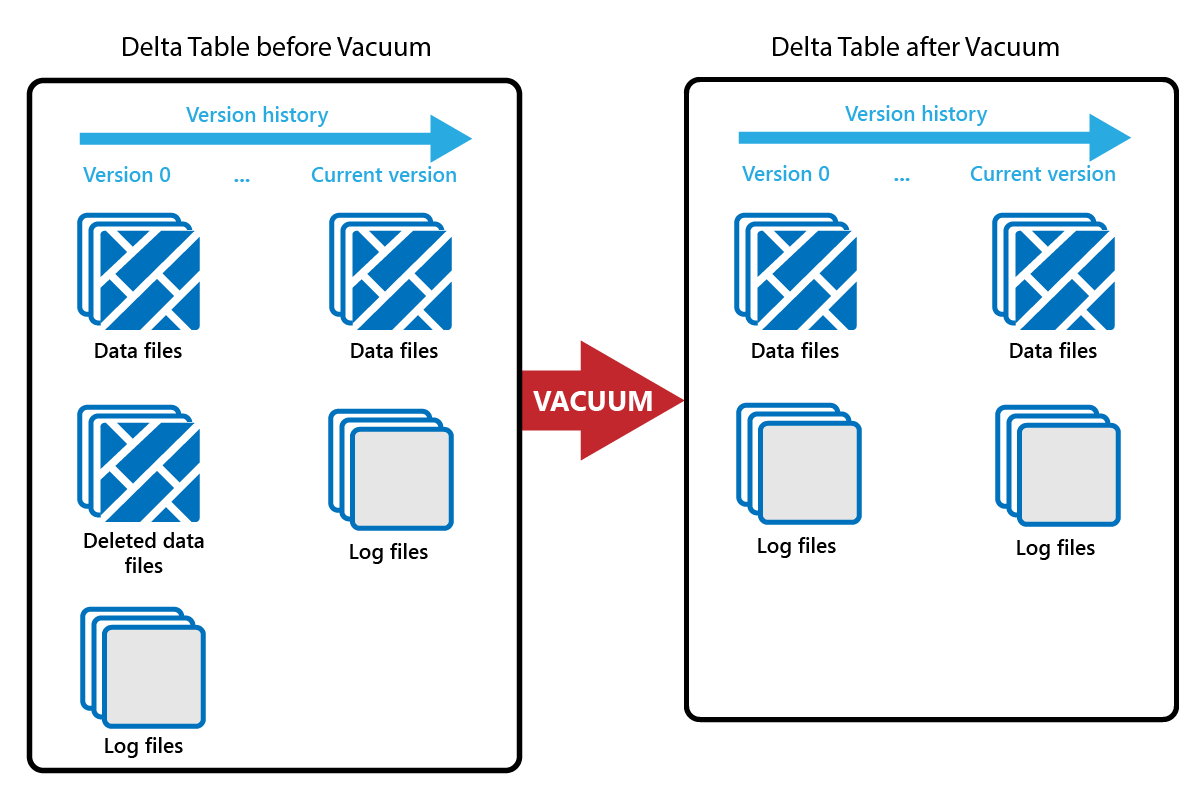
I file di dati a cui attualmente non si fa riferimento in un log delle transazioni e che sono precedenti al periodo di conservazione specificato vengono eliminati definitivamente eseguendo VACUUM. Scegliere il periodo di conservazione in base a fattori quali:
- Requisiti di conservazione dei dati
- Dimensioni dei dati e costi di archiviazione
- Frequenza di modifica dei dati
- Requisiti normativi
Il periodo di conservazione predefinito è di 7 giorni (168 ore) e il sistema impedisce di usare un periodo di conservazione più breve.
È possibile eseguire VACUUM su base ad hoc o pianificato usando i notebook Fabric.
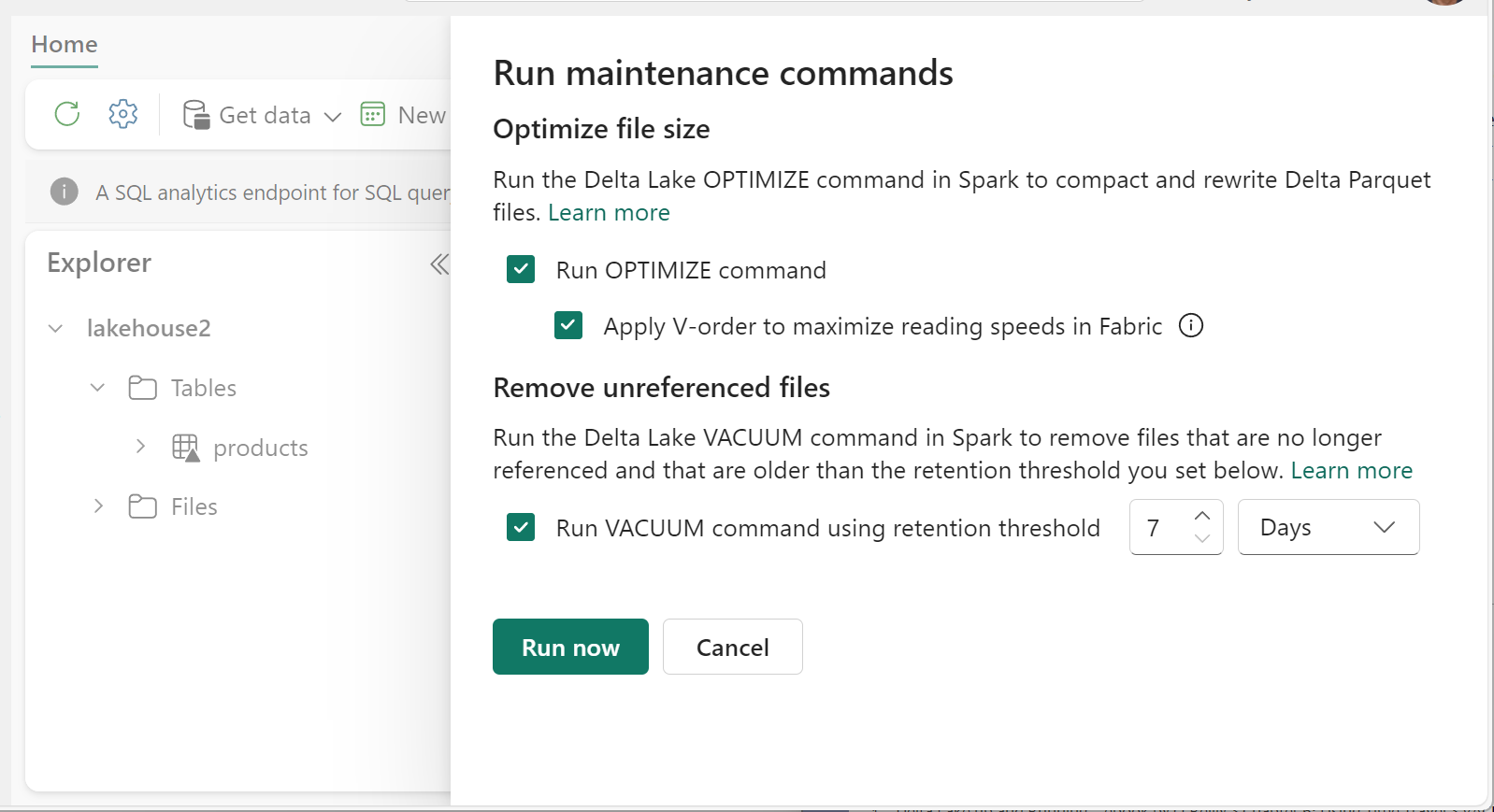
Eseguire VACUUM in singole tabelle usando la funzionalità di manutenzione delle tabelle:
- In Lakehouse Explorer selezionare il menu ... accanto a un nome di tabella e selezionare Manutenzione.
- Selezionare Esegui il comando VACUUM usando la soglia di conservazione e impostare la soglia di conservazione.
- Selezionare Esegui ora.
È anche possibile eseguire VACUUM come comando SQL in un notebook:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
VACUUM esegue il commit nel log delle transazioni Delta, in modo da poter visualizzare le esecuzioni precedenti in DESCRIBE HISTORY.
%%sql
DESCRIBE HISTORY lakehouse2.products;
Partizione delle tabelle Delta
Delta Lake consente di organizzare i dati in partizioni. Ciò potrebbe migliorare le prestazioni abilitando lo skipping dei dati, che aumenta le prestazioni ignorando gli oggetti dati irrilevanti in base ai metadati di un oggetto.
Si consideri una situazione in cui vengono archiviate grandi quantità di dati di vendita. È possibile partizionare i dati di vendita per anno. Le partizioni vengono archiviate in sottocartelle denominate "anno=2021", "anno=2022", e così via. Per creare report solo sui dati di vendita per il 2024, è possibile saltare le partizioni per gli altri anni, migliorando così le prestazioni di lettura.
Il partizionamento di piccole quantità di dati può tuttavia può ridurre le prestazioni perché aumenta il numero di file e può peggiorare il "problema dei file di piccole dimensioni".
Usare il partizionamento quando:
- Si hanno grandi quantità di dati.
- Le tabelle possono essere suddivise in alcune partizioni di grandi dimensioni.
Non usare il partizionamento quando:
- I volumi di dati sono di piccole dimensioni.
- La colonna di partizionamento ha una cardinalità elevata, in quanto crea un numero elevato di partizioni.
- Una colonna di partizionamento può dare origine a più livelli.
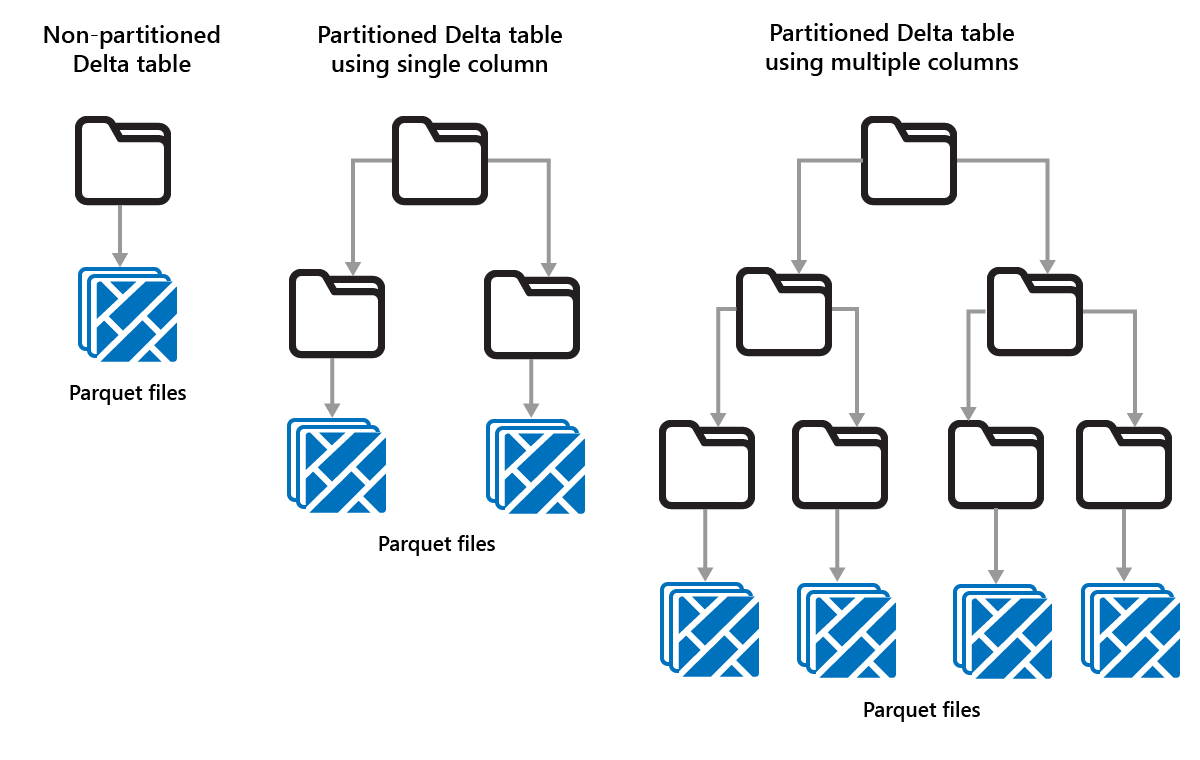
Le partizioni sono un layout di dati fisso e non si adattano a modelli di query diversi. Quando si valuta come usare il partizionamento, si pensi a come vengono usati i dati e alla loro granularità.
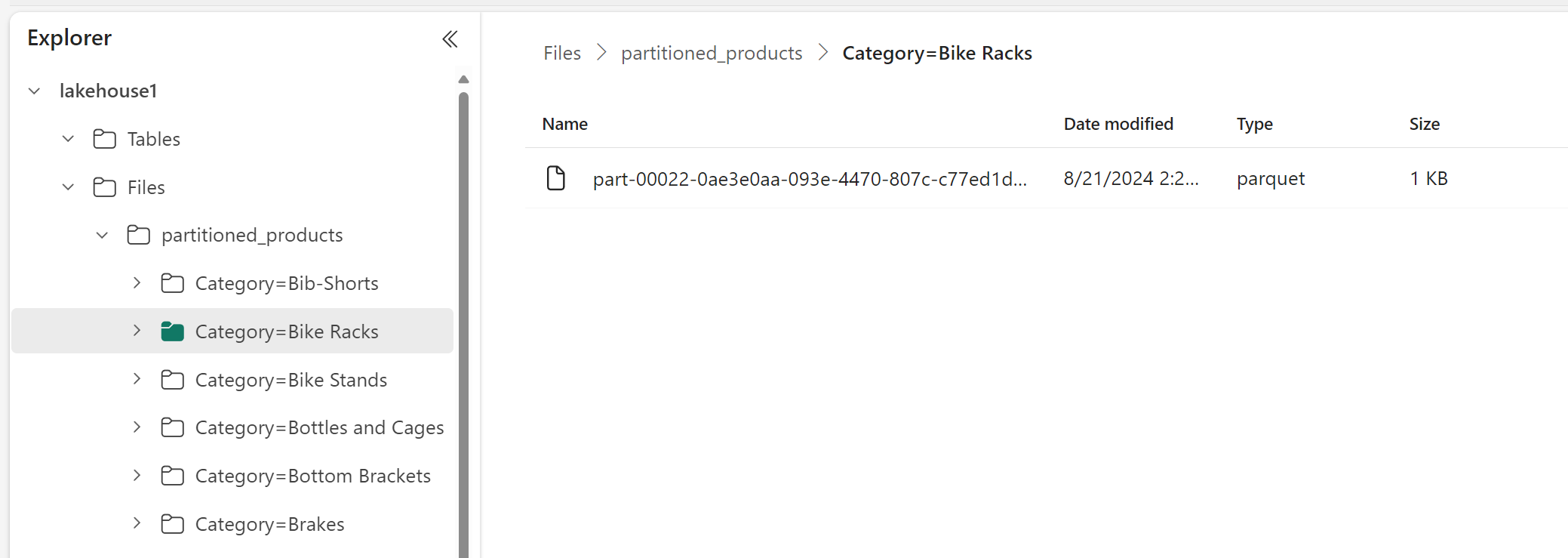
In questo esempio, un DataFrame contenente dati del prodotto è suddiviso per categoria:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
In Lakehouse Explorer è possibile vedere che i dati sono una tabella partizionata.
- È presente una cartella per la tabella denominata "partitioned_products".
- Sono presenti sottocartelle per ciascuna categoria, ad esempio "Categoria=Portabici", ecc.
È possibile creare una tabella partizionata simile usando SQL:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);