Informazioni su Delta Lake
Delta Lake è un livello di archiviazione open source che aggiunge la semantica dei database relazionali all'elaborazione dei data lake basata su Spark. Le tabelle nei lakehouse di Microsoft Fabric sono tabelle Delta, come indicato dall'icona Delta triangolare (Δ) sulle tabelle nell'interfaccia utente del lakehouse.
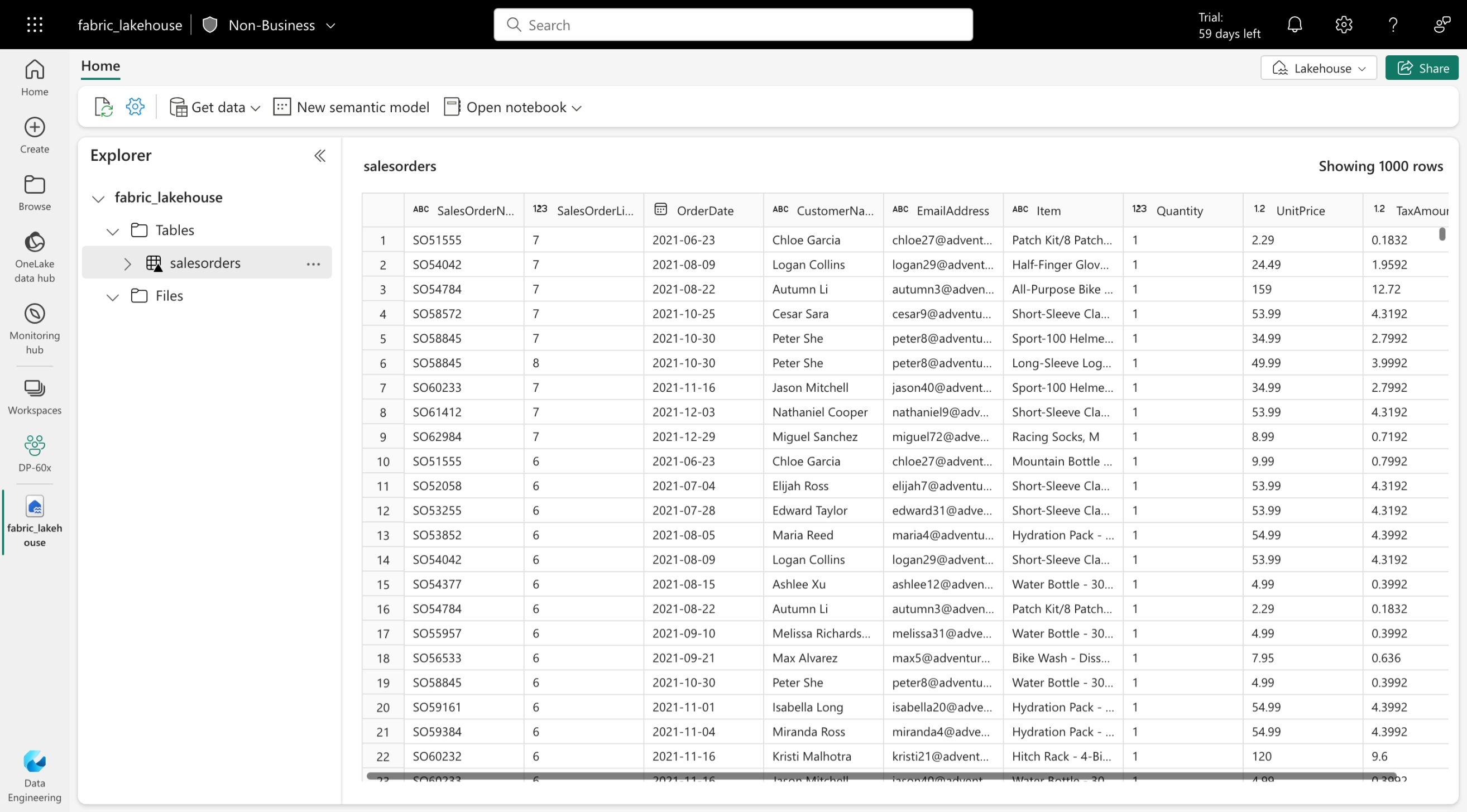
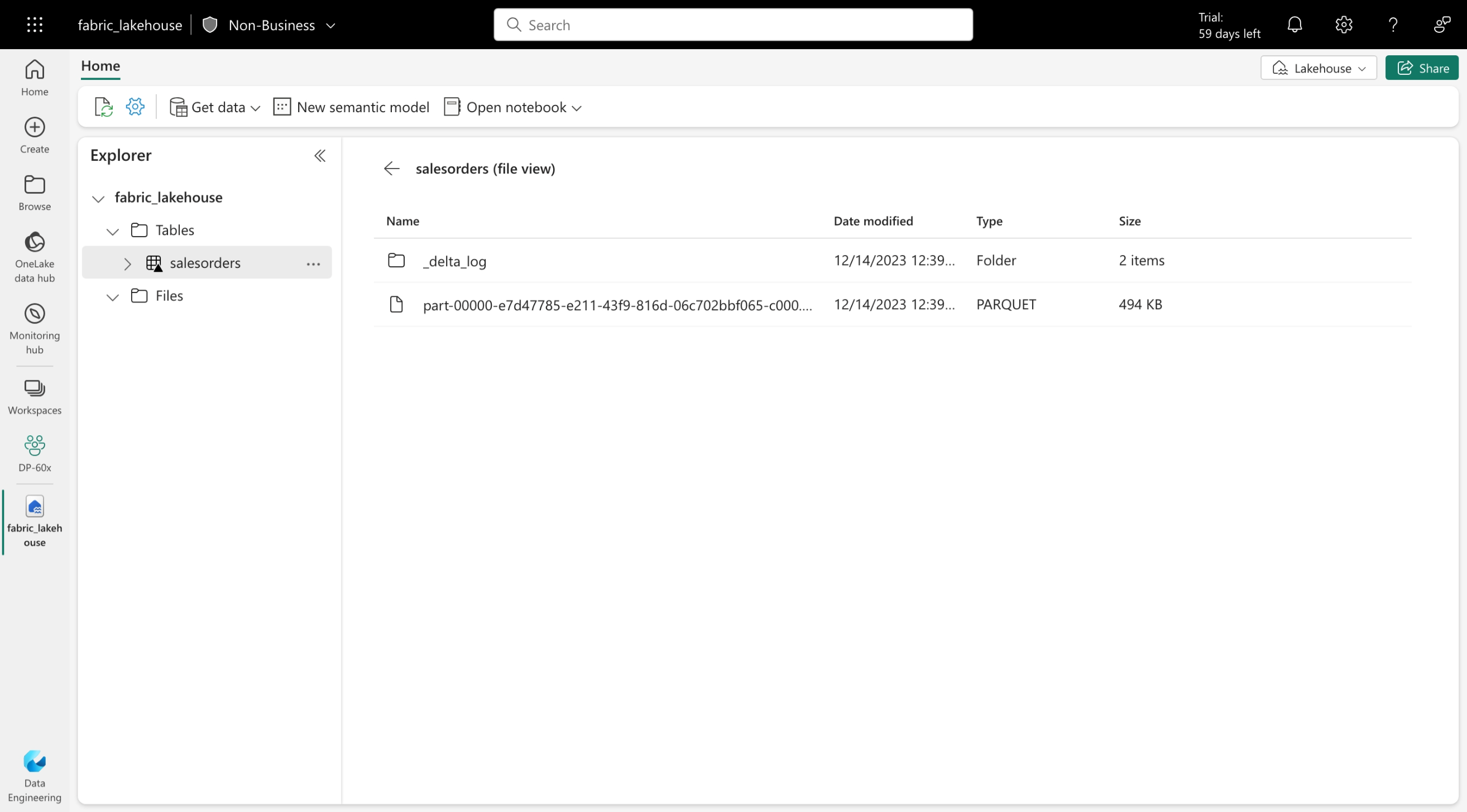
Le tabelle Delta sono astrazioni dello schema sui file di dati archiviati in formato Delta. Per ogni tabella, il lakehouse archivia una cartella contenente file di dati Parquet e una cartella _delta_Log in cui vengono registrati i dettagli delle transazioni in formato JSON.
I vantaggi dell'uso delle tabelle Delta includono:
- Tabelle relazionali che supportano l'esecuzione di query e la modifica dei dati. Con Apache Spark è possibile archiviare i dati nelle tabelle Delta che supportano operazioni CRUD (Create, Read, Update, Delete). In altre parole, è possibile selezionare, inserire, aggiornare ed eliminare righe di dati nello stesso modo in cui si farebbe in un sistema di database relazionale.
- Supporto per le transazioni ACID. I database relazionali sono progettati per supportare modifiche ai dati transazionali che offrono atomicità (le transazioni vengono eseguite come singola unità di lavoro), coerenza (le transazioni lasciano il database in uno stato coerente), isolamento (le transazioni In-Process non possono interferire l'una con l'altra) e durabilità (quando una transazione viene completata, le modifiche apportate sono persistenti). Delta Lake offre questo stesso supporto transazionale a Spark implementando un log delle transazioni e applicando l'isolamento serializzabile per le operazioni simultanee.
- Controllo delle versioni dei dati e spostamento cronologico. Poiché tutte le transazioni vengono registrate nel log delle transazioni, è possibile tenere traccia di più versioni di ogni riga di tabella e anche usare la funzionalità di spostamento cronologico per recuperare una versione precedente di una riga in una query.
- Supporto per i dati in batch e in streaming. Anche se la maggior parte dei database relazionali include tabelle che archiviano dati statici, Spark include il supporto nativo per lo streaming dei dati tramite l'API Spark Structured Streaming. Le tabelle di Delta Lake possono essere usate come sink (destinazioni) e origini per i dati in streaming.
- Formati standard e interoperabilità. I dati sottostanti per le tabelle Delta vengono archiviati nel formato Parquet, comunemente usato nelle pipeline di inserimento di data lake. È anche possibile usare l'endpoint di Analisi SQL per il lakehouse di Microsoft Fabric per eseguire query sulle tabelle Delta in SQL.