Scegliere la destinazione di calcolo appropriata
In Azure Machine Learning le destinazioni di calcolo sono computer fisici o virtuali in cui vengono eseguiti i processi.
Informazioni sui tipi di calcolo disponibili
Azure Machine Learning supporta più tipi di calcolo per la sperimentazione, il training e la distribuzione. Con più tipi di calcolo, è possibile selezionare il tipo di destinazione di calcolo più appropriato per le proprie esigenze.
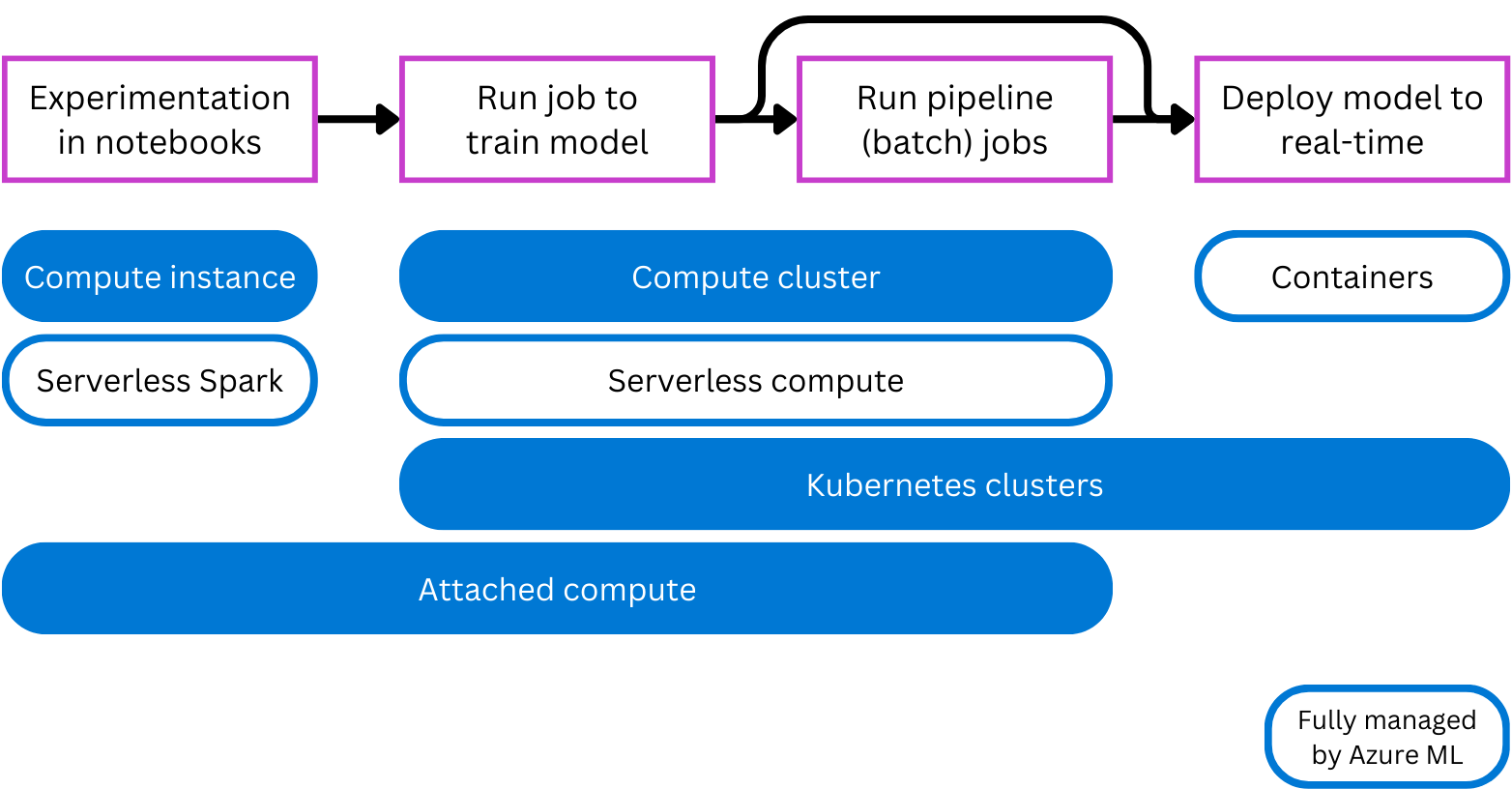
- L'istanza di calcolo: si comporta in modo analogo a una macchina virtuale ed è usata principalmente per eseguire i notebook. È ideale per la sperimentazione.
- cluster di calcolo: cluster multinodo di macchine virtuali che aumentano o riduceno automaticamente le prestazioni per soddisfare la domanda. Un modo conveniente per eseguire script che devono elaborare grandi volumi di dati. I cluster consentono anche di usare l'elaborazione parallela per distribuire il carico di lavoro e ridurre il tempo necessario per eseguire uno script.
- cluster Kubernetes: cluster basato sulla tecnologia Kubernetes, offrendo maggiore controllo sulla configurazione e la gestione del calcolo. È possibile collegare il cluster Azure Kubernetes (AKS) autogestito per il calcolo cloud o un cluster Kubernetes Arc per carichi di lavoro locali.
- di calcolo collegato: consente di collegare risorse di calcolo esistenti come, ad esempio, macchine virtuali di Azure o cluster di Azure Databricks, all'area di lavoro.
- Calcolo serverless: un ambiente di calcolo completamente gestito e su richiesta che puoi utilizzare per i compiti di addestramento.
Nota
Azure Machine Learning offre la possibilità di creare e gestire risorse di calcolo personalizzate o di usare il calcolo completamente gestito da Azure Machine Learning.
Quando usare quale tipo di calcolo?
In generale, esistono alcune procedure consigliate che è possibile seguire quando si lavora con le destinazioni di calcolo. Per comprendere come scegliere il tipo di calcolo appropriato, vengono forniti diversi esempi. Tenere presente che il tipo di calcolo usato dipende sempre dalla situazione specifica.
Scegliere un obiettivo di calcolo per l'esperimento
Si supponga di essere un data scientist e di sviluppare un nuovo modello di Machine Learning. È probabile che si disponga di un piccolo subset dei dati di training con cui è possibile sperimentare.
Durante la sperimentazione e lo sviluppo, si preferisce lavorare in un notebook di Jupyter. Un'esperienza notebook offre la maggior parte dei vantaggi di un ambiente di calcolo in esecuzione continua.
Molti data scientist hanno familiarità con l'esecuzione di notebook nel dispositivo locale. Un'alternativa cloud gestita da Azure Machine Learning è un'istanza di calcolo . In alternativa, puoi anche optare per il calcolo serverless Spark per eseguire codice Spark nei notebook, se desideri sfruttare la potenza di calcolo distribuita di Spark.
Scegliere un obiettivo di calcolo per la produzione
Dopo la sperimentazione, è possibile eseguire il training dei modelli eseguendo script Python per prepararsi per la produzione. Gli script saranno più facili da automatizzare e pianificare quando si vuole ripetere il training del modello in modo continuo nel tempo. È possibile eseguire script come attività (pipeline).
Quando si passa all'ambiente di produzione, si vuole che la destinazione di calcolo sia pronta per gestire grandi volumi di dati. Maggiore sarà il numero di dati usati, migliore sarà il modello di Machine Learning.
Quando si esegue il training dei modelli con script, si vuole una destinazione di calcolo su richiesta. Un cluster di calcolo aumenta automaticamente le prestazioni quando è necessario eseguire gli script e riduce le prestazioni al termine dell'esecuzione dello script. Se si vuole un'alternativa che non è necessario creare e gestire, è possibile usare l'di calcolo serverless di Azure Machine Learning.
Scegliere un target di calcolo per la distribuzione
Il tipo di calcolo necessario quando si usa il modello per generare stime dipende dalla necessità di stime batch o in tempo reale.
Per le stime batch, è possibile eseguire un processo pipeline in Azure Machine Learning. Le destinazioni di calcolo, ad esempio cluster di calcolo e calcolo serverless di Azure Machine Learning, sono ideali per i processi di pipeline perché sono su richiesta e scalabili.
Quando si vogliono stime in tempo reale, è necessario un tipo di calcolo in esecuzione continua. Le distribuzioni in tempo reale traggono quindi vantaggio da un calcolo più leggero (e quindi più conveniente). I contenitori sono ideali per le distribuzioni in tempo reale. Quando si distribuisce il modello in un endpoint online gestito, Azure Machine Learning crea e gestisce i contenitori per l'esecuzione del modello. In alternativa, è possibile collegare cluster Kubernetes per gestire il calcolo necessario per generare stime in tempo reale.