Esegui il codice Spark
Per modificare ed eseguire codice Spark in Microsoft Fabric, puoi usare notebook oppure definire un processo Spark.
Notebook
Quando vuoi usare Spark per esplorare e analizzare i dati in modo interattivo, usa un notebook. I notebook ti consentono di combinare testo, immagini e codice scritto in più lingue per collaborare e creare un elemento interattivo che puoi condividere con altri utenti.
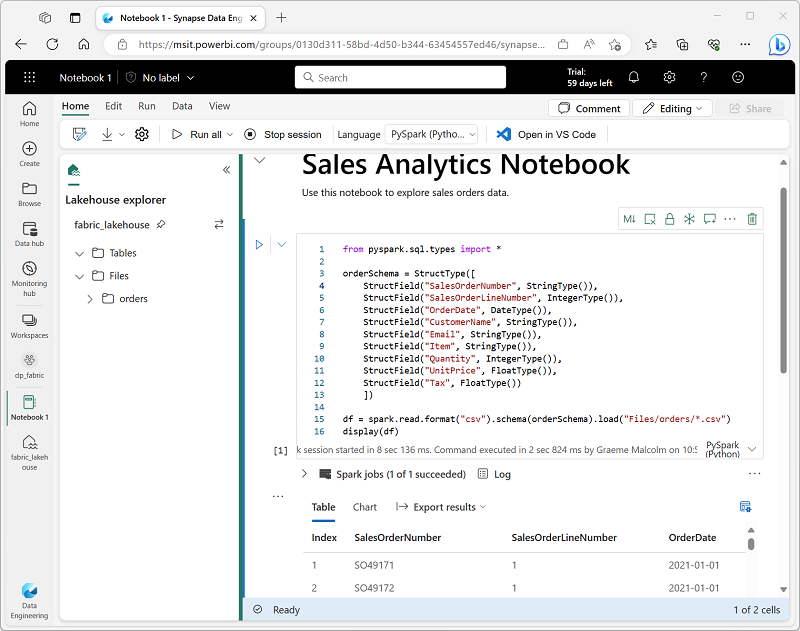
I notebook sono costituiti da una o più celle, ognuna delle quali può contenere contenuto in formato markdown o codice eseguibile. Puoi eseguire il codice in modo interattivo nel notebook e visualizzare immediatamente i risultati.
Definizione di processo Spark
Se vuoi usare Spark per inserire e trasformare i dati come parte di un processo automatizzato, puoi definire un processo Spark per eseguire uno script su richiesta o basato su una pianificazione.
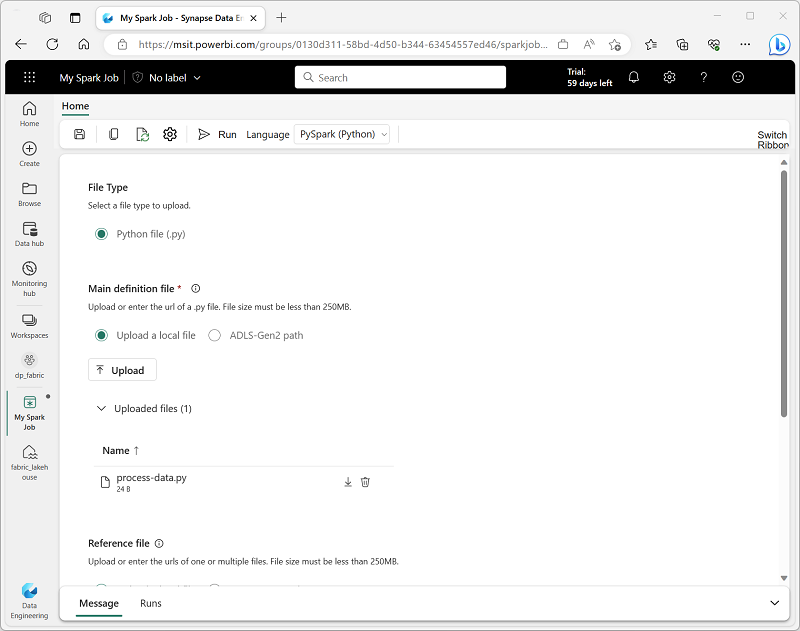
Per configurare un processo Spark, crea una definizione di processo Spark nell'area di lavoro e specifica lo script da eseguire. Puoi anche specificare un file di riferimento (ad esempio un file di codice Python contenente le definizioni di funzioni usate nello script) e un riferimento a un lakehouse specifico contenente i dati elaborati dallo script.