Usare Spark nei notebook
È possibile eseguire molti tipi diversi di applicazioni in Spark, tra cui codice in script Python o Scala, codice Java compilato come Archivio Java (JAR) e altre ancora. Spark viene comunemente usato in due tipi di carichi di lavoro:
- Processi di elaborazione in batch o in streaming per inserire, pulire e trasformare i dati, spesso in esecuzione come parte di una pipeline automatizzata.
- Sessioni di analisi interattive per esplorare, analizzare e visualizzare i dati.
Esecuzione del codice Spark nei notebook
Azure Databricks include un'interfaccia del notebook integrata per l'uso di Spark. I notebook offrono un modo intuitivo per combinare il codice con le note Markdown, comunemente usate da data scientist e analisti dei dati. L'aspetto dell'esperienza integrata dei notebook in Azure Databricks è simile a quello dei notebook di Jupyter, una piattaforma per notebook open source molto diffusa.
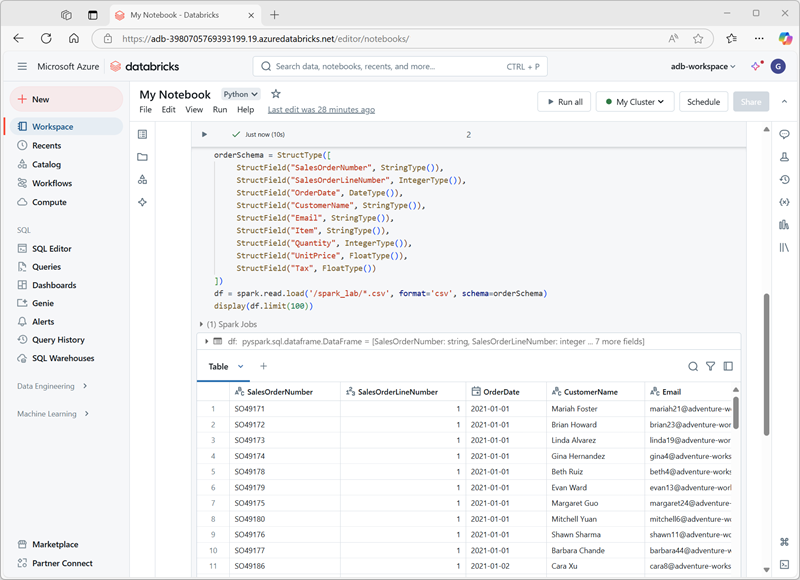
I notebook sono costituiti da una o più celle, ognuna delle quali contiene codice o Markdown. Le celle di codice nei notebook hanno alcune funzionalità che consentono di essere più produttivi, tra cui:
- Supporto per l'evidenziazione della sintassi e gli errori.
- Completamento automatico del codice.
- Visualizzazioni interattive dei dati.
- Possibilità di esportare i risultati.
Suggerimento
Per altre informazioni sull'uso dei notebook in Azure Databricks, vedere l'articolo Notebook nella documentazione di Azure Databricks.