Creare un cluster Spark
Nell'area di lavoro di Databricks è possibile creare uno o più cluster usando il portale di Azure Databricks.
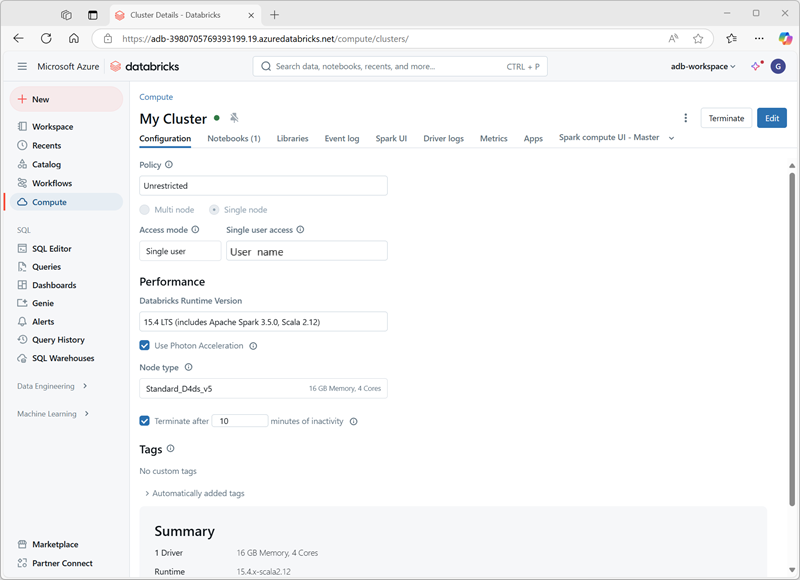
Quando si crea il cluster, è possibile specificare le impostazioni di configurazione, tra cui:
- Un nome per il cluster.
- Una modalità del cluster, che può essere:
- Standard: scelta indicata per carichi di lavoro di un singolo utente che richiedono più nodi di lavoro.
- High Concurrency: scelta indicata per carichi di lavoro in cui più utenti usano il cluster simultaneamente.
- Single Node: scelta indicata per piccoli carichi di lavoro o per i test, in cui è necessario un singolo nodo di lavoro.
- La versione di Databricks Runtime da usare nel pool, che determina le versioni di Spark e dei singoli componenti installati, ad esempio Python, Scala e altri.
- Il tipo di macchina virtuale usato per i nodi di lavoro nel cluster.
- Il numero minimo e massimo di nodi di lavoro del cluster.
- Il tipo di VM usato per il nodo driver del cluster.
- Se il cluster supporta la scalabilità automatica per ridimensionare dinamicamente il cluster.
- Quanto tempo il cluster può rimanere inattivo prima che venga arrestato automaticamente.
In che modo Azure gestisce le risorse del cluster
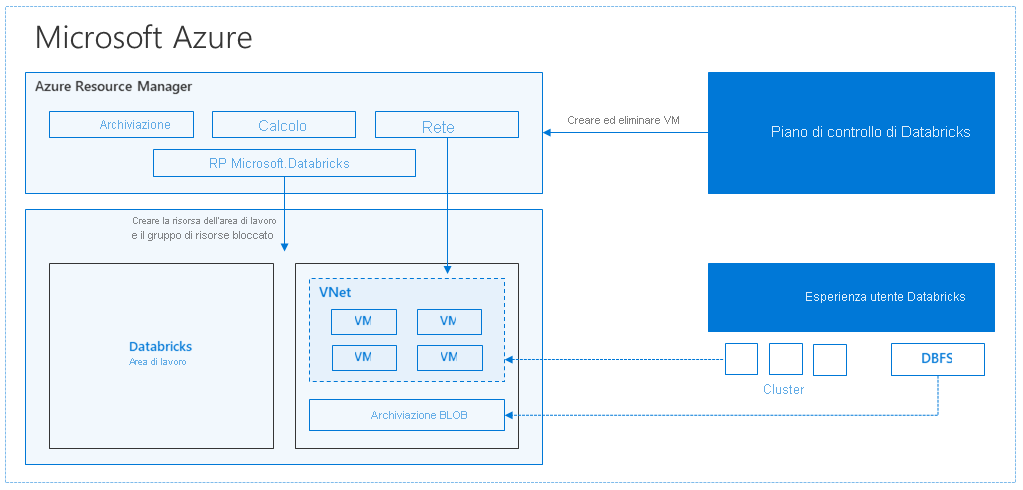
Quando si crea un'area di lavoro di Azure Databricks, viene distribuita una appliance Databricks come risorsa di Azure nella sottoscrizione. Quando si crea un cluster nell'area di lavoro, si specificano i tipi e le dimensioni delle macchine virtuali da usare per i nodi driver e di lavoro, oltre ad altre opzioni di configurazione, ma tutti gli altri aspetti del cluster vengono gestiti da Azure Databricks.
L'appliance Databricks viene distribuita in Azure come gruppo di risorse gestite all'interno della sottoscrizione. Questo gruppo di risorse contiene le VM driver e di lavoro per i cluster, oltre ad altre risorse necessarie, tra cui una rete virtuale, un gruppo di sicurezza e un account di archiviazione. Tutti i metadati per il cluster, ad esempio i processi pianificati, vengono archiviati in un database di Azure con replica geografica per la tolleranza di errore.
Il servizio Azure Kubernetes viene usato internamente per eseguire il piano di controllo e i piani dati di Azure Databricks tramite contenitori in esecuzione in hardware di Azure di ultima generazione (VM Dv3), con unità SSD NvMe in grado di offrire una latenza di 100 us in macchine virtuali di Azure a elevate prestazioni con rete accelerata. Azure Databricks utilizza queste funzionalità di Azure per migliorare ulteriormente le prestazioni di Spark. Quando i servizi all'interno di questo gruppo di risorse gestite sono pronti, sarà possibile gestire il cluster Databricks tramite l'interfaccia utente di Azure Databricks e con funzionalità come la scalabilità automatica e l'interruzione automatica.
Nota
È anche disponibile l'opzione di collegare il cluster a un pool di nodi inattivi per ridurne il tempo di avvio. Per altre informazioni, vedere Pool nella documentazione di Azure Databricks.