Introduzione a Spark
Per comprendere meglio come elaborare e analizzare i dati con Apache Spark in Azure Databricks, è importante comprendere l'architettura sottostante.
Panoramica generale
Da un livello elevato, il servizio Azure Databricks avvia e gestisce i cluster Apache Spark all'interno della sottoscrizione di Azure. I cluster di Apache Spark sono gruppi di computer trattati come un singolo computer che gestiscono l'esecuzione di comandi eseguiti dai notebook. I cluster consentono l'elaborazione dei dati in parallelo in molti computer per migliorare la scalabilità e le prestazioni. Sono costituiti da un nodo driver Spark e da nodi di lavoro. Il nodo driver invia il lavoro ai nodi di lavoro e indica di eseguire il pull dei dati da un'origine dati specificata.
In Databricks l'interfaccia del notebook è in genere il programma driver. Questo programma driver contiene il ciclo principale per il programma e crea set di dati distribuiti nel cluster, quindi applica le operazioni a questi set di dati. I programmi driver accedono ad Apache Spark tramite un oggetto SparkSession indipendentemente dalla posizione di distribuzione.
Microsoft Azure gestisce il cluster e lo ridimensiona automaticamente secondo le necessità in base all'utilizzo e all'impostazione usata durante la configurazione del cluster. È anche possibile abilitare l’interruzione automatica, che consente ad Azure di terminare il cluster dopo un numero di minuti di inattività specificato.
Processi Spark in dettaglio
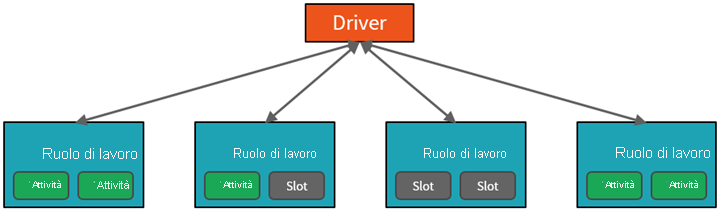
Il lavoro inviato al cluster viene suddiviso in tutti i processi indipendenti necessari. È così che il lavoro viene distribuito tra i nodi del cluster. I processi sono ulteriormente suddivisi in attività. L'input per un processo viene partizionato in una o più partizioni. Queste partizioni costituiscono l'unità di lavoro per ogni slot. Tra un'attività e l'altra, potrebbe essere necessario riorganizzare e condividere in rete le partizioni.
Il segreto per le prestazioni elevate di Spark è il parallelismo. Il ridimensionamento verticale (aggiungendo risorse a un singolo computer) è limitato a una quantità limitata di RAM, thread e velocità della CPU. I cluster possono essere però ridimensionati orizzontalmente, aggiungendo nuovi nodi al cluster in base alle esigenze.
Spark parallelizza i processi su due livelli:
- Il primo livello di parallelizzazione è l'executor, ovvero una macchina virtuale Java (JVM) in esecuzione in un nodo di lavoro, in genere un'istanza per ogni nodo.
- Il secondo livello di parallelizzazione è costituito dallo slot, il cui numero è determinato dal numero di core e CPU di ciascun nodo.
- Ogni executor ha più slot a cui è possibile assegnare attività parallelizzate.
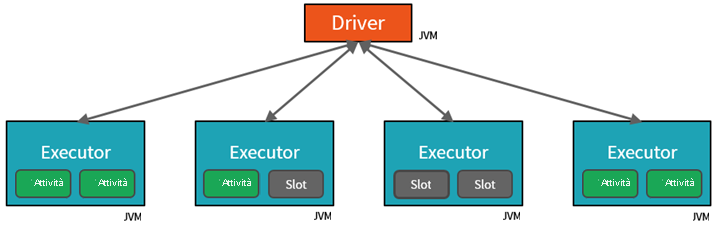
La JVM è naturalmente multithread, ma una singola JVM, ad esempio quella che coordina il lavoro sul driver, ha un limite superiore finito. Suddividendo il lavoro in attività, il driver può assegnare unità di lavoro a *slot negli executor nei nodi di lavoro per l'esecuzione parallela. Inoltre, il driver determina come partizionare i dati in modo che possano essere distribuiti per l'elaborazione parallela. Il driver assegna quindi una partizione di dati a ogni attività in modo che ogni attività sappia quale parte di dati dovrà elaborare. Una volta avviata, ogni attività recupererà la partizione dei dati ad essa assegnata.
Processi e fasi
A seconda del lavoro eseguito, potrebbero essere necessari più processi parallelizzati. Ogni processo viene suddiviso in fasi. Un'analogia utile consiste nell'immaginare che il lavoro sia quello di costruire una casa:
- La prima fase consiste nel porre le fondamenta.
- La seconda fase consiste nell'erigere i muri.
- La terza fase corrisponderebbe all'aggiunta del tetto.
Il tentativo di eseguire uno di questi passaggi in un ordine diverso dal previsto semplicemente non ha senso e potrebbe essere a tutti gli effetti impossibile. Analogamente, Spark suddivide ogni processo in fasi per assicurarsi che tutte le operazioni vengano svolte nell'ordine corretto.
Modularità
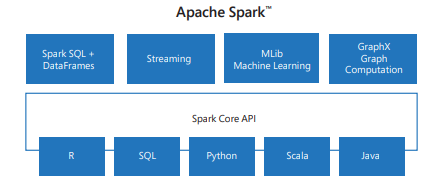
Spark include librerie per attività che vanno da SQL allo streaming multimediale e all’apprendimento automatico, che le rendono uno strumento per le attività di elaborazione dei dati. Alcune delle librerie Spark includono:
- Spark SQL: per l’uso di dati strutturati.
- SparkML: per l’apprendimento automatico.
- GraphX: per l’elaborazione dei grafi.
- Spark Streaming: per l’elaborazione dei dati in tempo reale.
Compatibilità
Spark può essere eseguito in un'ampia gamma di sistemi distribuiti, tra cui Hadoop YARN, Apache Mesos, Kubernetes o il proprio gestore cluster di Spark. Legge anche da e scrive in origini dati diverse, ad esempio HDFS, Cassandra, HBase e Amazon S3.