Usare Spark in Azure Synapse Analytics
È possibile eseguire molti tipi diversi di applicazione in Spark, tra cui codice in Script Python o Scala, codice Java compilato come archivio Java (JAR) e altri ancora. Spark viene comunemente usato in due tipi di carico di lavoro:
- Processi di elaborazione in batch o in streaming per inserire, pulire e trasformare i dati, spesso in esecuzione come parte di una pipeline automatizzata.
- Sessioni di analisi interattive per esplorare, analizzare e visualizzare i dati.
Esecuzione del codice Spark nei notebook
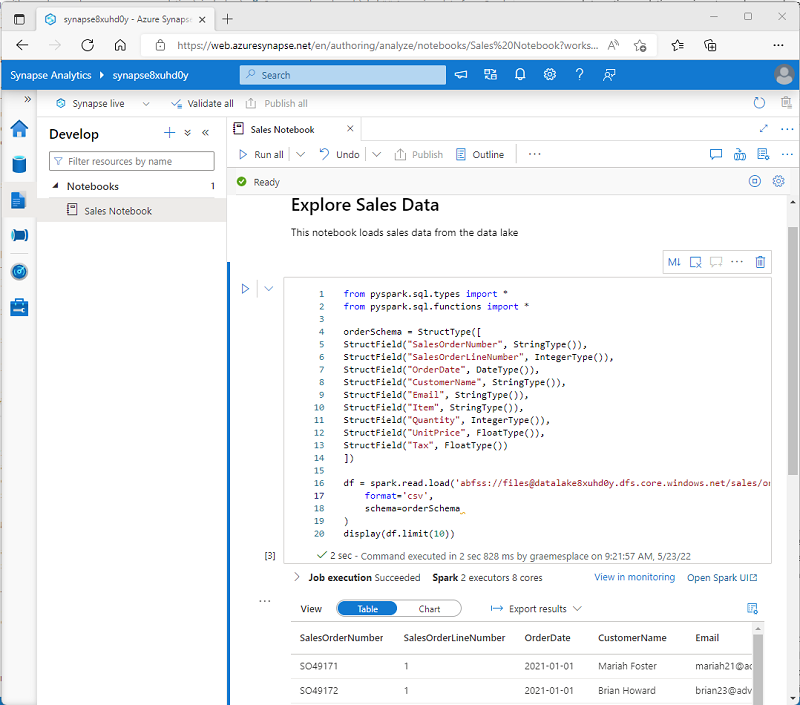
Azure Synapse Studio include un'interfaccia del notebook integrata per l'uso di Spark. I notebook offrono un modo intuitivo per combinare il codice con le note Markdown, comunemente usate da data scientist e analisti dei dati. L'aspetto dell'esperienza integrata dei notebook in Azure Synapse Studio è simile a quello dei notebook di Jupyter, una piattaforma di notebook open source molto diffusa.
Nota
Anche se vengono usati in genere in modo interattivo, i notebook possono essere inclusi nelle pipeline automatizzate ed eseguiti come script automatico.
I notebook sono costituiti da una o più celle, ognuna delle quali contiene codice o Markdown. Le celle di codice nei notebook hanno alcune funzionalità che consentono di essere più produttivi, tra cui:
- Supporto per l'evidenziazione della sintassi e gli errori.
- Completamento automatico del codice.
- Visualizzazioni interattive dei dati.
- Possibilità di esportare i risultati.
Suggerimento
Per altre informazioni sull'uso dei notebook in Azure Synapse Analytics, vedere l'articolo Creare, sviluppare e gestire i notebook di Synapse in Azure Synapse Analytics nella documentazione di Azure Synapse Analytics.
Accesso ai dati da un pool di Spark per Synapse
È possibile usare Spark in Azure Synapse Analytics per usare i dati provenienti da varie origini, tra cui:
- Data lake basato sull'account di archiviazione primario per l'area di lavoro di Azure Synapse Analytics.
- Data lake basato sull'archiviazione definita come servizio collegato nell'area di lavoro.
- Pool SQL dedicato o serverless nell'area di lavoro.
- Database di Azure SQL o SQL Server (usando il connettore Spark per SQL Server).
- Database analitico di Azure Cosmos DB definito come servizio collegato e configurato usando Collegamento ad Azure Synapse per Cosmos DB.
- Database Kusto di Esplora dati di Azure definito come servizio collegato nell'area di lavoro.
- Metastore Hive esterno definito come servizio collegato nell'area di lavoro.
Uno degli usi più comuni di Spark consiste nell'usare i dati in un data lake, dove è possibile leggere e scrivere file in più formati comunemente usati, tra cui testo delimitato, Parquet, Avro e altri ancora.