Risolvere i problemi di rete con le metriche e i log di Network Watcher
Se si vuole diagnosticare rapidamente un problema, è necessario conoscere le informazioni disponibili nei log di Azure Network Watcher.
In un'azienda di ingegneria si vuole ridurre al minimo il tempo necessario al personale per diagnosticare e risolvere eventuali problemi di configurazione di rete. Ci si vuole inoltre assicurare che il personale sappia quali informazioni sono disponibili nei log.
In questo modulo verranno esaminati i log dei flussi, i log di diagnostica e l'analisi del traffico. Si comprenderà come questi strumenti possano aiutare a risolvere i problemi della rete di Azure.
Utilizzo e quote
È possibile usare ogni risorsa Microsoft Azure fino a una specifica quota. Ogni sottoscrizione ha quote separate e l'utilizzo viene monitorato per ogni sottoscrizione. È necessaria una sola istanza di Network Watcher per sottoscrizione per area. Questa istanza offre una visualizzazione dell'utilizzo e delle quote, in modo da poter verificare se si è a rischio di raggiungere una quota.
Per visualizzare le informazioni sull'utilizzo e sulle quote, passare a Tutti i servizi>Rete>Network Watcher e quindi selezionare Utilizzo e quote. Verranno visualizzati dati granulari in base all'utilizzo e alla posizione delle risorse. Vengono acquisiti i dati per le metriche seguenti:
- Interfacce di rete
- Gruppi di sicurezza di rete (NSG)
- Reti virtuali
- Indirizzi IP pubblici
Ecco un esempio che illustra l'utilizzo e le quote nel portale:

Registri
I log di diagnostica di rete forniscono dati granulari. Questi dati potranno essere usati per comprendere meglio i problemi di connettività e di prestazioni. In Network Watcher sono disponibili tre strumenti di visualizzazione dei log:
- Log del flusso del NSG
- Log di diagnostica
- Analisi del traffico
Verranno ora esaminate le caratteristiche di ognuno di questi strumenti.
Log del flusso del NSG
Nei log dei flussi del gruppo di sicurezza di rete, è possibile visualizzare le informazioni sul traffico IP in ingresso e in uscita nei gruppi di sicurezza di rete. I log dei flussi mostrano i flussi in ingresso e in uscita in base alle singole regole e a seconda della scheda di rete a cui si applica il flusso. I log del flusso del gruppo di sicurezza di rete indicano se il traffico è stato consentito o rifiutato in base alle informazioni a 5 tuple acquisite. Queste informazioni includono:
- IP di origine
- Porta di origine
- IP destinazione
- Porta di destinazione
- Protocollo
Questo diagramma illustra il flusso di lavoro seguito dal gruppo di sicurezza di rete.
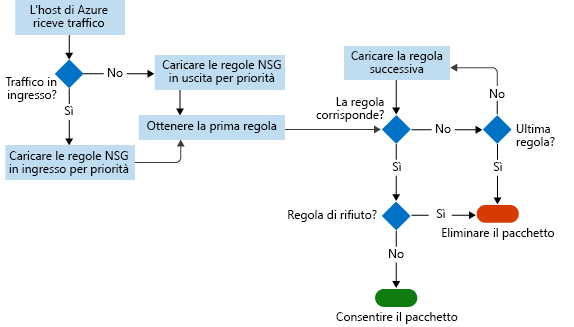
I log dei flussi archiviano i dati in un file JSON. Ottenere informazioni dettagliate su questi dati eseguendo ricerche manuali nei file di log può essere difficile, soprattutto se si ha una distribuzione dell'infrastruttura di grandi dimensioni in Azure. Per risolvere questo problema, usare Power BI.
In Power BI è possibile visualizzare i log del flusso del gruppo di sicurezza di rete in molti modi. Ad esempio:
- Talker principali (indirizzo IP)
- Flussi in base alla direzione (in ingresso e in uscita)
- Flussi in base alla decisione (consentiti e rifiutati)
- Flussi in base alla porta di destinazione
È anche possibile usare strumenti open source per analizzare i log, ad esempio Elastic Stack, Grafana e Graylog.
Nota
I log del flusso del gruppo di sicurezza di rete non supportano gli account di archiviazione nel portale di Azure classico.
Log di diagnostica
In Network Watcher, i log di diagnostica sono una posizione centrale per abilitare e disabilitare i log per le risorse di rete di Azure. Queste risorse possono includere gruppi di sicurezza di rete, IP pubblici, servizi di bilanciamento del carico e gateway applicazione. Dopo aver abilitato i log di interesse, è possibile usare gli strumenti per eseguire query e visualizzare le voci di log.
È possibile importare i log di diagnostica in Power BI e altri strumenti per analizzarli.
Analisi del traffico
Per esaminare l'attività di utenti e app nelle reti cloud, usare lo strumento Analisi del traffico.
Lo strumento fornisce informazioni dettagliate sull'attività di rete tra le sottoscrizioni. È possibile diagnosticare minacce alla sicurezza quali porte aperte, macchine virtuali che comunicano con reti non valide note e modelli di flusso del traffico. Analisi del traffico analizza i log del flusso del gruppo di sicurezza di rete tra le aree e le sottoscrizioni di Azure. È possibile usare i dati per ottimizzare le prestazioni di rete.
Questo strumento richiede Log Analytics. L'area di lavoro Log Analytics deve esistere in un'area supportata.
Scenari di casi d'uso
Verranno ora esaminati alcuni scenari di casi d'uso in cui possono risultare utili le metriche e i log di Azure Network Watcher.
Report dei clienti relativi al rallentamento delle prestazioni
Per risolvere i problemi di prestazioni rallentate, è necessario determinarne la causa radice:
- Il traffico eccessivo limita il server?
- Le dimensioni della macchina virtuale sono appropriate per il processo?
- Le soglie di scalabilità sono impostate in modo appropriato?
- Sono in corso attacchi dannosi?
- La configurazione dell'archiviazione della macchina virtuale è corretta?
Per prima cosa, verificare che le dimensioni della macchina virtuale siano appropriate per il processo. Abilitare quindi Diagnostica di Azure nella macchina virtuale per ottenere dati più granulari per metriche specifiche, quali utilizzo della CPU e della memoria. Per abilitare la diagnostica della macchina virtuale tramite il portale, passare alla macchina virtuale, selezionare Impostazioni di diagnostica e quindi attivare la diagnostica.
Si supponga di avere una macchina virtuale correttamente in esecuzione. Tuttavia, di recente le prestazioni della macchina virtuale sono diminuite. Per identificare eventuali colli di bottiglia delle risorse, è necessario esaminare i dati acquisiti.
Iniziare con un intervallo di tempo di dati acquisiti prima, durante e dopo il problema segnalato per ottenere una visualizzazione accurata delle prestazioni. Questi grafici possono essere utili anche per confrontare comportamenti diversi delle risorse nello stesso periodo. Si verificherà la presenza di:
- Colli di bottiglia della CPU
- Colli di bottiglia della memoria
- Colli di bottiglia del disco
Colli di bottiglia della CPU
Quando si analizzano i problemi di prestazioni, è consigliabile esaminare le tendenze e comprendere se hanno effetto sul server. Per individuare le tendenze, usare i grafici di monitoraggio dal portale. Nel grafico di monitoraggio possono comparire diversi tipi di modelli:
- Picchi isolati. Un picco può essere correlato a un'attività pianificata o a un evento previsto. Se si sa di quale attività si tratta, viene eseguita al livello di prestazioni richiesto? Se le prestazioni sono soddisfacenti, potrebbe non essere necessario aumentare la capacità.
- Aumento e consumo costante. La causa di questa tendenza potrebbe essere un nuovo carico di lavoro. Abilitare il monitoraggio nella macchina virtuale per individuare i processi che comportano il carico. L'aumento del consumo può essere dovuto a un codice inefficiente o si potrebbe trattare del normale consumo del nuovo carico di lavoro. Se il consumo è normale, il processo funziona al livello di prestazioni richiesto?
- Costanti. La macchina virtuale è sempre stata così? In tal caso, è necessario identificare i processi che utilizzano la maggior parte delle risorse e prendere in considerazione l'aggiunta di capacità.
- Aumento costante. Viene riscontrato un aumento costante del consumo? In tal caso, questa tendenza potrebbe indicare un codice inefficiente o un processo che richiede un maggior carico di lavoro dell'utente.
Se si osserva un utilizzo elevato della CPU, è possibile effettuare una delle operazioni seguenti:
- Aumentare le dimensioni della macchina virtuale per la scalabilità con più core.
- Esaminare ulteriormente il problema. Individuare l'app e il processo e risolvere il problema di conseguenza.
Se si ridimensiona la macchina virtuale e la CPU è ancora in esecuzione oltre il 95%, le prestazioni delle app sono migliori o la velocità effettiva delle app è superiore a un livello accettabile? In caso contrario, risolvere i problemi della singola app.
Colli di bottiglia della memoria
È possibile visualizzare la quantità di memoria utilizzata dalla macchina virtuale. I log consentono di comprendere la tendenza e se corrisponde al momento in cui si sono verificati i problemi. Non devono essere presenti meno di 100 MB di memoria disponibile in qualsiasi momento. Osservare le tendenze seguenti:
- Aumento e consumo costante. L'utilizzo intensivo della memoria non è necessariamente la causa di prestazioni negative. In alcune app, ad esempio i motori di database relazionali, l'utilizzo elevato della memoria è previsto dalla progettazione. Tuttavia, se sono presenti più app che consumano la memoria, è possibile che si verifichi un peggioramento delle prestazioni perché la contesa della memoria comporta il trimming e il paging su disco. Questi processi avranno un impatto negativo sulle prestazioni.
- Consumo in aumento costante. Questa tendenza potrebbe coincidere con il riscaldamento dell'app. È comune all'avvio dei motori di database. Tuttavia, potrebbe anche essere un'indicazione di una perdita di memoria in un'app.
- Utilizzo di un file di paging o di scambio. Controllare se si sta facendo un uso intensivo del file di paging di Windows o del file di scambio Linux, disponibili in /dev/sdb.
Per risolvere il problema di utilizzo intensivo della memoria, prendere in considerazione le soluzioni seguenti:
- Per un risultato immediato o per l'utilizzo del file di paging, aumentare le dimensioni della macchina virtuale per aggiungere memoria, quindi eseguire il monitoraggio.
- Esaminare ulteriormente il problema. Individuare l'app o il processo che causa il collo di bottiglia e risolverlo. Se si conosce l'app, prendere in considerazione la possibilità di limitare l'allocazione della memoria.
Colli di bottiglia del disco
Le prestazioni di rete possono anche essere correlate al sottosistema di archiviazione della macchina virtuale. È possibile esaminare l'account di archiviazione per la macchina virtuale nel portale. Per identificare i problemi relativi all'archiviazione, esaminare le metriche delle prestazioni dalla diagnostica dell'account di archiviazione e dalla diagnostica della macchina virtuale. Cercare le tendenze principali quando i problemi si verificano in un particolare intervallo di tempo.
- Per verificare il timeout di Archiviazione di Azure, usare le metriche ClientTimeOutError, ServerTimeOutError, AverageE2ELatency, AverageServerLatency e TotalRequests. Se vengono visualizzati i valori nelle metriche TimeOutError , un'operazione di I/O ha richiesto troppo tempo e si è verificato un timeout. Se viene visualizzato un aumento averageServerLatency contemporaneamente a TimeOutErrors, potrebbe trattarsi di un problema di piattaforma. Contattare il supporto tecnico Microsoft.
- Per verificare l'eventuale limitazione di Archiviazione di Azure, usare la metrica ThrottlingError dell'account di archiviazione. Se viene visualizzata la limitazione, significa che si sta raggiungendo il limite per operazioni di I/O al secondo per l'account. È possibile verificare questo problema esaminando la metrica TotalRequests.
Per correggere i problemi di latenza e utilizzo elevato del disco:
- Ottimizzare l'I/O della macchina virtuale per ridimensionare i limiti del disco rigido virtuale.
- Aumentare la velocità effettiva e ridurre la latenza. Se si riscontra di disporre di un'app sensibile alla latenza e si richiede una velocità effettiva elevata, eseguire la migrazione dei dischi rigidi virtuali ad Archiviazione Premium di Azure.
Regole del firewall per le macchine virtuali che bloccano il traffico
Per risolvere un problema relativo al flusso del gruppo di sicurezza di rete, usare lo strumento Verifica flusso IP di Network Watcher e la registrazione del flusso del gruppo di sicurezza di rete per determinare se un gruppo di sicurezza di rete o una route definita dall'utente stia interferendo con il flusso del traffico.
Eseguire Verifica flusso IP e specificare la macchina virtuale locale e quella remota. Quando si fa clic su Controlla, Azure esegue un test logico sulle regole applicate. Se il risultato è che l'accesso è consentito, usare i log del flusso del gruppo di sicurezza di rete.
Nel portale passare ai gruppi di sicurezza di rete. Nelle impostazioni dei log dei flussi selezionare Sì. Provare ora a connettersi nuovamente alla macchina virtuale. Usare Analisi del traffico di Network Watcher per visualizzare i dati. Se il risultato è che l'accesso è consentito, non esiste alcuna regola del gruppo di sicurezza di rete che interferisce.
Se si è arrivati a questo punto e il problema non è stato ancora diagnosticato, potrebbe essersi verificato un errore nella macchina virtuale remota. Disabilitare il firewall nella macchina virtuale remota e ripetere il test della connettività. Se è possibile connettersi alla macchina virtuale remota con il firewall disabilitato, verificare le impostazioni del firewall remoto. Riabilitare quindi il firewall.
Impossibilità di comunicare tra le subnet front-end e back-end
Per impostazione predefinita, tutte le subnet possono comunicare in Azure. Se due macchine virtuali in due subnet non riescono a comunicare, deve essere presente una configurazione che blocca la comunicazione. Prima di controllare i log dei flussi, eseguire lo strumento Verifica flusso IP dalla macchina virtuale front-end alla macchina virtuale back-end. Questo strumento esegue un test logico sulle regole applicate alla rete.
Se il risultato è che un gruppo di sicurezza di rete nella subnet back-end sta bloccando tutte le comunicazioni, riconfigurare tale gruppo. Per motivi di sicurezza, è necessario bloccare alcune comunicazioni con il front-end perché è esposto alla rete Internet pubblica.
Bloccando la comunicazione con il back-end, si limita la quantità di esposizione in caso di malware o di un attacco alla sicurezza. Tuttavia, se il gruppo di sicurezza di rete blocca tutto, significa che non è configurato correttamente. Abilitare le porte e i protocolli specifici richiesti.