Introduzione
Il clustering è il processo di raggruppamento di oggetti con oggetti simili. Nell'immagine seguente, ad esempio, è presente una raccolta di coordinate 2D raggruppate in tre categorie: in alto a sinistra (giallo), in basso (rosso) e in alto a destra (blu).
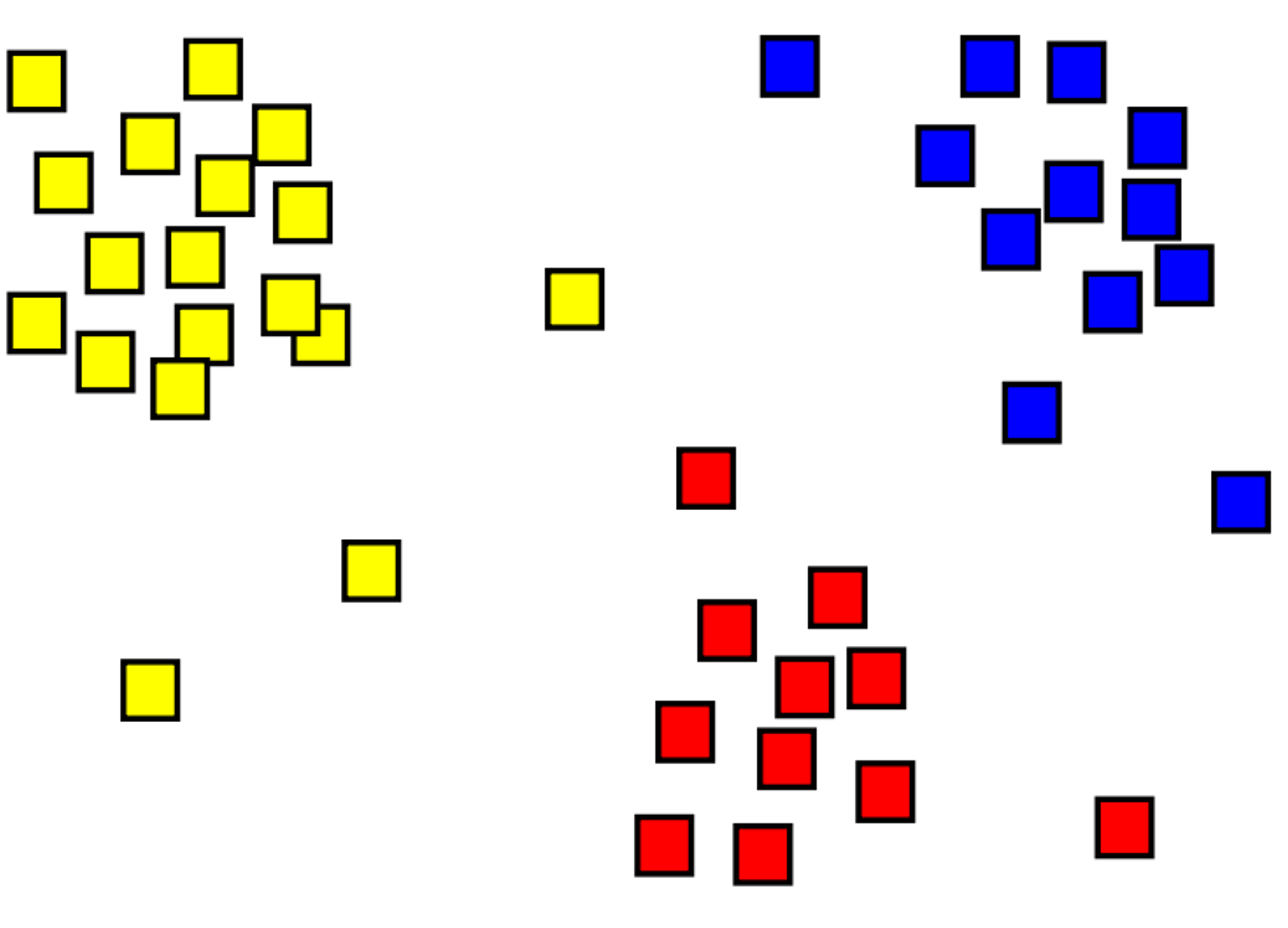
Il clustering si differenzia dai modelli di classificazione per essere un metodo senza supervisione, in cui il training viene eseguito senza l'uso di etichette. I modelli di clustering, invece, identificano gli esempi con insiemi simili di funzionalità. Nell'immagine precedente, sono raggruppati gli esempi che si trovano in una posizione simile.
Il clustering è utile e ampiamente usato per esplorare nuovi gruppi di dati in cui non sono ancora stati definiti modelli tra i punti dati, ad esempio le categorie generiche. Viene applicato in molti campi in cui è necessario etichettare automaticamente dati complessi, ad esempio analisi dei social network, connettività cerebrale, filtro della posta indesiderata e così via.