Esercizio: Eseguire il training del servizio Visione personalizzata
A questo punto è possibile caricare le immagini ed eseguire il training del servizio Visione personalizzata.
Assicurarsi di avere circa 30 immagini dell'oggetto che si vuole usare per il training, che sia stato eseguito l'accesso al portale di Visione personalizzata e che ci si trovi nella pagina del progetto.
Caricare le immagini
Per Bungee, si inizierà caricando 15 immagini e si vedrà in che modo è possibile eseguire il training del servizio di intelligenza artificiale Visione personalizzata. Le immagini da cui iniziare mostreranno solo Bungee, ma da diverse angolazioni e con tipi di illuminazione differenti.
Per iniziare a eseguire il training dell'intelligenza artificiale, seguire questa procedura:
- Selezionare Aggiungi immagini.
- Selezionare le immagini da usare per il training dell'intelligenza artificiale.
- Selezionare Carica X file, dove X è il numero di immagini selezionate.
- Attendere il caricamento delle immagini.
- Selezionare Fine.
Si dovrebbero vedere tutte le immagini aggiunte al portale di Visione personalizzata.
Contrassegnare le immagini
A questo punto è necessario aggiungere un tag alle immagini. Selezionare un'immagine: si espanderà una finestra con l'immagine al suo interno. Selezionare l'immagine per vedere una casella intorno all'oggetto. È possibile osservare il servizio di intelligenza artificiale già al lavoro per identificare le linee e le forme di cui si è parlato in un'unità precedente. Regolare la casella in modo che si adatti esattamente all'oggetto. Una parte del successo del servizio di intelligenza artificiale è determinata da quanta parte della casella viene identificata come oggetto, quindi prendere in considerazione i tratti più evidenti dell'oggetto. Ad esempio, non allargare eccessivamente la casella perché è rimasta fuori un po' di pelliccia.
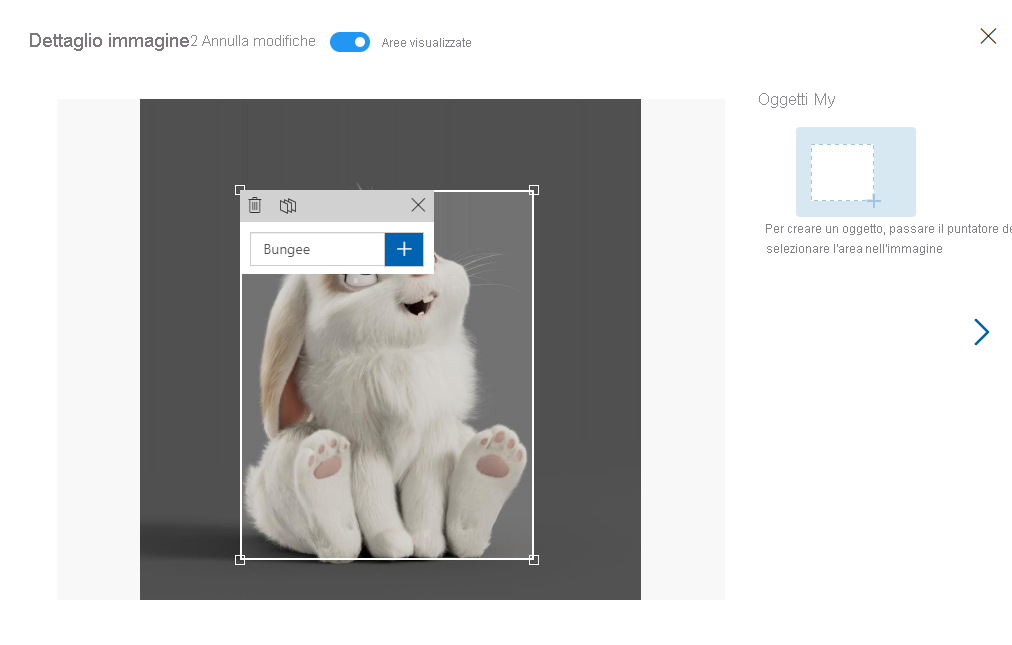
Aggiungere il tag per l'oggetto, selezionare l'icona + e quindi passare all'immagine successiva. Aggiungere un tag a ognuna delle immagini caricate.
Nota
È possibile contrassegnare più oggetti in un'immagine. Se si vogliono contrassegnare più oggetti, è possibile eseguire questa operazione in un unico passaggio.
Dopo aver completato l'assegnazione dei tag per tutte le immagini, dovrebbero comparire tutte nell'area Con tag del progetto.

Eseguire il training sulle immagini con tag
Quando si ritiene di avere contrassegnato un numero sufficiente di immagini, selezionare Esegui il training nella parte in alto a destra del portale. Scegliere Quick Training (Training rapido) come tipo di training per questa prima iterazione. Sarà possibile provare l'opzione Advanced Training (Training avanzato) in un secondo momento.
Si dovrebbe vedere la prima iterazione del training. Anche in questo caso saranno disponibili due dispositivi di scorrimento che consentono di avere un maggiore controllo sul training e le stime dell'intelligenza artificiale.
Soglia di probabilità
Ogni volta che il servizio di intelligenza artificiale esegue una stima, fornisce anche una percentuale di probabilità. Ad esempio, dirà: "Sono 80% sicuro che questo è Bungee". La soglia di probabilità è la soglia in cui l'attendibilità deve essere quando si esegue il training per determinare se è stata stimata in modo accurato. Ad esempio, se la soglia di probabilità è del 50% e il servizio di intelligenza artificiale ha indicato che l'immagine ritrae Bungee con un livello di confidenza del 45% e si tratta effettivamente di Bungee, questa non sarebbe considerata una stima accurata.
Soglia di sovrapposizione
Come probabilmente si è notato durante l'assegnazione dei tag alle immagini, il servizio di intelligenza artificiale non solo fornirà una percentuale di attendibilità che l'oggetto si trovi nell'immagine, ma anche un rettangolo delimitatore in cui ritiene che si trovi l'oggetto all'interno della foto. Se questa soglia è del 30%, ad esempio, almeno il 30% del rettangolo delimitatore che il servizio di intelligenza artificiale prevede che contenga l'oggetto deve trovarsi all'interno del rettangolo delimitatore corretto creato quando sono state contrassegnate le immagini.