Informazioni sui processi del flusso di lavoro
I flussi di lavoro ti consentono di automatizzare i passaggi nel tuo processo di implementazione. Il processo può includere diversi gruppi logici di processi che si desidera eseguire. In questa unità verranno fornite informazioni sui processi del flusso di lavoro e su come usarli per aggiungere processi di controllo di qualità alle distribuzioni Bicep.
Quali sono i processi del flusso di lavoro?
I processi consentono di dividere il flusso di lavoro in più blocchi logici. Ogni processo può contenere uno o più passaggi.
I processi possono essere usati nel flusso di lavoro per contrassegnare una separazione delle problematiche. Ad esempio, quando si usa il codice Bicep, la convalida del codice è un problema separato dalla distribuzione del file Bicep. Quando si usa un flusso di lavoro automatizzato, la compilazione e il test del codice sono spesso denominati integrazione continua (CI). La distribuzione di codice in un flusso di lavoro automatizzato viene spesso chiamata distribuzione continua (CD).
Nei processi di integrazione continua (CI) si verifica la validità delle modifiche apportate al codice. I processi di integrazione continua forniscono il controllo di qualità. Possono essere eseguite senza influire sull'ambiente di produzione live.
In molti linguaggi di programmazione il codice deve essere compilato prima di poter essere eseguito. Quando un file Bicep viene implementato, viene convertito o transcompilato da Bicep a JSON. Gli strumenti eseguono automaticamente questo processo. Nella maggior parte delle situazioni, non è necessario compilare manualmente codice Bicep nei modelli JSON all'interno del flusso di lavoro. Si usa comunque il termine integrazione continua quando si tratta di codice Bicep, perché le altre parti dell'integrazione continua restano valide, ad esempio la convalida del codice.
La corretta esecuzione dei processi di integrazione continua contribuisce ad aumentare la fiducia sul fatto che anche l’implementazione delle modifiche apportate avrà esito positivo. Nei processi di distribuzione continua si distribuisce il codice in ognuno degli ambienti. In genere si inizia con l'ambiente di test e altri ambienti non di produzione e quindi si passa agli ambienti di produzione. In questo modulo si procederà alla distribuzione in un singolo ambiente. In un modulo futuro si apprenderà come estendere il flusso di lavoro di distribuzione per la distribuzione in più ambienti, ad esempio ambienti non di produzione e produzione.
I processi vengono eseguiti in parallelo per impostazione predefinita. È possibile controllare come e quando ogni processo viene eseguito. Ad esempio, è possibile configurare i processi di distribuzione continua da eseguire solo dopo l'esecuzione dei processi di integrazione continua. In alternativa, potrebbero essere presenti più processi di integrazione continua che devono essere eseguiti in sequenza, ad esempio per compilare il codice e quindi testarlo. È anche possibile includere un processo di rollback che viene eseguito solo se i processi di distribuzione precedenti non sono riusciti.
Test Shift-left
Usando i processi, è possibile verificare la qualità del codice prima di distribuirlo. Questo approccio viene talvolta denominato test Shift-left.
Si consideri una sequenza temporale delle attività eseguite durante la scrittura del codice. La sequenza temporale inizia dalle fasi di pianificazione e progettazione. Passa quindi alle fasi di compilazione e test. Infine, si procede alla distribuzione e occorre supportare la soluzione.
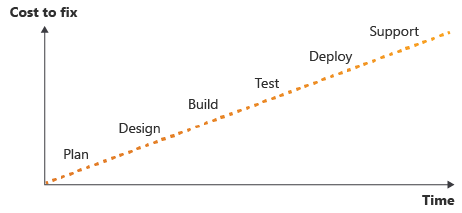
Secondo una regola ben nota nello sviluppo di software, quando si individua un errore nelle fasi iniziali di un processo (più a sinistra nella sequenza temporale), più facile, veloce ed economico sarà correggerlo. Quando si individua un errore in una fase successiva o più avanzata, la correzione sarà più difficile e complessa.
L'obiettivo è quindi spostare l'individuazione dei problemi verso sinistra nel diagramma precedente. In questo modulo verrà illustrato come aggiungere più convalide e test al flusso di lavoro man mano che avanza.
È anche possibile aggiungere la convalida prima dell'inizio della distribuzione. Quando si utilizzano strumenti come GitHub, le richieste pull rappresentano in genere modifiche che un utente del team vuole apportare al codice nel ramo principale. È utile creare un altro flusso di lavoro che esegue automaticamente i passaggi di integrazione continua durante il processo di revisione per la richiesta pull. Questa tecnica consente di verificare che il codice funzioni ancora, anche con le modifiche proposte. Se la convalida ha esito positivo, si è certi che la modifica non causerà problemi quando viene unita al ramo principale. Se il controllo ha esito negativo, è necessario eseguire altre operazioni prima che la richiesta pull sia pronta per l'unione. In un modulo futuro verrà anche illustrata la configurazione di un processo di rilascio appropriato usando le richieste pull e le strategie di diramazione.
Importante
La convalida e i test automatizzati sono efficaci quanto i test che si scrivono. È importante considerare gli aspetti da testare e i passaggi da eseguire per assicurarsi che la distribuzione venga eseguita correttamente.
Definire un processo del flusso di lavoro
Ogni flusso di lavoro contiene almeno un processo e è possibile definire il numero necessario di processi aggiuntivi in base ai requisiti. I processi vengono eseguiti in parallelo per impostazione predefinita. Il tipo di account GitHub in uso determina il numero di processi che è possibile eseguire contemporaneamente quando si usano gli strumenti di esecuzione ospitati in GitHub.
Supponiamo di aver creato un file Bicep che occorre implementare due volte: una volta nell'infrastruttura negli Stati Uniti e una volta nell'infrastruttura in Europa. Si vuole anche convalidare il codice Bicep nel flusso di lavoro. Ecco un'illustrazione di un flusso di lavoro con più processi che definisce un processo simile:
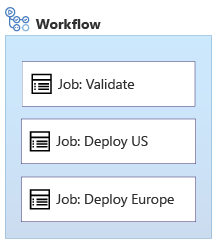
Si noti che in questo esempio sono presenti tre processi. Il processo Validate è simile a un processo di integrazione continua. Vengono quindi eseguiti i processi Deploy US e Deploy Europe. Ogni fase distribuisce il codice in uno degli ambienti. Per impostazione predefinita, i processi vengono eseguiti in parallelo.
Ecco come vengono definiti i processi in un file YAML del flusso di lavoro:
name: learn-github-actions
on: [push]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- run: echo "Here is where you'd perform the validation steps."
deployUS:
runs-on: windows-latest
steps:
- run: echo "Here is where you'd perform the steps to deploy to the US region."
deployEurope:
runs-on: ubuntu-latest
steps:
- run: echo "Here is where you'd perform the steps to deploy to the European region."
Controllare la sequenza dei processi
È possibile aggiungere dipendenze tra i processi per modificare l'ordine. Continuando con l'esempio precedente, probabilmente si vuole convalidare il codice prima di eseguire i processi di distribuzione, come illustrato di seguito:
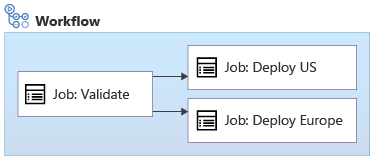
È possibile specificare le dipendenze tra processi usando la parola chiave needs:
name: learn-github-actions
on: [push]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- run: echo "Here is where you'd perform the validation steps."
deployUS:
runs-on: windows-latest
needs: validate
steps:
- run: echo "Here is where you'd perform the steps to deploy to the US region."
deployEurope:
runs-on: ubuntu-latest
needs: validate
steps:
- run: echo "Here is where you'd perform the steps to deploy to the European region."
Quando si usa la parola chiave needs, il flusso di lavoro attende che il processo dipendente venga completato correttamente prima di avviare il processo successivo. Se il flusso di lavoro rileva che tutte le dipendenze per più processi sono state soddisfatte, è possibile eseguire tali processi in parallelo.
Nota
In realtà, i processi vengono eseguiti in parallelo solo se sono disponibili strumenti di esecuzione sufficienti per eseguire più processi contemporaneamente. Il numero di strumenti di esecuzione ospitati in GitHub che è possibile usare dipende dal tipo di account GitHub in uso. È possibile acquistare un altro piano dell'account GitHub se sono necessari più processi paralleli.
In alcuni casi, si vuole eseguire un processo quando un processo precedente ha esito negativo. Ad esempio, ecco un flusso di lavoro diverso. Se la distribuzione ha esito negativo, un processo denominato rollback viene eseguito immediatamente dopo:
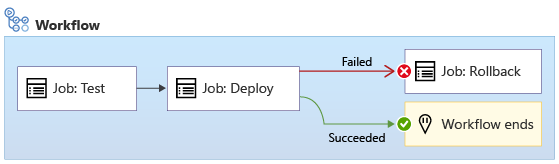
Usare la parola chiave if per specificare una condizione che deve essere soddisfatta prima dell'esecuzione di un processo:
name: learn-github-actions
on: [push]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- run: echo "Here is where you'd perform the validation steps."
deploy:
runs-on: windows-latest
needs: validate
steps:
- run: echo "Here is where you'd perform the steps to deploy."
rollback:
runs-on: ubuntu-latest
needs: deploy
if: ${{ failure() }}
steps:
- run: echo "Here is where you'd perform the steps to roll back a failure."
Nell'esempio precedente, quando tutto funziona correttamente, il flusso di lavoro esegue prima il processo Test e quindi esegue il processo Deploy. Ignora il processo Rollback. Tuttavia, se il processo Test o Deploy ha esito negativo, il flusso di lavoro esegue il processo Rollback. Altre informazioni sul rollback verranno fornite più avanti in questo modulo.
Processi di distribuzione Bicep
Un flusso di lavoro di distribuzione Bicep tipico contiene diversi processi. Man mano che il flusso di lavoro avanza tra i processi, l'obiettivo è diventare sempre più sicuri che i processi successivi avranno esito positivo. Ecco i processi comuni per un flusso di lavoro di distribuzione Bicep:

- Lint: usare il linter di Bicep per verificare che il file Bicep sia formattato correttamente e non contenga errori evidenti.
- Convalida: usare il processo di convalida preliminare di Azure Resource Manager per verificare la presenza di problemi che possono verificarsi durante la distribuzione.
- Anteprima: Usare il comando di simulazione per convalidare l'elenco delle modifiche che verranno applicate all'ambiente Azure. Chiedere a un utente di esaminare manualmente i risultati delle operazioni di simulazione e approvare il flusso di lavoro per procedere.
- Distribuzione: inviare la distribuzione a Resource Manager e attendere il completamento.
- Smoke test: Eseguire controlli di base post-implementazione su alcune delle risorse importanti che hai implementato. Questi controlli sono denominati smoke test dell'infrastruttura.
L'organizzazione potrebbe aver definito una sequenza di processi diversa oppure potrebbe essere necessario integrare le distribuzioni Bicep in un flusso di lavoro che distribuisce altri componenti. Dopo aver compreso il funzionamento dei processi, è possibile progettare un flusso di lavoro in base alle proprie esigenze.
Ogni processo viene eseguito in una nuova istanza dello strumento di esecuzione che inizia da un ambiente pulito. Quindi, in ogni processo è in genere necessario controllare il codice sorgente come primo passaggio. È anche necessario accedere all'ambiente Azure in ogni processo che interagisce con Azure.
In questo modulo verranno fornite altre informazioni su questi processi e si creerà progressivamente un flusso di lavoro che include ogni processo. Verrà anche illustrato:
- Come i flussi di lavoro arrestano il processo di distribuzione se si verifica un evento imprevisto in uno dei processi precedenti.
- Come configurare la sospensione del flusso di lavoro fino a quando non si verifica manualmente che cosa è accaduto in un processo precedente.