Indicizzare i dati usando l'API push di Azure AI Search
L'API REST è il modo più flessibile per eseguire il push dei dati in un indice di Azure AI Search. È possibile usare qualsiasi linguaggio di programmazione o eseguire l'operazione in modo interattivo con qualsiasi app in grado di inviare richieste JSON a un endpoint.
In questa unità si vedrà come usare l'API REST in modo efficace e si esamineranno le operazioni disponibili. Si analizzerà quindi il codice .NET Core e si vedrà come ottimizzare l'aggiunta di grandi quantità di dati tramite l'API.
Operazioni dell'API REST supportate
AI Search supporta due API REST. API di ricerca e di gestione. Questo modulo è incentrato sulle API REST di ricerca che forniscono operazioni per cinque funzionalità di ricerca:
| Funzionalità | Operazioni |
|---|---|
| Indice | Creazione, eliminazione, aggiornamento e configurazione. |
| Document | Recupero, aggiunta, aggiornamento ed eliminazione. |
| Indicizzatore | Configurazione delle origini dati e pianificazione in origini dati limitate. |
| Set di competenze | Recupero, creazione, eliminazione, elenco e aggiornamento. |
| Mappa di sinonimi | Recupero, creazione, eliminazione, elenco e aggiornamento. |
Come chiamare l'API REST di ricerca
Per chiamare una delle API di ricerca è necessario quanto segue:
- Usare l'endpoint HTTPS (sulla porta predefinita 443) fornito dal servizio di ricerca e includere api-version nell'URI.
- L'intestazione della richiesta deve includere un attributo api-key.
Per trovare i valori di endpoint, api-version e api-key, passare al portale di Azure.

Nel portale passare al servizio di ricerca e quindi selezionare Esplora ricerche. L'endpoint API REST si trova nel campo URL della richiesta. La prima parte dell'URL è l'endpoint (ad esempio https://azsearchtest.search.windows.net) e la stringa di query mostra api-version (ad esempio api-version=2023-07-01-Preview).

Per trovare l'elemento api-key a sinistra, selezionare Chiavi. È possibile usare la chiave amministratore primaria o secondaria se si usa l'API REST per eseguire operazioni che vanno oltre l'esecuzione di query sull'indice. Se è necessario solamente eseguire la ricerca in un indice, è possibile creare e usare chiavi di query.
Per aggiungere, aggiornare o eliminare dati in un indice, è necessario usare una chiave amministratore.
Aggiungere dati a un indice
Usare una richiesta HTTP POST usando la funzionalità di indici in questo formato:
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
Il corpo della richiesta deve indicare all'endpoint REST l'azione da eseguire sul documento, il documento a cui applicare l'azione e i dati da usare.
Il codice JSON deve avere il formato seguente:
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Azione | Descrizione |
|---|---|
| upload | Crea o sostituisce il documento in SQL, analogamente a un'operazione upsert. |
| merge | Aggiorna un documento esistente con i campi specificati. L'unione non riesce se non è possibile trovare alcun documento. |
| mergeOrUpload | Aggiorna un documento esistente con i campi specificati e carica il documento, se non esiste. |
| delete | Elimina l'intero documento, è sufficiente specificare il valore di key_field_name. |
Se la richiesta ha esito positivo, l'API restituirà un codice di stato 200.
Nota
Per un elenco completo di tutti i codici di risposta e i messaggi di errore, vedere Aggiungere, aggiornare o eliminare documenti (API REST di Azure AI Search)
Questo codice JSON di esempio carica il record del cliente nell'unità precedente:
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
È possibile aggiungere tutti i documenti desiderati nella matrice di valori. Per ottenere prestazioni ottimali, è tuttavia consigliabile raggruppare i documenti in batch nelle richieste fino a un massimo di 1.000 documenti o 16 MB di dimensioni totali.
Usare .NET Core per indicizzare i dati
Per ottenere prestazioni ottimali, usare la libreria client Azure.Search.Document più recente, attualmente la versione 11. È possibile installare la libreria client con NuGet:
dotnet add package Azure.Search.Documents --version 11.4.0
Le prestazioni dell'indice dipendono da sei fattori chiave:
- Livello di servizio di ricerca e numero di repliche e partizioni abilitate.
- Complessità dello schema dell'indice. Ridurre il numero di proprietà (ricercabili, con facet, ordinabili) di ogni campo.
- Numero di documenti in ogni batch: le dimensioni ottimali dipendono dallo schema dell'indice e dalle dimensioni dei documenti.
- Tipo di approccio multithreading.
- Gestione degli errori e delle limitazioni. Usare una strategia di retry con backoff esponenziale.
- Posizione in cui si trovano i dati: provare a indicizzare i dati il più vicino possibile all'indice di ricerca. Eseguire ad esempio caricamenti dall'ambiente Azure.
Determinare le dimensioni ottimali del batch
Poiché la determinazione delle dimensioni ottimali del batch è un fattore chiave per migliorare le prestazioni, si esaminerà ora un approccio nel codice.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
L'approccio consiste nell'aumentare le dimensioni del batch e monitorare il tempo necessario per ricevere una risposta valida. Il codice esegue un ciclo da 100 a 1000, con incrementi di 100 documenti. Per ogni dimensione del batch, restituisce le dimensioni del documento, il tempo necessario per ottenere una risposta e il tempo medio per MB. L'esecuzione di questo codice restituisce risultati simili ai seguenti:
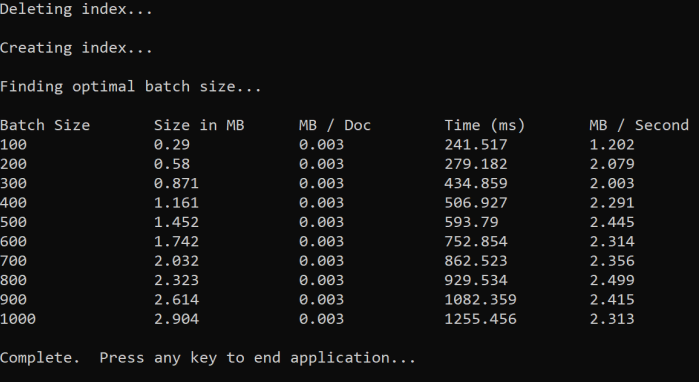
Nell'esempio precedente le dimensioni ottimali del batch per la velocità effettiva sono di 2,499 MB al secondo, 800 documenti per batch.
Implementare una strategia di ripetizione dei tentativi con backoff esponenziale
Se l'indice inizia a limitare le richieste a causa di overload, risponde con uno stato 503 (richiesta rifiutata a causa di un carico elevato) o 207 (errore di alcuni documenti nel batch). È necessario gestire queste risposte e una buona strategia è il backoff. Backoff significa sospendere l'operazione per un certo intervallo di tempo prima di provare a eseguire di nuovo la richiesta. Se si aumenta questo intervallo di tempo per ogni errore, si esegue il backoff esponenziale.
Esaminare questo codice:
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Il codice tiene traccia dei documenti per i quali si è verificato un errore in un batch. Se si verifica un errore, avviene un'attesa per un determinato intervallo e questo ritardo viene quindi raddoppiato per l'errore successivo.
Infine, è previsto un numero massimo di tentativi e, se questo numero massimo viene raggiunto, il programma viene terminato.
Usare il threading per migliorare le prestazioni
È possibile completare l'app di caricamento dei documenti combinando la strategia di backoff precedente con un approccio di threading. Ecco un codice di esempio:
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
Questo codice usa chiamate asincrone a una funzione ExponentialBackoffAsync che implementa la strategia di backoff. La funzione si chiama usando thread, ad esempio il numero di core del processore. Una volta raggiunto il numero massimo di thread, il codice attende il completamento dei thread. Crea quindi un nuovo thread finché non vengono caricati tutti i documenti.