Indicizzare i dati da origini dati esterne usando Azure Data Factory
L'aggiunta di dati esterni che non si trovano in Azure è una necessità comune in una soluzione di ricerca di un'organizzazione. Azure AI Search è un servizio flessibile e offre molti modi per creare i dati ed eseguirne il push negli indici.
Eseguire il push dei dati in un indice di ricerca usando Azure Data Factory
Un primo approccio è un'opzione senza uso di codice per il push dei dati in un indice usando Azure Data Factory. Azure Data Factory include connessioni a quasi 100 archivi dati diversi. Sono presenti connettori come HTTP e REST che consentono di connettere un numero illimitato di archivi dati. Questi archivi dati vengono usati come origine o come destinazione (sono detti sink nell'attività di copia) nelle pipeline.
Il connettore dell'indice di Azure AI Search può essere usato come sink in un'attività di copia.
Creare una pipeline di Azure Data Factory per eseguire il push dei dati in un indice di ricerca
Per usare una pipeline di Azure Data Factory per eseguire il push dei dati in un indice di ricerca, seguire questa procedura:
- Creare un indice di Azure AI Search con tutti i campi desiderati per archiviare i dati.
- Creare una pipeline con un passaggio di copia dei dati.
- Creare una connessione all'origine dati in cui si trovano i dati.
- Creare un sink da connettere all'indice di ricerca.
- Eseguire il mapping dei campi dai dati di origine all'indice di ricerca.
- Eseguire la pipeline per eseguire il push dei dati nell'indice.
Si supponga, ad esempio, di avere dati dei clienti in formato JSON ospitati esternamente. Si vogliono copiare i clienti in un indice di ricerca. Il codice JSON è in questo formato:
{
"_id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": 1558
},
"phoneNumbers": [
{
"type": "home",
"number": "+1 (830) 465-2965"
},
{
"type": "home",
"number": "+1 (889) 439-3632"
}
]
}
Creare un indice di ricerca
Creare un servizio di Azure AI Search e un indice in cui archiviare le informazioni. Se è stato completato il modulo Crea una soluzione di Azure AI Search, si è visto come eseguire questa operazione. Seguire i passaggi per creare il servizio di ricerca, ma arrestarsi al punto relativo all'importazione dei dati. Per il push dei dati in un indice non è necessario creare un indicizzatore o un set di competenze.
Creare un indice e aggiungere questi campi e proprietà:

Al momento è necessario creare prima di tutto l'indice, in quanto Azure Data Factory non può creare indici.
Creare una pipeline usando lo strumento Copia dati di Azure Data Factory
Aprire Azure Data Factory Studio e selezionare la sottoscrizione di Azure e il nome della data factory.

Selezionare Inserisci.
Seleziona Avanti.
Nota
È possibile scegliere di pianificare la pipeline se i dati cambiano ed è necessario mantenere l'indice aggiornato. Per questo esempio, si importeranno i dati una sola volta.
Creare il servizio collegato di origine
In Tipo di origine selezionare HTTP.
Accanto a Connessione selezionare + Nuova connessione.
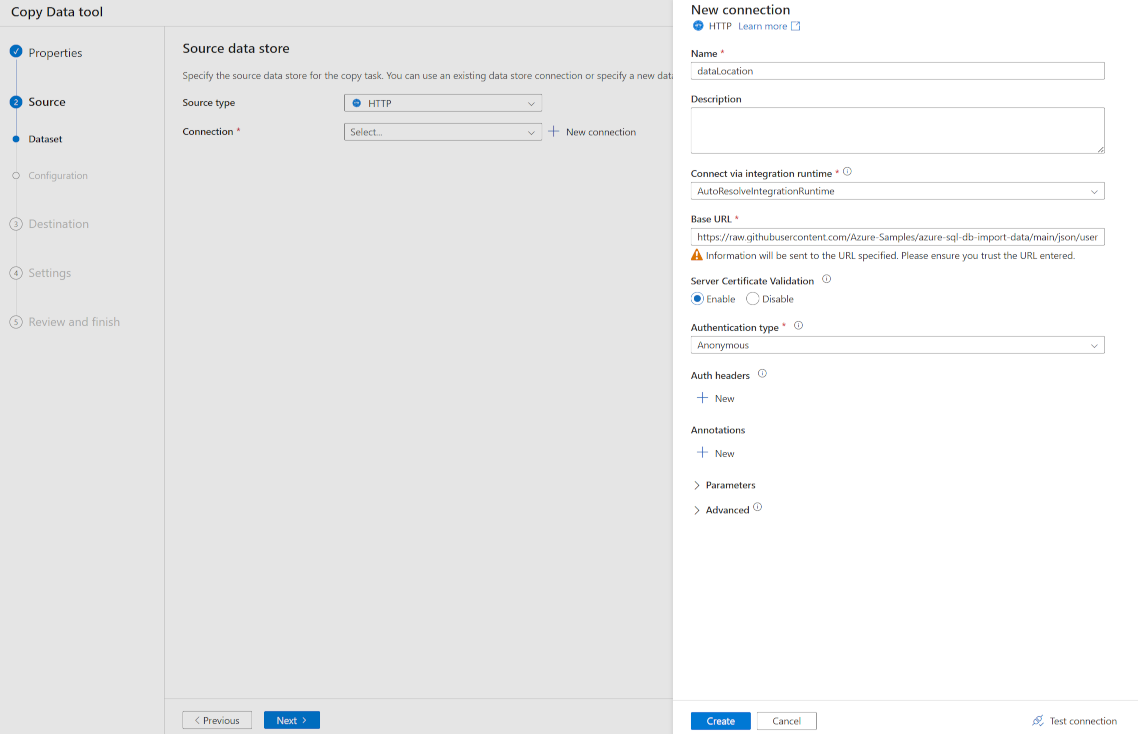
Nel riquadro Nuova connessione, in Nome immettere dataLocation.
In URL di base immettere il percorso del file JSON, in questo esempio https://raw.githubusercontent.com/Azure-Samples/azure-sql-db-import-data/main/json/user1.json.
In Tipo di autenticazione selezionare Anonimo.
Seleziona Crea.
Selezionare Avanti.

In Formato file selezionare JSON.
Selezionare Avanti.


Creare il servizio collegato di destinazione
In Tipo di destinazione selezionare Ricerca di Azure. Selezionare quindi + Nuova connessione.
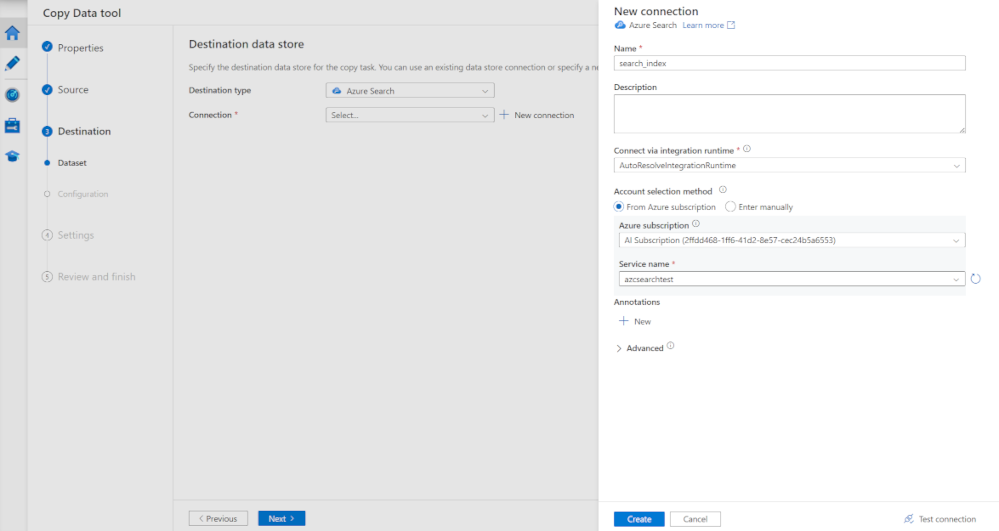
Nel riquadro Nuova connessione, in Nome immettere search_index.
In Sottoscrizione di Azure selezionare la sottoscrizione di Azure.
In Nome servizio selezionare il servizio Azure AI Search.
Seleziona Crea.
Nel riquadro Archivio dati di destinazione, in Destinazione selezionare l'indice di ricerca creato.

Eseguire il mapping dei campi di origine ai campi di destinazione
Selezionare Avanti.
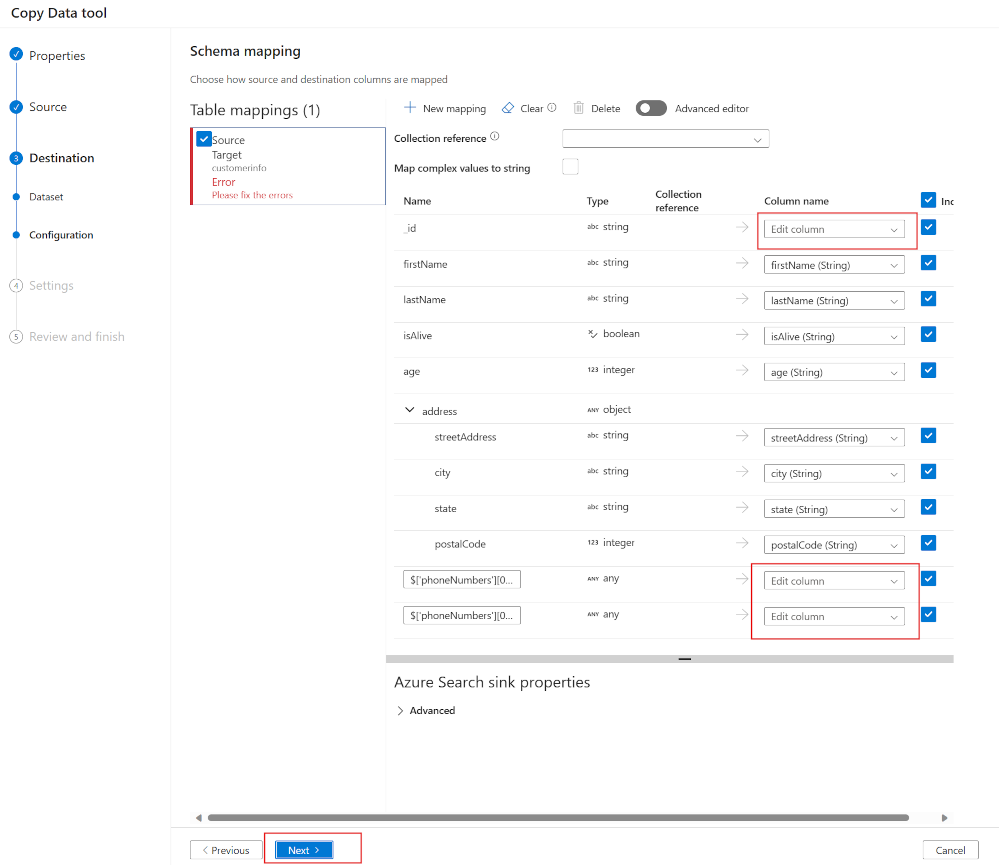
Se è stato creato un indice con nomi dei campi che corrispondono agli attributi JSON, Azure Data Factory eseguirà automaticamente il mapping del codice JSON al campo nell'indice di ricerca.
Nell'esempio precedente è necessario eseguire il mapping di tre campi nel documento JSON ai campi nell'indice.
Eseguire il mapping dei campi e quindi selezionare Avanti.
Nel riquadro Impostazioni, in Nome attività immettere jsonToSearchIndex.
Selezionare Avanti.

Eseguire la pipeline per eseguire il push dei dati nell'indice
Nel riquadro Riepilogo selezionare Avanti.
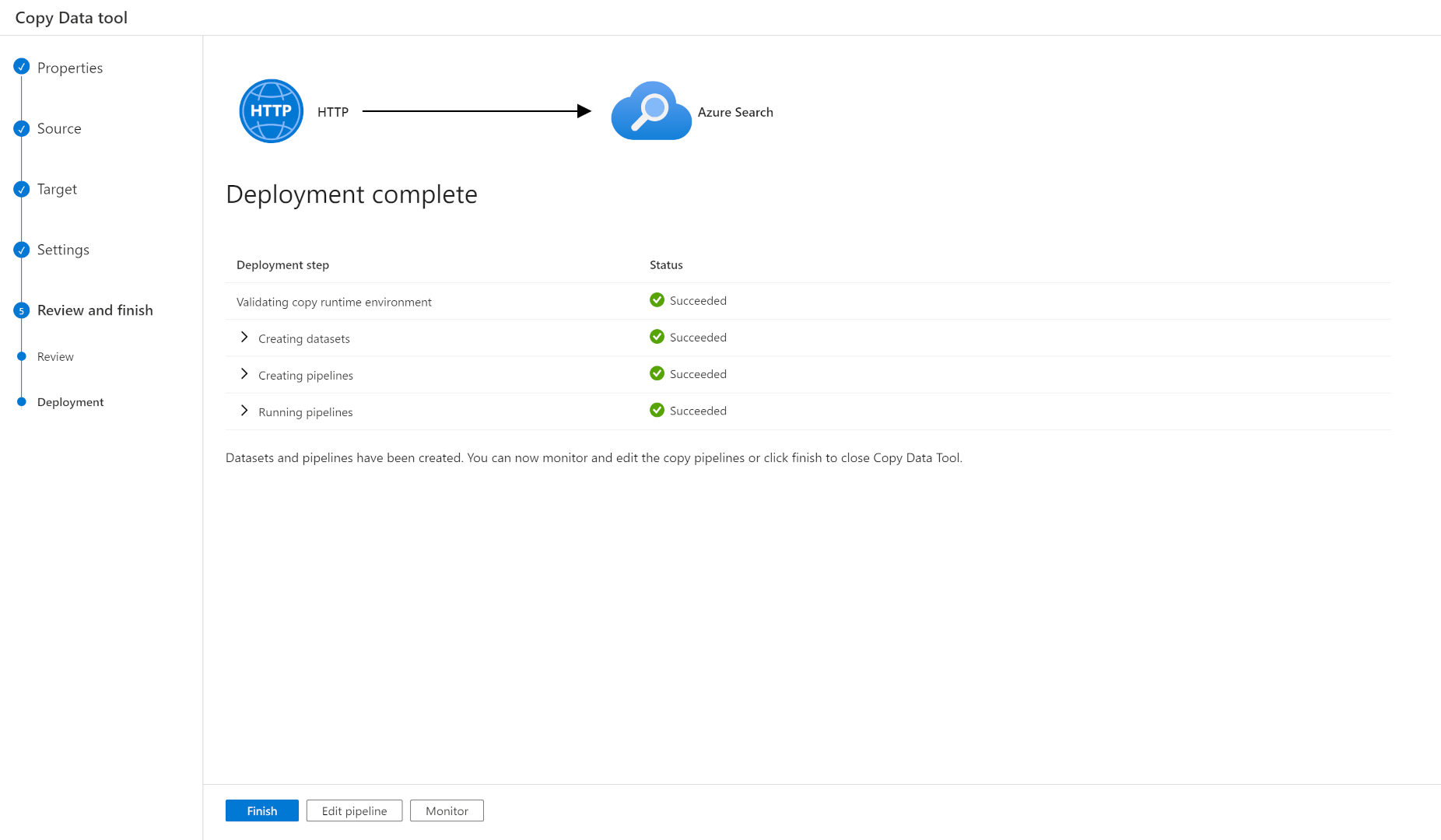
Dopo aver convalidato e distribuito la pipeline, selezionare Fine.

La pipeline è stata distribuita ed eseguita. Il documento JSON è stato aggiunto all'indice di ricerca. È possibile usare il portale di Azure ed eseguire una ricerca in Esplora ricerche. Sarà possibile vedere i dati JSON importati.

Seguendo questi passaggi si è appreso come eseguire il push dei dati in un indice. La pipeline creata per impostazione predefinita unisce gli aggiornamenti nell'indice. Se si modificano i dati JSON e si esegue nuovamente la pipeline, l'indice di ricerca viene aggiornato. È possibile modificare il comportamento di scrittura per eseguire solo il caricamento se si vuole che i dati vengano sostituiti ogni volta che si esegue la pipeline.
Limitazioni dell'uso del servizio Azure AI Search predefinito come servizio collegato
Al momento, il servizio collegato Azure AI Search come sink supporta solo questi campi:
| Tipo di dati di Azure AI Search |
|---|
| String |
| Int32 |
| Int64 |
| Double |
| Boolean |
| DataTimeOffset |
Ciò significa che gli elementi ComplexType e le matrici non sono attualmente supportati. Nel caso del documento JSON precedente, ciò significa che non è possibile eseguire il mapping di tutti i numeri di telefono per il cliente. Viene eseguito il mapping solo del primo numero di telefono.