Eseguire il benchmarking in HBase
Yahoo! Cloud Serving Benchmark (YCSB) è una suite di specifiche e programmi open source per la valutazione delle prestazioni relative dei sistemi di gestione dei database NoSQL. In questo esercizio verrà eseguito il benchmark per le prestazioni di due cluster HBase, uno dei quali sta usando la funzionalità di scrittura accelerata. L'attività consiste nel comprendere le differenze di prestazioni tra le due opzioni. Prerequisiti per l'esercizio
Per eseguire i passaggi dell'esercizio, assicurarsi di avere a disposizione quanto segue:
- Sottoscrizione di Azure con autorizzazione per la creazione di un cluster HDInsight HBase.
- Accesso a un client SSH come Putty (Windows) o Terminal (Mac book)
Eseguire il provisioning del cluster HDInsight HBase con il portale di gestione di Azure
Per eseguire il provisioning di HDInsight HBase con la nuova esperienza nel portale di gestione di Azure, seguire questa procedura.
Vai al portale di Azure. Accedere con le credenziali dell'account Azure.
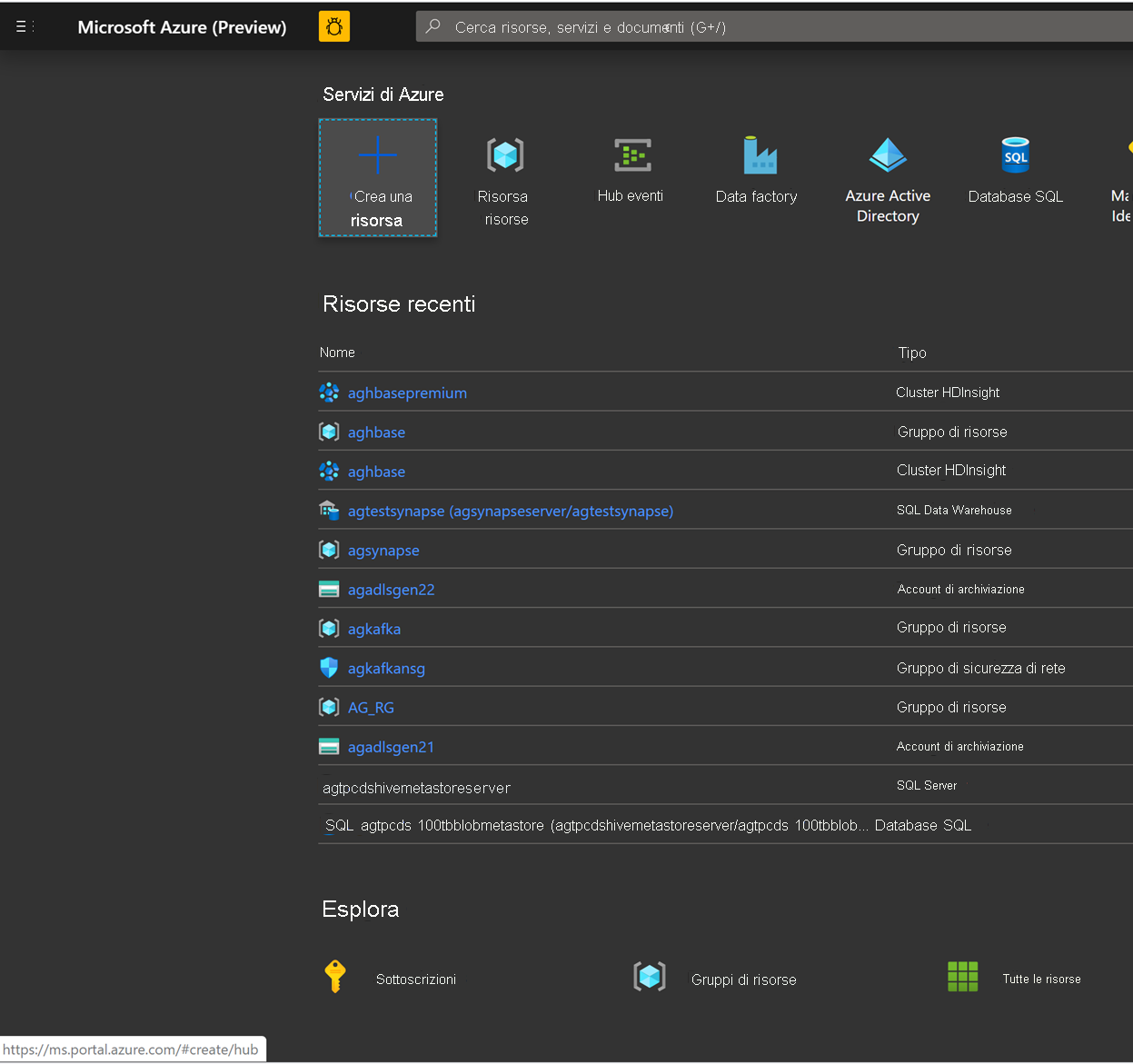
Si inizierà con la creazione di un account di archiviazione BLOB in blocchi Premium. Nella nuova pagina fare clic su Account di archiviazione.
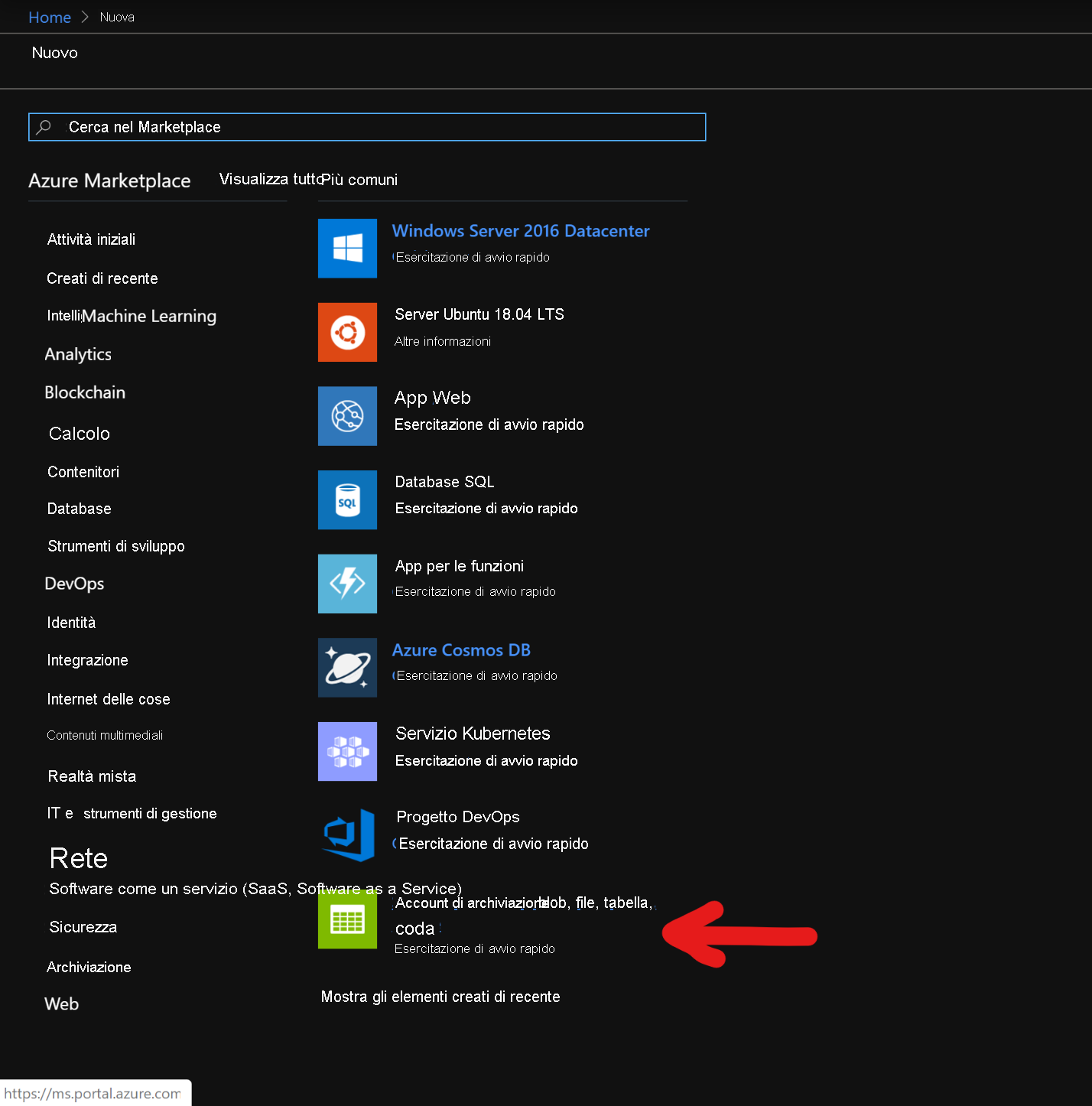
Nella pagina Crea account di archiviazione compilare i campi seguenti
Sottoscrizione: deve essere popolato automaticamente con i dettagli della sottoscrizione
Gruppo di risorse: immettere un gruppo di risorse in cui gestire la distribuzione di HDInsight HBase
Nome account di archiviazione: immettere un nome per l'account di archiviazione da usare nel cluster Premium.
Area: immettere il nome dell'area di distribuzione (assicurarsi che il cluster e l'account di archiviazione siano nella stessa area)
Prestazioni: Premium
Tipo di account: BlockBlobStorage
Replica: archiviazione con ridondanza locale
Nome utente dell'account di accesso del cluster: immettere il nome utente per l'amministratore del cluster (impostazione predefinita: admin)
Lasciare i valori predefiniti in tutte le altre schede e fare clic su Verifica + crea per creare l'account di archiviazione.
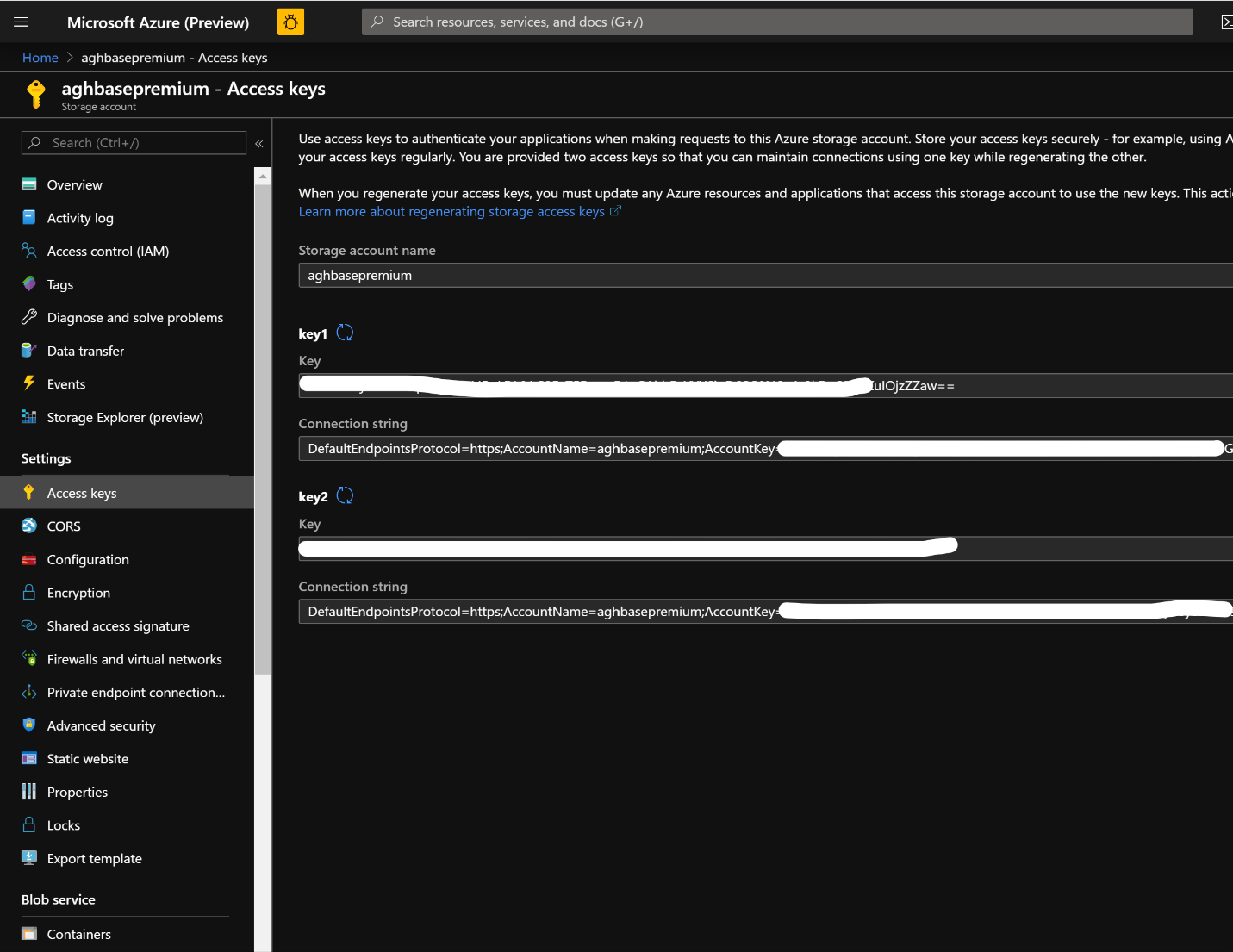
Dopo aver creato l'account di archiviazione, fare clic su Chiavi di accesso a sinistra e copiare key1. Questa operazione verrà usata in un secondo momento nel processo di creazione del cluster.
Ora è possibile iniziare a distribuire un cluster HDInsight HBase con scritture accelerate. Selezionare Crea una risorsa > Analisi > HDInsight
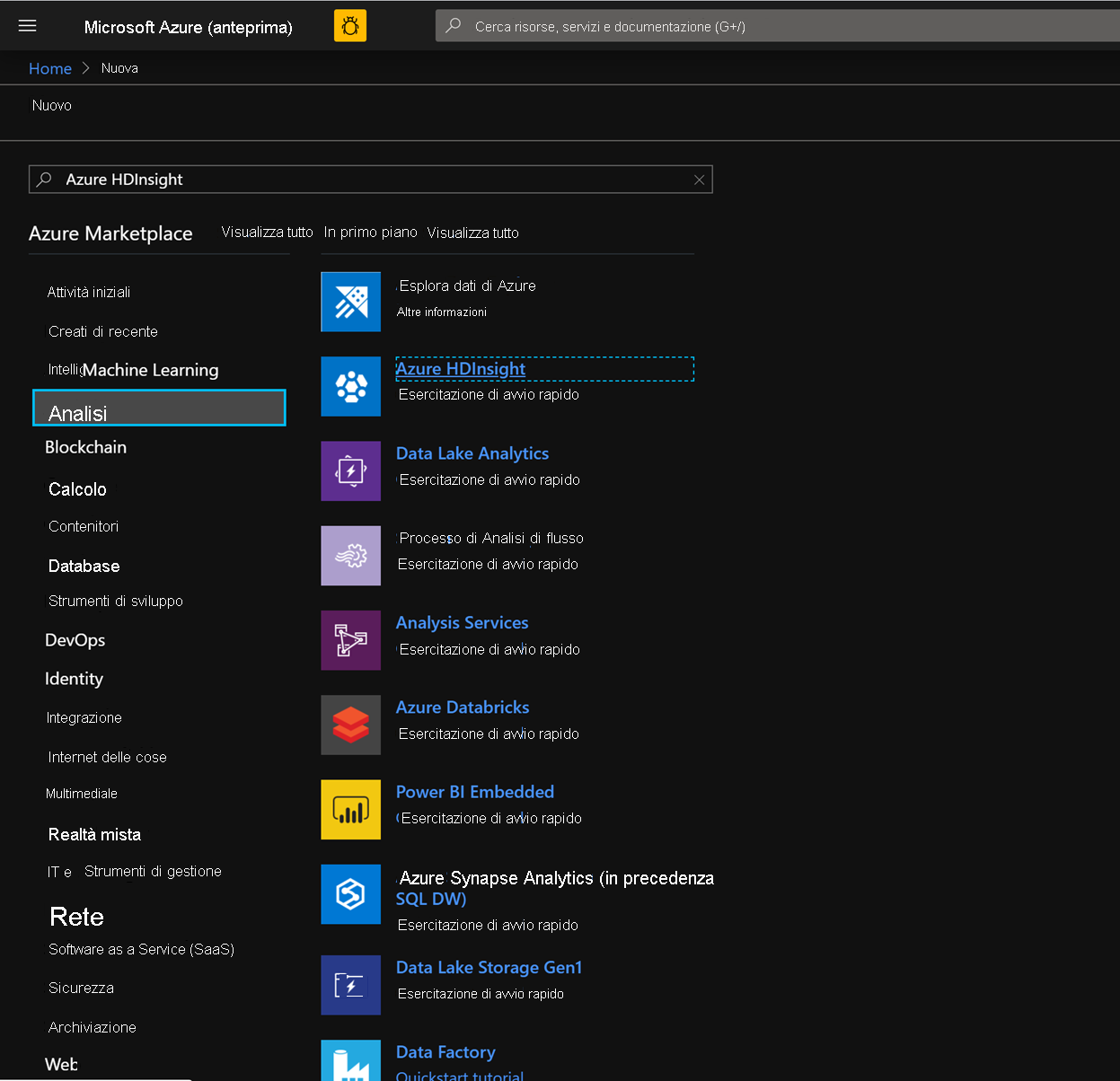
Nella scheda Informazioni di base, popolare i campi seguenti per creare un cluster HBase.
Sottoscrizione: deve essere popolato automaticamente con i dettagli della sottoscrizione
Gruppo di risorse: immettere un gruppo di risorse in cui gestire la distribuzione di HDInsight HBase
Nome del cluster: immettere il nome del cluster. Se il nome del cluster è disponibile, verrà visualizzato un segno di spunta verde.
Area: immettere il nome dell'area di distribuzione
Tipo di cluster: Cluster Type - HBase. Version- HBase 2.0.0(HDI 4.0)
Nome utente dell'account di accesso del cluster: immettere il nome utente per l'amministratore del cluster (impostazione predefinita: admin)
Password dell'account di accesso del cluster: immettere la password per l'accesso al cluster (impostazione predefinita: sshuser)
Conferma password di accesso del cluster: confermare la password immessa nel passaggio precedente
Nome utente di Secure Shell (SSH): immettere l'utente dell'accesso SSH (impostazione predefinita: sshuser)
Usare la password di accesso del cluster per SSH: selezionare la casella per usare la stessa password per gli account di accesso SSH, per gli account di accesso Ambari e così via.
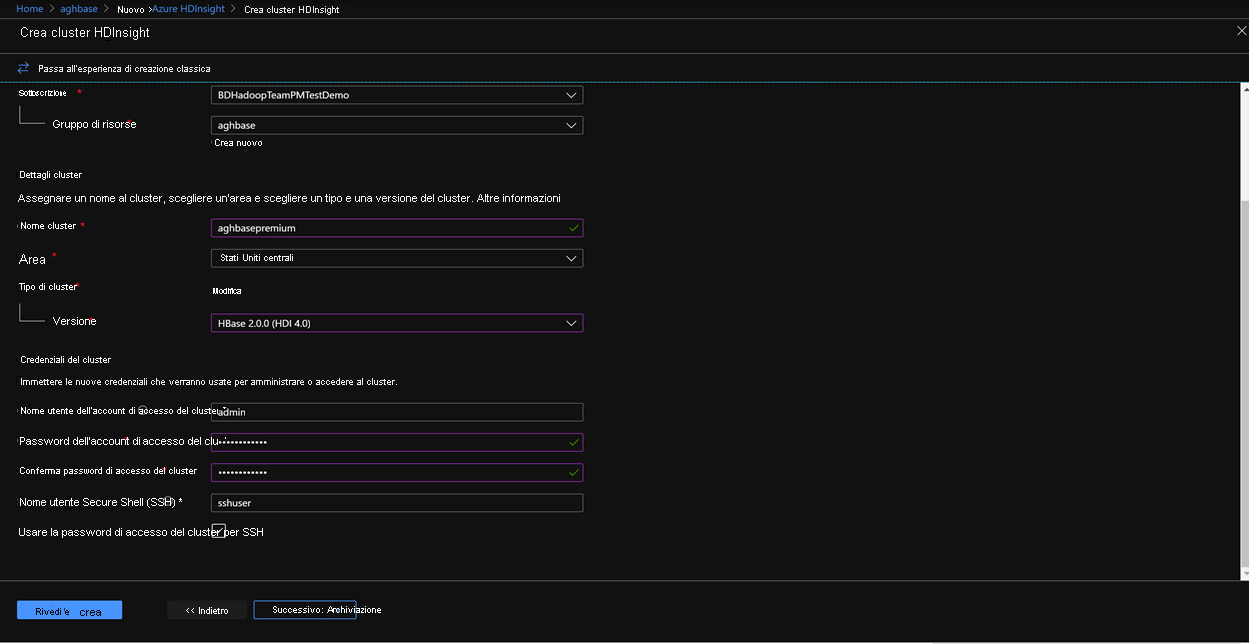
Fare clic su Avanti: Archiviazione per avviare la scheda Archiviazione e popolare i campi seguenti
Tipo di archiviazione primario: Archiviazione di Azure.
Metodo di selezione: scegliere il pulsante di opzione Usa chiave di accesso
Nome account di archiviazione: immettere il nome dell'account di archiviazione BLOB in blocchi Premium creato in precedenza
Chiave di accesso: immettere la chiave di accesso key1 copiata in precedenza
Contenitore: HDInsight deve proporre un nome di contenitore predefinito. È possibile scegliere questa opzione o creare un nome personalizzato.
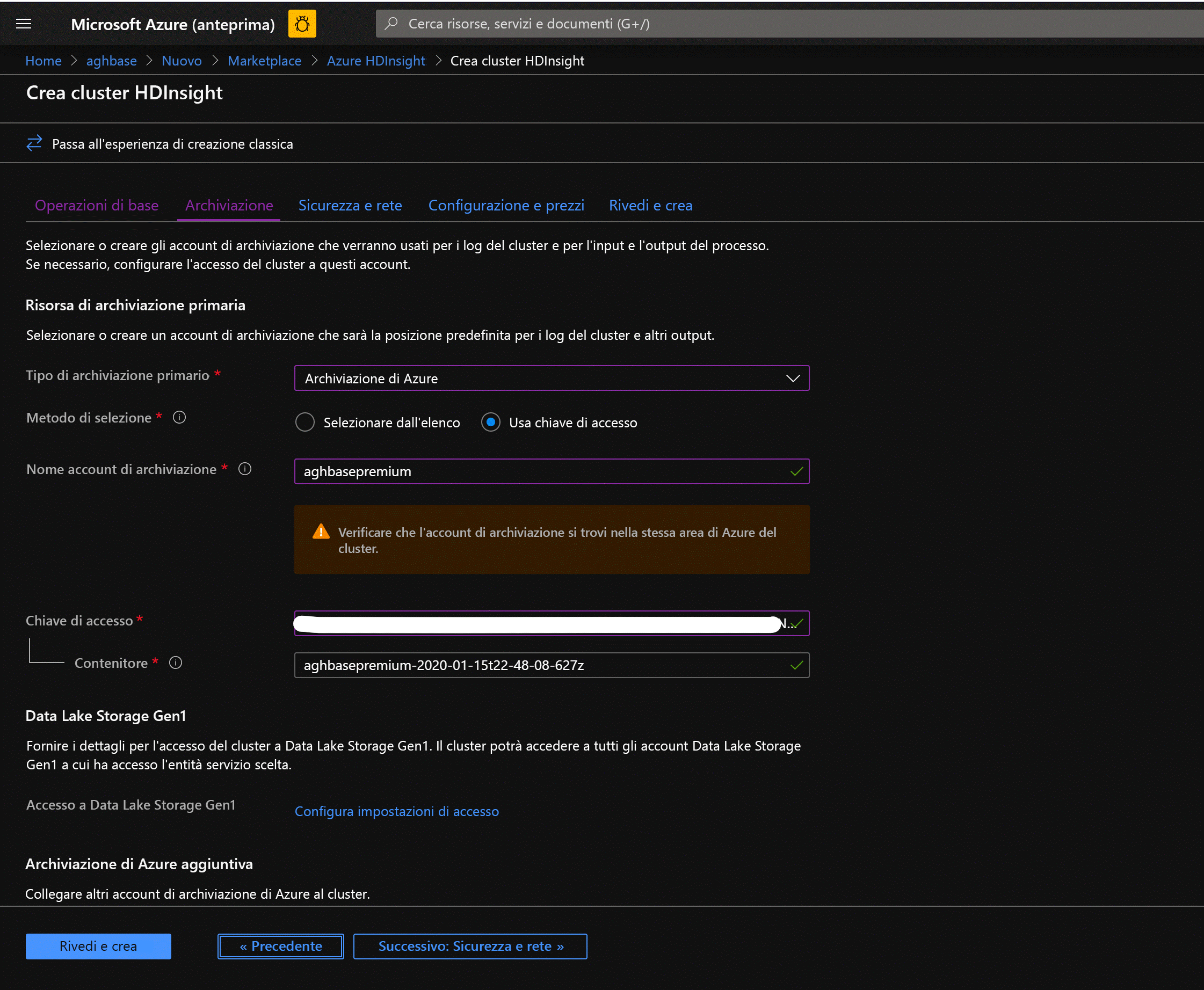
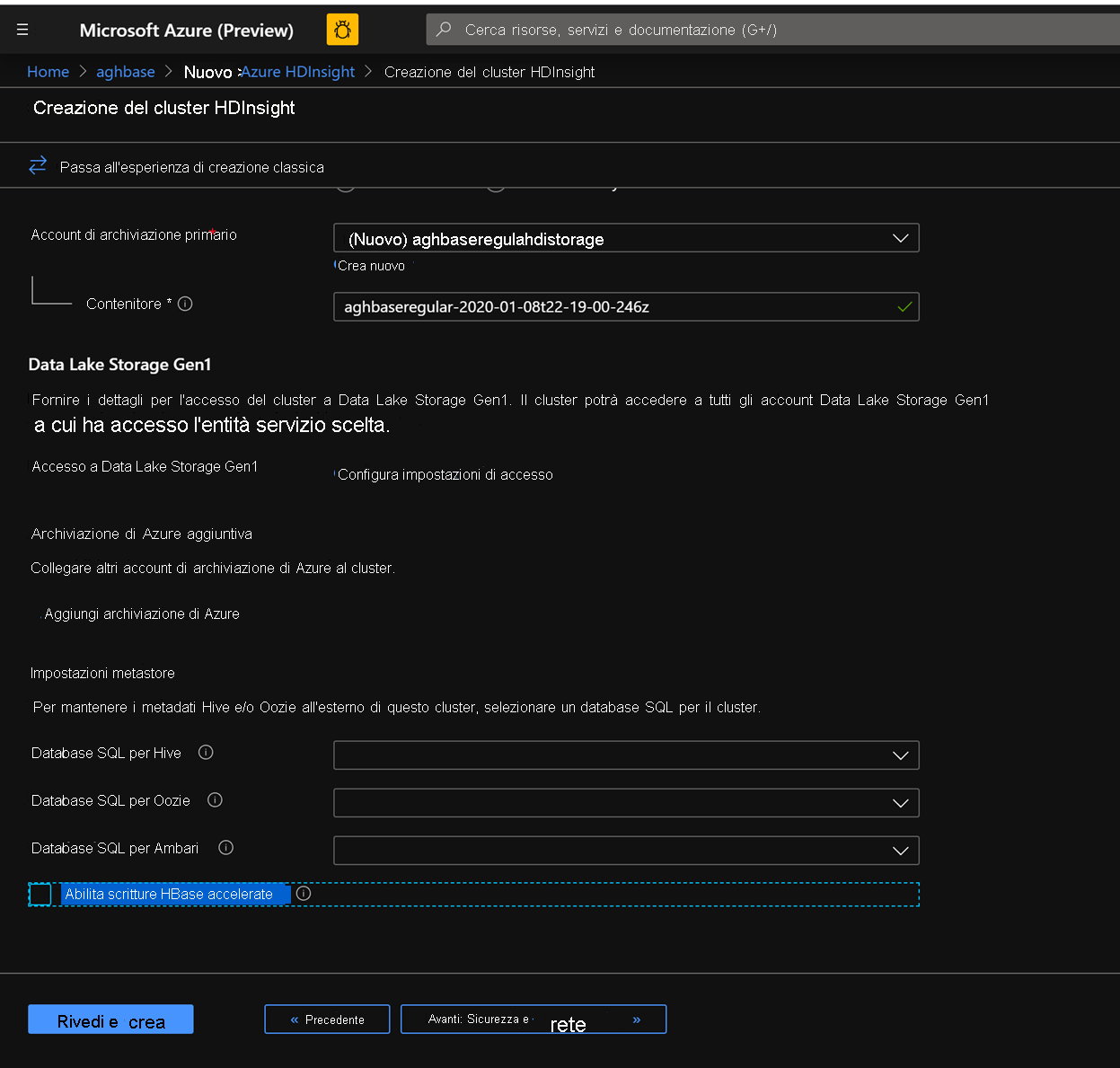
Lasciare invariate le altre opzioni e scorrere verso il basso per selezionare la casella di controllo Abilita scritture HBase accelerate. Si noti che in seguito verrà creato un secondo cluster senza scritture accelerate usando la stessa procedura ma con questa casella deselezionata.
Lasciare invariate le impostazioni predefinite nel pannello Sicurezza e rete e passare alla scheda Configurazione e prezzi.
Nella scheda Configurazione e prezzi si noti che la sezione Configurazione nodo ora include la voce Dischi Premium per nodo di lavoro.
Scegliere 10 per il nodo Area e DS14v2 per la dimensione del nodo. Si possono scegliere un numero inferiore di VM e SKU di VM di dimensioni minori, ma assicurarsi che entrambi i cluster abbiano un identico numero di nodi e SKU di VM per garantire la parità nel confronto.
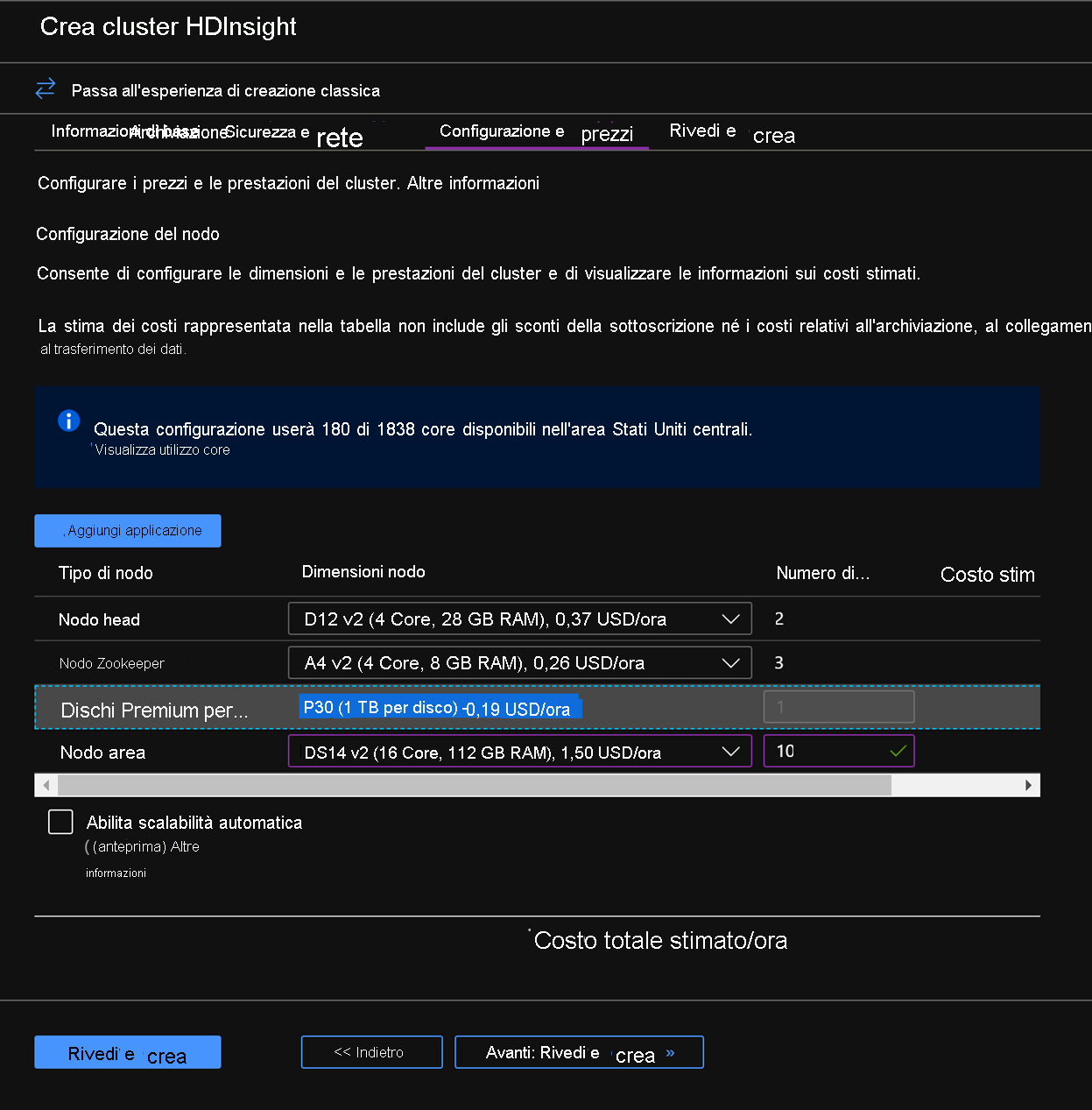
Fare clic su Avanti: Rivedi e crea
Nella scheda Rivedi e crea assicurarsi che le scritture HBase accelerate siano abilitate nella sezione Archiviazione.
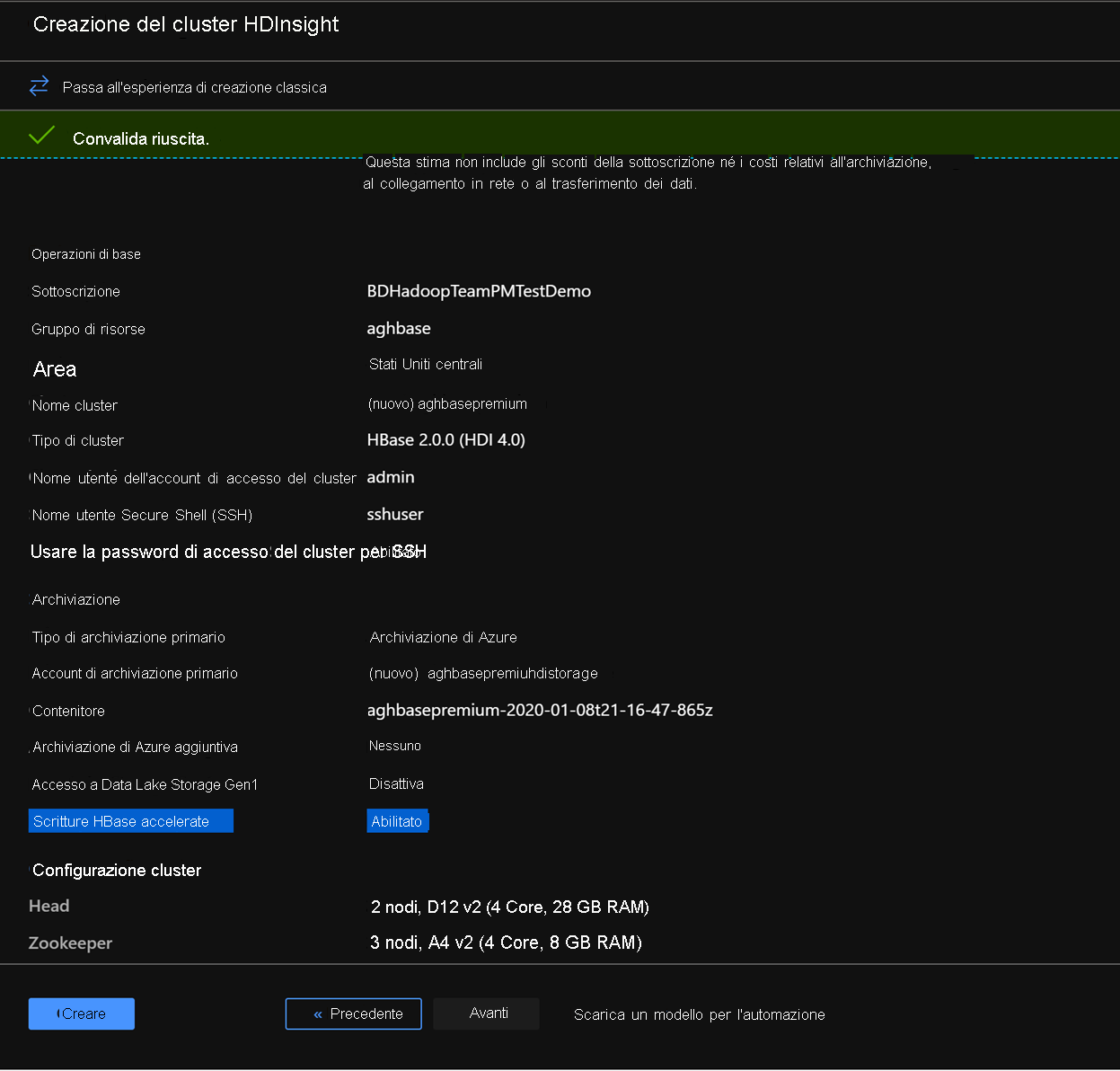
Fare clic su Crea per avviare la distribuzione del primo cluster con scritture accelerate.
Ripetere gli stessi passaggi per creare un secondo cluster HDInsight HBase, questa volta senza scritture accelerate. Notare le modifiche seguenti
Usare un account di archiviazione BLOB normale che è consigliato per impostazione predefinita
Lasciare deselezionata la casella di controllo Abilita scritture accelerate nella scheda Archiviazione.
Nella scheda Configurazione e prezzi per questo cluster si noti che nella sezione Configurazione del nodo non è presente la voce Dischi Premium per nodo di lavoro.
Scegliere 10 per il nodo Area e D14v2 per la dimensione del nodo. Si noti anche la mancanza dei tipi di VM serie DS come in precedenza. È possibile scegliere un numero inferiore di VM e SKU di VM di dimensioni minori, ma assicurarsi che entrambi i cluster abbiano un identico numero di nodi e SKU di VM per garantire la parità nel confronto.
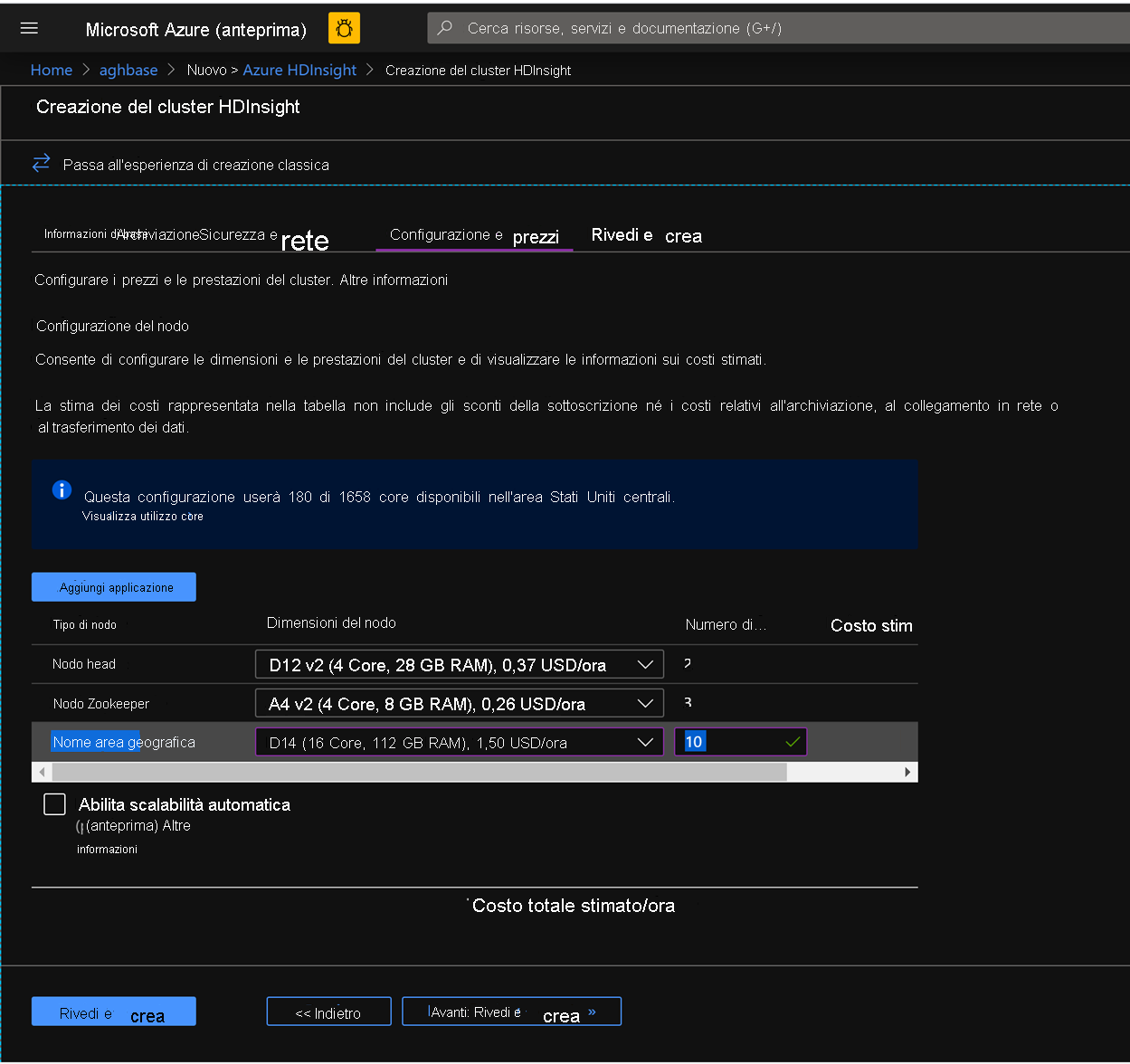
Fare clic su Crea per avviare la distribuzione del secondo cluster senza scritture accelerate.
Ora che sono state eseguite le distribuzioni dei cluster, nella sezione successiva verranno configurati ed eseguiti i test YCSB in entrambi i cluster.

Esecuzione di test YCSB
Accedere alla shell di HDInsight
I passaggi per la configurazione e l'esecuzione dei test YCSB in entrambi i cluster sono identici.
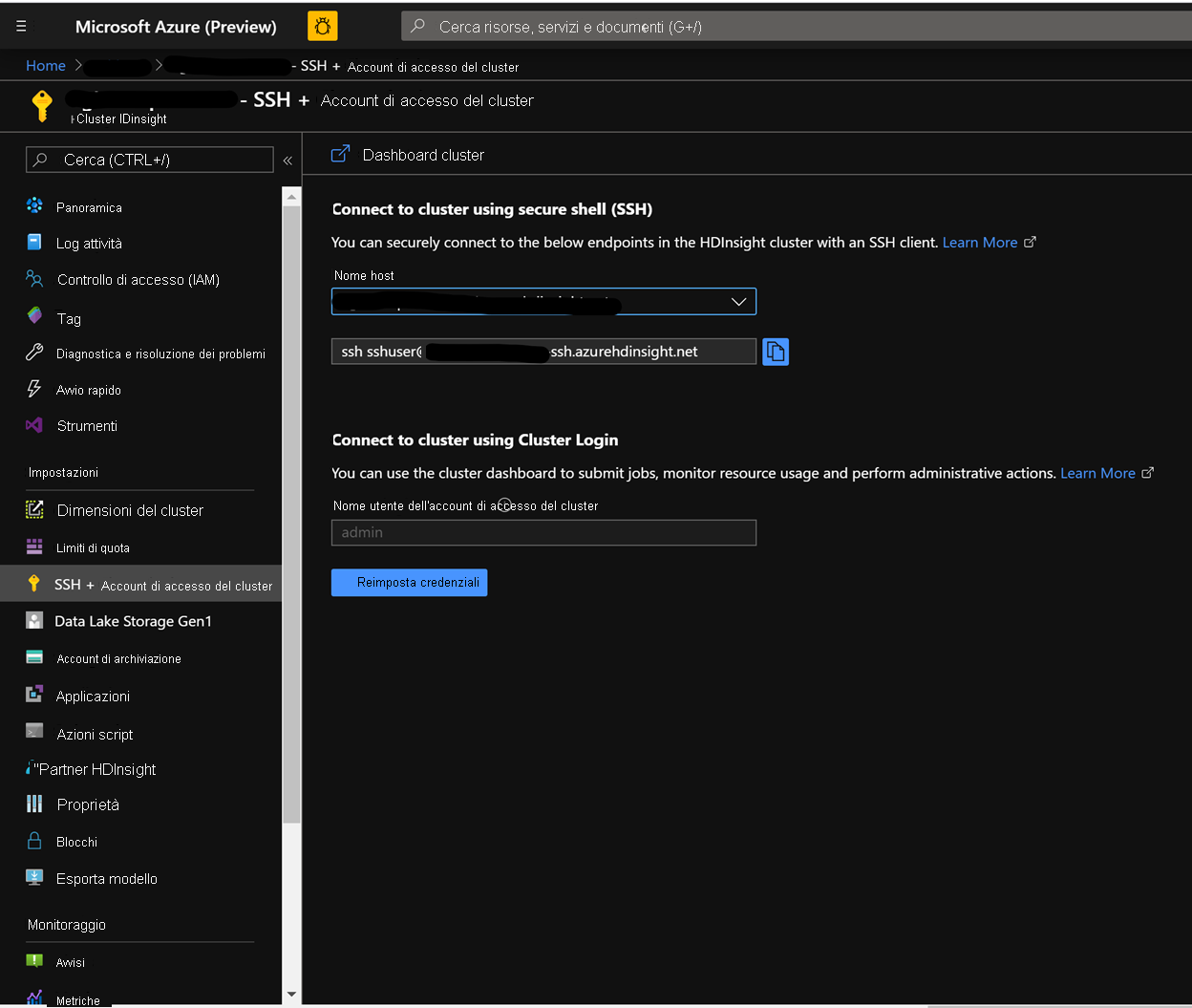
Nella pagina dei cluster del portale di Azure passare all'accesso SSH al cluster e usare il nome host e il percorso SSH per accedere al cluster con SSH. Il percorso deve avere il formato seguente.
ssh <sshuser>@<clustername>.azurehdinsight.net
Creare la tabella
Eseguire i passaggi seguenti per creare le tabelle HBase, che verranno usate per caricare i set di dati
Avviare la shell di HBase e impostare un parametro per il numero di suddivisioni della tabella. Impostare le suddivisioni della tabella (10 * numero di server di area)
Creare la tabella HBase, che verrà usata per eseguire i test
Uscire dalla shell di HBase
hbase(main):018:0> n_splits = 100 hbase(main):019:0> create 'usertable', 'cf', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}} hbase(main):020:0> exit
Scaricare il repository YSCB
Scaricare il repository YCSB dalla destinazione seguente
$ curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gzDecomprimere la cartella per accedere al contenuto
$ tar xfvz ycsb-0.17.0.tar.gzVerrà creata la cartella ycsb-0.17.0. Accedere a questa cartella
Eseguire un carico di lavoro con intensa attività di scrittura in entrambi i cluster
Usare il comando seguente per avviare un carico di lavoro con intensa attività di scrittura con i parametri seguenti
workloads/workloada: indica che deve essere eseguito workload/workloada per l'accodamento
table: popolare il nome della tabella HBase creata in precedenza
columnfamily: popolare il valore del nome della famiglia di colonne HBase indicato nella tabella creata
recordcount: numero di record da inserire (si usa 1 milione)
threadcount: numero di thread (può variare, ma deve essere mantenuto costante tra gli esperimenti)
-cp/etc/hbase/conf: puntatore alle impostazioni di configurazione di HBase
-s | tee-a: specificare un nome file per scrivere l'output.
bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat
Eseguire il carico di lavoro con intensa attività di scrittura per caricare 1 milione di righe nella tabella HBase creata in precedenza.
Nota
Ignorare gli avvisi che potrebbero essere visualizzati dopo l'invio del comando.
Esempi di risultati per HDInsight HBase con scritture accelerate
Esegui questo comando:
```CMD $ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat ```Leggere i risultati:
```CMD 2020-01-10 16:21:40:213 10 sec: 15451 operations; 1545.1 current ops/sec; est completion in 10 minutes [INSERT: Count=15452, Max=120319, Min=1249, Avg=2312.21, 90=2625, 99=7915, 99.9=19551, 99.99=113855] 2020-01-10 16:21:50:213 20 sec: 34012 operations; 1856.1 current ops/sec; est completion in 9 minutes [INSERT: Count=18560, Max=305663, Min=1230, Avg=2146.57, 90=2341, 99=5975, 99.9=11151, 99.99=296703] .... 2020-01-10 16:30:10:213 520 sec: 972048 operations; 1866.7 current ops/sec; est completion in 15 seconds [INSERT: Count=18667, Max=91199, Min=1209, Avg=2140.52, 90=2469, 99=7091, 99.9=22591, 99.99=66239] 2020-01-10 16:30:20:214 530 sec: 988005 operations; 1595.7 current ops/sec; est completion in 7 second [INSERT: Count=15957, Max=38847, Min=1257, Avg=2502.91, 90=3707, 99=8303, 99.9=21711, 99.99=38015] ... ... 2020-01-11 00:22:06:192 564 sec: 1000000 operations; 1792.97 current ops/sec; [CLEANUP: Count=8, Max=80447, Min=5, Avg=10105.12, 90=268, 99=80447, 99.9=80447, 99.99=80447] [INSERT: Count=8512, Max=16639, Min=1200, Avg=2042.62, 90=2323, 99=6743, 99.9=11487, 99.99=16495] [OVERALL], RunTime(ms), 564748 [OVERALL], Throughput(ops/sec), 1770.7012685303887 [TOTAL_GCS_PS_Scavenge], Count, 871 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3116 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.5517505152740692 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 871 [TOTAL_GC_TIME], Time(ms), 3116 [TOTAL_GC_TIME_%], Time(%), 0.5517505152740692 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 10105.125 [CLEANUP], MinLatency(us), 5 [CLEANUP], MaxLatency(us), 80447 [CLEANUP], 95thPercentileLatency(us), 80447 [CLEANUP], 99thPercentileLatency(us), 80447 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 2248.752362 [INSERT], MinLatency(us), 1120 [INSERT], MaxLatency(us), 498687 [INSERT], 95thPercentileLatency(us), 3623 [INSERT], 99thPercentileLatency(us), 7375 [INSERT], Return=OK, 1000000 ```Esplorare il risultato del test. Questi sono alcuni esempi di osservazioni dei risultati precedenti:
- L'esecuzione del test ha richiesto 538663 millisecondi (8,97 minuti)
- Valore restituito=OK, 1000000 indica che l'intero milione di input è stato scritto correttamente, **
- La velocità effettiva di scrittura era 1856 operazioni al secondo
- Il 95% degli inserimenti aveva una latenza di 3389 millisecondi
- Pochi inserimenti hanno impiegato più tempo, probabilmente sono stati bloccati dai server di area a causa del carico di lavoro elevato
Esempi di risultati per HDInsight HBase senza scritture accelerate
Esegui questo comando:
$ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.datLeggere i risultati:
2020-01-10 23:58:20:475 2574 sec: 1000000 operations; 333.72 current ops/sec; [CLEANUP: Count=8, Max=79679, Min=4, Avg=9996.38, 90=239, 99=79679, 99.9 =79679, 99.99=79679] [INSERT: Count=1426, Max=39839, Min=6136, Avg=9289.47, 90=13071, 99=27535, 99.9=38655, 99.99=39839] [OVERALL], RunTime(ms), 2574273 [OVERALL], Throughput(ops/sec), 388.45918828344935 [TOTAL_GCS_PS_Scavenge], Count, 908 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3208 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.12461770760133055 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 908 [TOTAL_GC_TIME], Time(ms), 3208 [TOTAL_GC_TIME_%], Time(%), 0.12461770760133055 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 9996.375 [CLEANUP], MinLatency(us), 4 [CLEANUP], MaxLatency(us), 79679 [CLEANUP], 95thPercentileLatency(us), 79679 [CLEANUP], 99thPercentileLatency(us), 79679 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 10285.497832 [INSERT], MinLatency(us), 5568 [INSERT], MaxLatency(us), 1307647 [INSERT], 95thPercentileLatency(us), 18751 [INSERT], 99thPercentileLatency(us), 33759 [INSERT], Return=OK, 1000000Confrontare i risultati:
Parametro Unità Con scritture accelerate Senza scritture accelerate [OVERALL], RunTime(ms) Millisecondi 567478 2574273 [OVERALL], Throughput(ops/sec) Operazioni/sec 1770 388 [INSERT], Operations # of Operations 1000000 1000000 [INSERT], 95thPercentileLatency(us) Microseconds 3623 18751 [INSERT], 99thPercentileLatency(us) Microseconds 7375 33759 [INSERT], Return=OK # of records 1000000 1000000 Di seguito sono riportati alcuni esempi di osservazioni che è possibile effettuare per i confronti:
- [OVERALL], RunTime(ms): tempo di esecuzione totale in millisecondi
- [OVERALL], Throughput(ops/sec): numero di operazioni al secondo in tutti i thread
- [INSERT], Operations: numero totale di operazioni di inserimento, a cui sono associati i seguenti valori per le latenze media, minima, massima, 95° e 99° percentile
- [INSERT], 95thPercentileLatency(us): il 95% delle operazioni INSERT ha un punto dati inferiore a questo valore
- [INSERT], 99thPercentileLatency(us): il 99% delle operazioni INSERT ha un punto dati inferiore a questo valore
- [INSERT], Return=OK: OK indica che tutte le operazioni INSERT sono state eseguite correttamente e include il relativo conteggio
Considerare la possibilità di provare un intervallo di altri carichi di lavoro per eseguire confronti. Alcuni esempi:
Mostly Read(95% Read & 5% Write) : workloadb
bin/ycsb run hbase12 -P workloads/workloadb -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadb.datRead Only(100% Read & 0% Write) : workloadc
bin/ycsb run hbase12 -P workloads/workloadc -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadc.dat