Usare Apache Phoenix in HDInsight HBase
I cluster HBase in HDInsight sono disponibili con Apache Phoenix. Apache Phoenix è un livello di database relazionale open source altamente parallelo basato su Apache HBase. Apache Phoenix consente di usare query di tipo SQL su HBase. Usa i driver JDBC sottostanti per consentire agli utenti di creare, eliminare e modificare le tabelle SQL. È anche possibile indicizzare, creare viste e sequenze ed eseguire l'upsert delle righe singolarmente e in blocco. Phoenix usa la compilazione nativa NoSQL anziché MapReduce per compilare query, consentendo la creazione di applicazioni a bassa latenza basate su HBase. Phoenix aggiunge coprocessori per supportare l'esecuzione del codice fornito dal client nello spazio degli indirizzi del server, eseguendo il codice che si trova nello stesso percorso dei dati. Questo approccio consente di ridurre al minimo il trasferimento di dati client/server. Per altre informazioni, vedere la documentazione di Apache Phoenix.
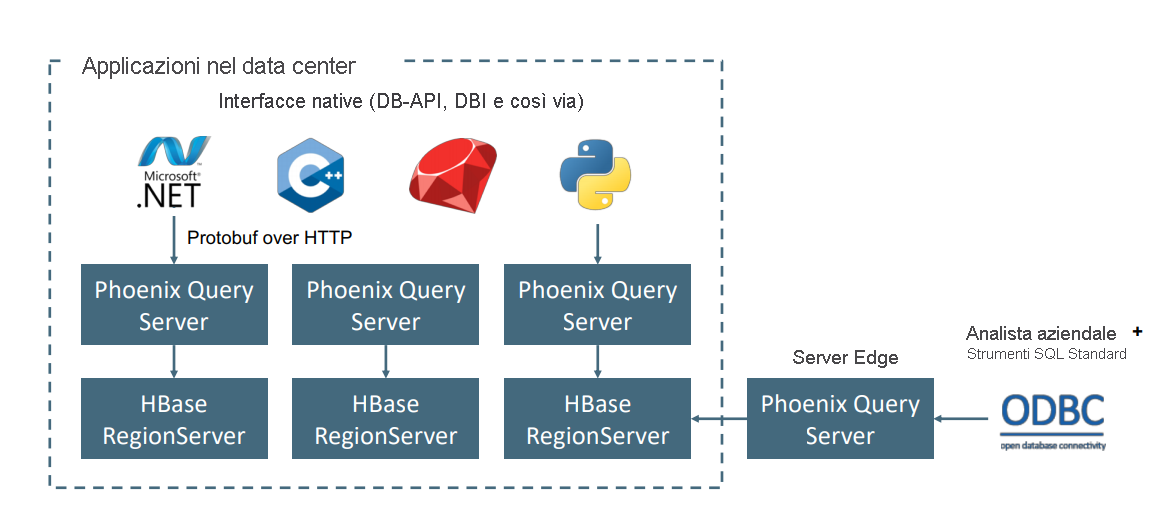
Apache Phoenix in HDInsight HBase viene in genere usato per abilitare l'analisi self-service ed estrarre dati analitici come illustrato di seguito. Phoenix può essere collegato a qualsiasi strumento di business intelligence compatibile con ODBC e abilitare l'analisi SQL ad hoc in HBase.
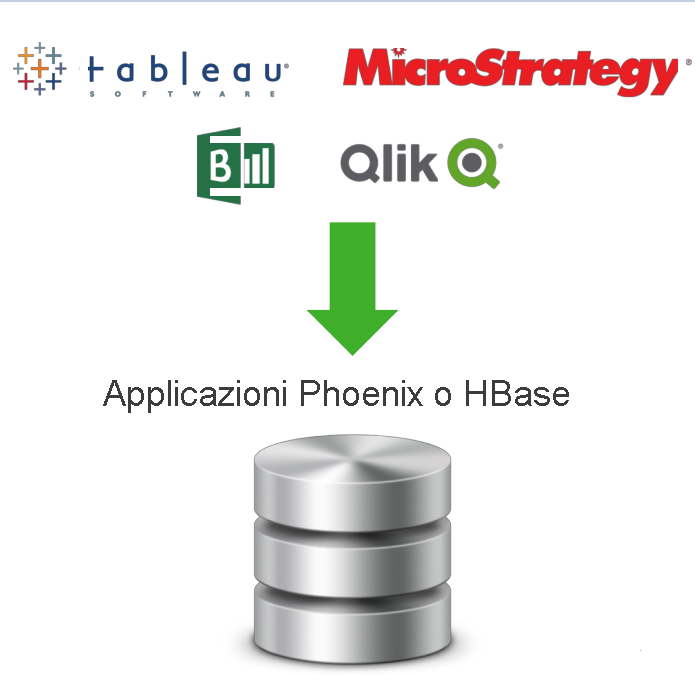
La combinazione di Apache HBase e Phoenix può essere usata come archivio dati per i dati modificabili. Il motore di query di Apache Phoenix in HBase include alcune funzionalità importanti.
Indici secondari
È possibile accedere ai record in HBase usando la chiave di riga primaria e un singolo indice ordinato in modo lessicografico sulla chiave di riga primaria. Se si tenta di accedere ai record in qualsiasi modo che non sia usare la riga primaria, viene eseguita un'analisi inefficiente di tutti i dati nella tabella HBase. Apache Phoenix consente di creare indici secondari per colonne ed espressioni per creare chiavi di riga alternative per consentire ricerche di punti o analisi di intervalli lungo insieme al nuovo indice. Per altre informazioni, vedere la documentazione relativa agli indici secondari di Apache Phoenix.
Il comando CREATE INDEX viene usato per creare indici secondari in HBase, come illustrato di seguito.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Visualizzazioni
Limitare il numero di tabelle fisiche in HBase e di conseguenza limitare il numero di aree è una strategia consigliata. Le viste in Phoenix supportano questo consiglio consentendo la creazione di più tabelle virtuali che condividono la stessa tabella fisica sottostante in HBase. Per altre informazioni, vedere la documentazione relativa alle viste di Apache Phoenix.
Data la definizione di tabella seguente in HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
È possibile definire la vista seguente.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Transazioni
Benché HBase funzioni solo con le transazioni a livello di riga, Apache Phoenix consente transazioni tra tabelle e tra righe con supporto ACID completo grazie all'integrazione con Apache Tephra.
Per altre informazioni, vedere la documentazione relativa alle transazioni in Apache Phoenix.
Nell'esempio seguente viene creata una tabella denominata my_table, che viene quindi modificata per abilitare le transazioni.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Tabelle con salting
In HBase si può verificare l'hotspot del server di area durante le scritture sequenziali se le chiavi di riga aumentano in modo progressivo. Apache Phoenix può alleviare l'hotspot offrendo la possibilità di effettuare il salting della chiave di riga con un byte di salting per una determinata tabella. Per altre informazioni, fare riferimento alla documentazione relativa alla tabella con salting di Apache Phoenix.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Ignora analisi
Per un determinato set di righe, Apache Phoenix usa Ignora analisi per l'analisi tra righe rispetto a un'analisi di intervallo per migliorare le prestazioni. Ignora analisi usa il filtro SEEK_NEXT_USING_HINT di HBase. Archivia le informazioni sul set di chiavi o intervalli di chiavi in cui viene eseguita la ricerca in ogni colonna. Acquisisce quindi una chiave (passata durante la valutazione del filtro) e verifica se si trova in una delle combinazioni o uno degli intervalli. In caso contrario, calcola la successiva chiave più alta da saltare. Per altre informazioni, vedere la documentazione relativa a Ignora analisi di Apache Phoenix.
L'ottimizzazione delle prestazioni in Apache Phoenix è una funzionalità facoltativa richiesta e dipende principalmente dall'ottimizzazione delle prestazioni di HBase sottostanti. L'ottimizzazione delle prestazioni è un argomento complesso che esula dall'ambito di questo corso. Tuttavia, se si è interessati, è possibile fare riferimento alla documentazione relativa alle procedure consigliate per le prestazioni di Apache Phoenix.