Descrivere Apache HBase
Apache HBase è un database NoSQL open source basato su Apache Hadoop. HBase offre accesso casuale e coerenza assoluta per quantità elevate di dati non strutturati e semistrutturati in un database privo di schema organizzato per famiglie di colonne. I cluster HBase di HDInsight 4.0 sono dotati di Apache HBase 2.1.6 e Apache Phoenix 5.
Dal punto di vista dell'utente, HBase è simile a un database. I dati sono archiviati nelle righe e nelle colonne di una tabella e i dati di ogni riga sono raggruppati in base al tipo di colonna. HBase è un database privo di schema, poiché non è necessario definire le colonne o i tipi di dati archiviati nelle colonne prima dell'uso. Il codice open source offre scalabilità lineare, in modo da gestire petabyte di dati in migliaia di nodi.
HBase offre le funzionalità seguenti che lo rendono unico
Coerenza in lettura e scrittura
Operazioni a bassa latenza
Partizionamento orizzontale automatico
Failover automatici del server di area
Integrazione con Hadoop/HDFS/MapReduce
API client Java
Supporta Thrift e REST per i front-end non Java
Cache in blocchi e filtri Bloom
Azure HDInsight HBase con Apache Phoenix offre i seguenti vantaggi aggiuntivi
SQL e nessuna interfaccia SQL
Pianificazione flessibile della capacità
Distribuzione e replica globali con la rete di Azure
Separazione di calcolo e archiviazione
Strettamente integrato con le funzionalità di sicurezza di HDInsight Enterprise
HDInsight HBase offre scritture accelerate per letture e scritture con latenza bassissima
Apache Phoenix per SQL in tempo reale, ad esempio l'esecuzione di query
L'uso di Azure HDInsight con HBase consente di eseguire database NoSQL su vasta scala. In qualità di ingegnere dei dati per Contoso, l'utente deve essere in grado di eseguire i test di benchmark per comprendere le prestazioni e la scalabilità di HDInsight HBase prima di usare la piattaforma per scenari di produzione mission critical.
HBase su HDInsight viene eseguito con la separazione tra calcolo e archiviazione. I cluster HDInsight HBase sono configurati per archiviare i dati direttamente in Archiviazione di Azure, che offre bassa latenza e maggiore flessibilità nelle opzioni relative a prestazioni e costi. Questa proprietà consente ai clienti di creare siti Web interattivi compatibili con set di dati di grandi dimensioni, per creare servizi che archiviano i dati di telemetria e dei sensori provenienti da milioni di endpoint e per analizzare questi dati con i processi Hadoop. HBase e Hadoop costituiscono validi punti di partenza per i progetti di Big Data in Azure. Grazie ai servizi è possibile consentire ad applicazioni in tempo reale di usare set di dati di grandi dimensioni. Le implementazioni di HDInsight HBase usano un'architettura con scale-out di HBase per assicurare il partizionamento orizzontale automatico delle tabelle, oltre a coerenza assoluta per le operazioni di lettura e scrittura e failover automatico. Le prestazioni sono ottimizzate dalla cache in memoria per le operazioni di lettura e da flussi a velocità effettiva elevata per quelle di scrittura. È possibile creare un cluster HBase in una rete virtuale. Per informazioni dettagliate, vedere Creare cluster HDInsight nella rete virtuale di Azure.
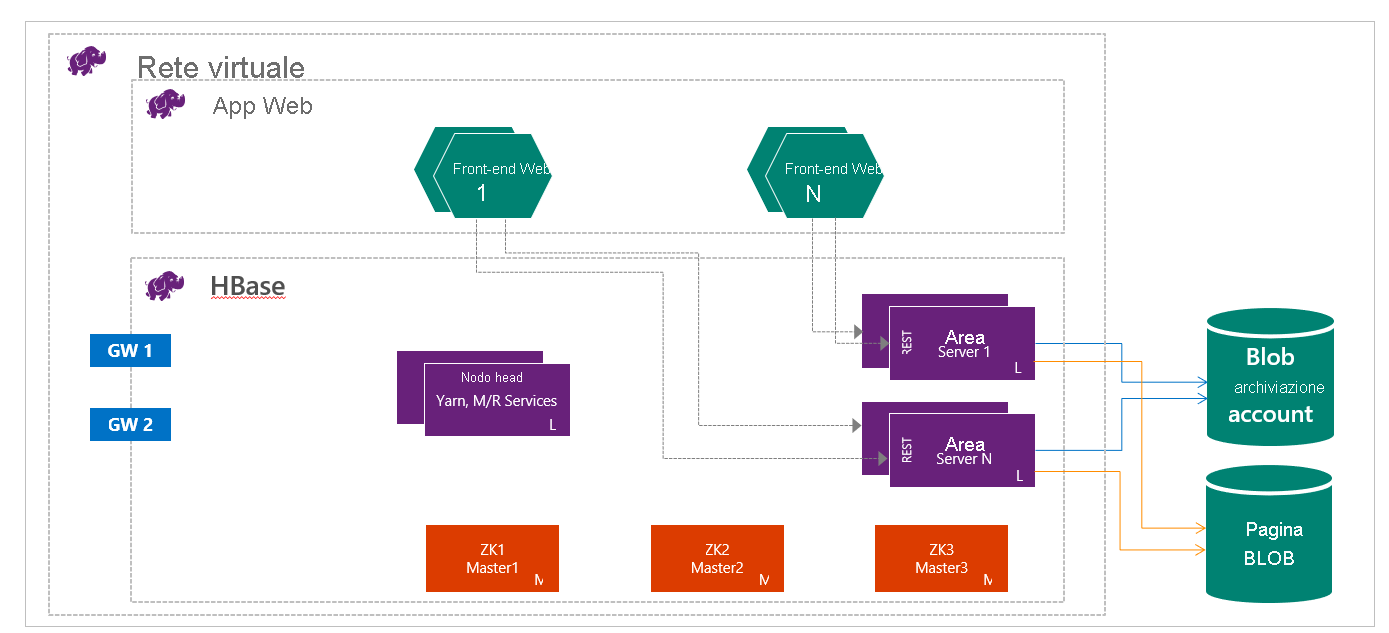
In qualità di ingegnere dei dati, si deve determinare il tipo di cluster HDInsight più appropriato per le esigenze di compilazione di una soluzione. Si useranno cluster HBase in HDInsight per un database NoSQL con scalabilità lineare, ottenendo un notevole aumento della velocità effettiva disponibile, letture a bassa latenza e archiviazione illimitata a una frazione del costo.
Di seguito sono riportati gli scenari principali per l'uso di HBase in HDInsight.
Archivio chiave-valore
HBase normalmente viene usato come archivio di tipo chiave-valore ed è adatto alla gestione di sistemi di messaggistica.
Dati di sensori
HBase è utile per l'acquisizione dei dati raccolti in modo incrementale da diverse origini, tra cui analisi delle reti sociali, serie temporali, aggiornamento continuo di dashboard interattivi con tendenze e contatori e gestione dei sistemi di log di controllo.
Query in tempo reale
Apache Phoenix è un motore di query SQL per Apache HBase. Vi si accede mediante un driver JDBC e permette di eseguire query e di gestire le tabelle HBase tramite SQL.
HBase come piattaforma
Le applicazioni possono essere eseguite su HBase, usato come un archivio dati. Alcuni esempi sono Phoenix, OpenTSDB, Kiji e Titan. Le applicazioni possono anche essere integrate con HBase, Alcuni esempi: Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia e Apache Drill.
In HDInsight HBase può essere usato come applicazione autonoma o distribuito insieme ad altre applicazioni di analisi dei Big Data, ad esempio Spark, Hadoop, Hive o Kafka.
Il modello di dati HBase archivia i dati semistrutturati con tipi di dati diversi e dimensioni variabili di colonne e campi. Il layout del modello di dati HBase semplifica il partizionamento e la distribuzione dei dati nel cluster. Il modello di dati HBase è costituito da diversi componenti logici: chiavi di riga, famiglia di colonne, nome di tabella, timestamp e così via.
Una chiave di riga viene usata per identificare in modo univoco le righe nelle tabelle HBase. In HDInsight è possibile scrivere i dati direttamente in HBase usando diverse API a disposizione, ad esempio REST HBase, RPC HBase, Phoenix Query Server, caricamento bulk HBase, oppure usare l'integrazione con diversi framework di Big Data, ad esempio Apache Spark, Hive e così via.
Per abilitare la velocità effettiva di scrittura elevata, è possibile usare la funzionalità di scrittura accelerata di HBase. Per altre informazioni sull'architettura e sulle procedure consigliate di HBase, vedere il book di HBase.