Eseguire failover e failback con Azure Site Recovery
Azure Site Recovery offre all'organizzazione la flessibilità di scegliere tra l'esecuzione manuale del failover in un'area di Azure secondaria oppure del failback in una macchina virtuale di origine. Il modo più semplice per gestire questo processo consiste nel farlo manualmente dal portale di Azure. Sono disponibili altre opzioni per abilitare l'automazione se l'azienda vuole automatizzare l'attivazione di un failover. Queste opzioni includono tecnologie come l'esecuzione di script tramite PowerShell o la configurazione di runbook in Automazione di Azure per orchestrare i failover.
Seguire questa procedura per eseguire un failover completo di una macchina virtuale protetta in un'area secondaria nella sottoscrizione. Dopo il completamento del failover, si eseguirà il failback della macchina virtuale.
In questa unità verranno esaminati il failover e il failback, come riproteggere una macchina virtuale sottoposta a failover e come monitorare lo stato della riprotezione.
Che cos'è il failover?
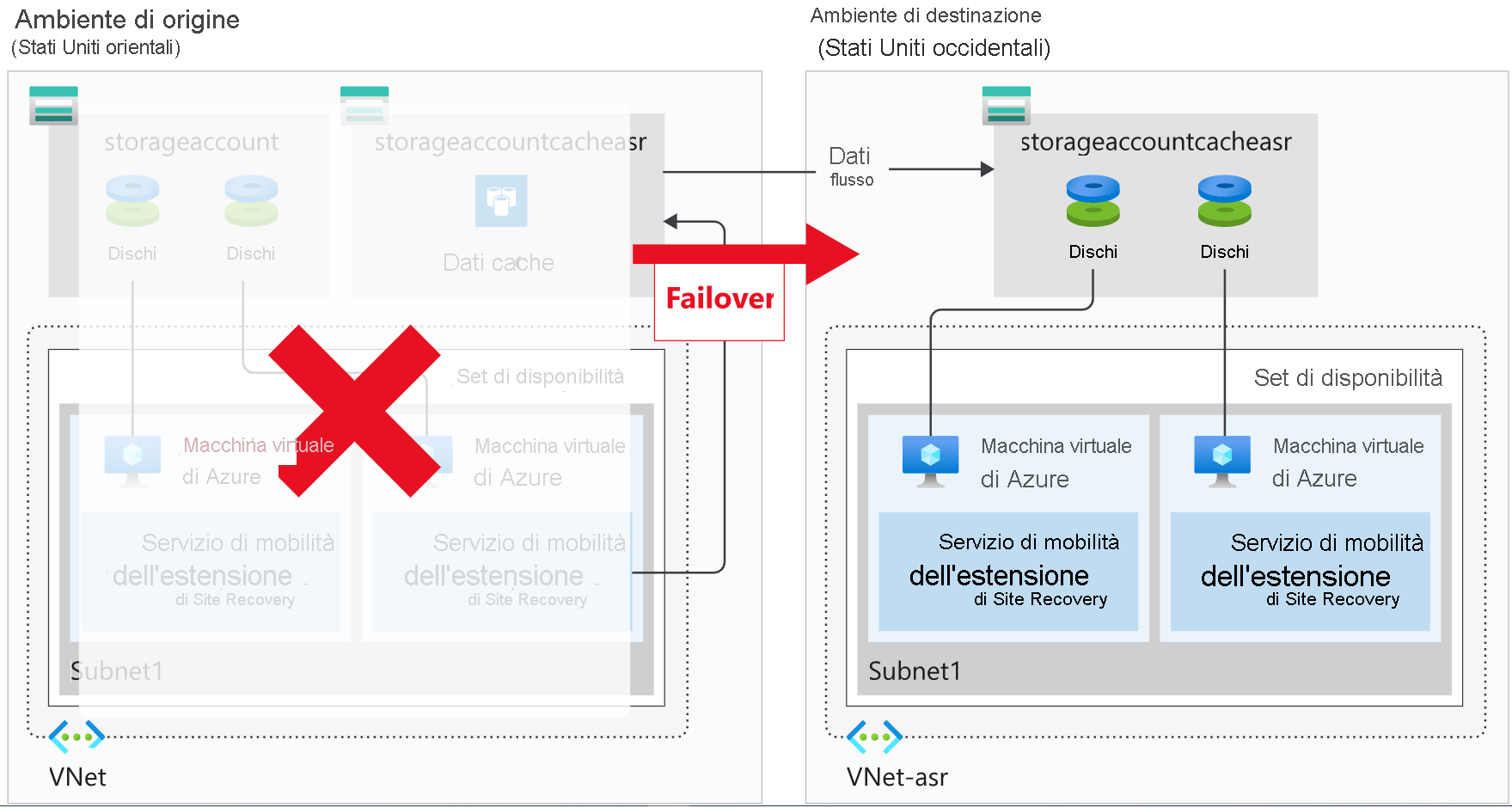
Si verifica un failover quando viene presa una decisione di eseguire un piano di ripristino di emergenza per l'organizzazione. L'ambiente di produzione esistente, protetto da Site Recovery, viene replicato in un'area diversa. L'ambiente di destinazione diventa l'ambiente di produzione effettivo, nonché l'ambiente in cui vengono eseguiti i servizi di produzione dell'organizzazione. Quando l'area di destinazione diventa attiva, l'ambiente di origine non deve più essere usato. Per applicare questa condizione, le macchine virtuali di origine vengono lasciate arrestate.
L'arresto delle macchine virtuali di origine offre un altro vantaggio. Se si usa una macchina virtuale arrestata, la perdita di dati è minima, perché Site Recovery attende fino a quando tutti i dati non sono stati scritti sul disco prima di attivare il failover. Per usare questi dati e ottenere l'obiettivo del punto di ripristino più basso possibile, selezionare il punto di ripristino Più recente (RPO più basso).
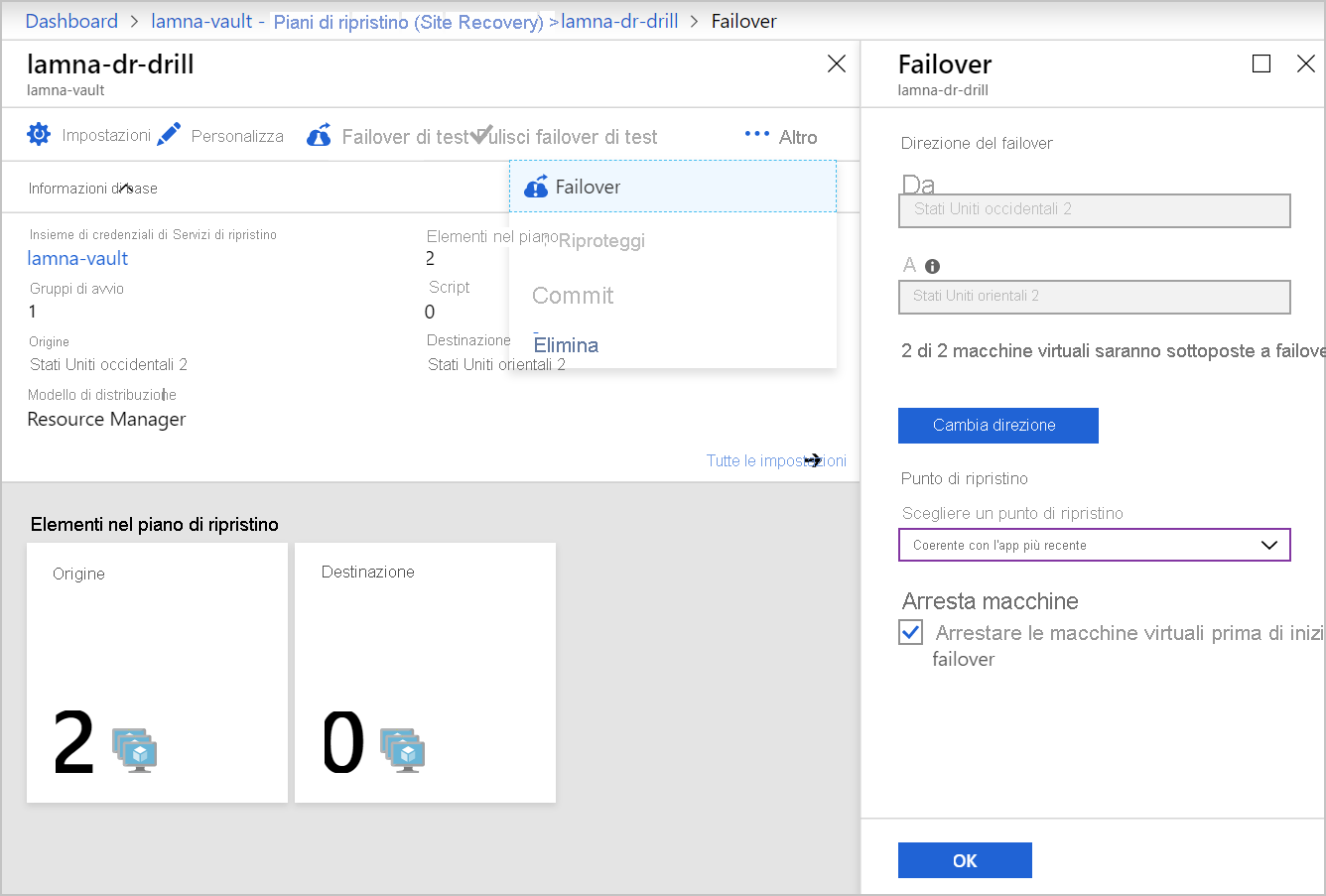
Che cos'è la riprotezione e perché è importante?
Quando viene eseguito il failover di una macchina virtuale, la replica eseguita da Site Recovery non è più attiva. È necessario abilitare di nuovo la protezione per iniziare a proteggere la macchina virtuale sottoposta a failover. Poiché l'infrastruttura si trova già in un'area diversa, è possibile riavviare la replica nell'area di origine. La riprotezione consente a Site Recovery di avviare la replica del nuovo ambiente di destinazione di nuovo nell'ambiente di origine.
Per la riprotezione dell'infrastruttura di cui è stato eseguito il failover, è possibile sfruttare la flessibilità del failover di singole macchine virtuali o tramite un piano di ripristino. È possibile riproteggere ogni macchina virtuale singolarmente oppure è possibile riproteggere più macchine virtuali usando un piano di ripristino.
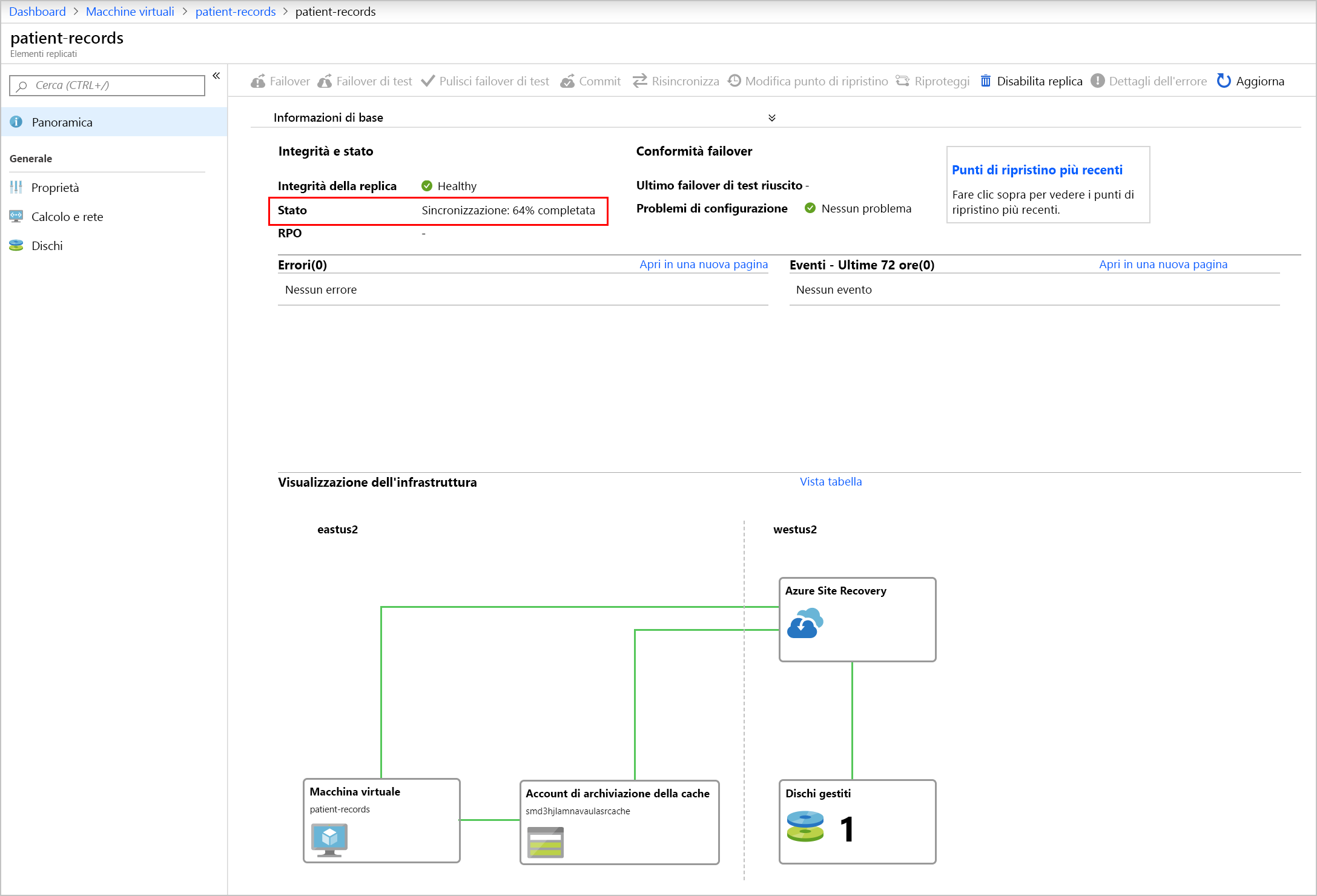
La riprotezione richiede da 45 minuti a 2 ore, a seconda delle dimensioni e del tipo di macchina virtuale. A differenza delle altre operazioni di Site Recovery che possono essere monitorate controllando lo stato di avanzamento dei processi, lo stato di riprotezione deve essere visualizzato a livello di macchina virtuale. Ciò è dovuto al fatto che la fase di sincronizzazione non è elencata come processo di Site Recovery.
Questa immagine mostra lo stato dell'elemento, con evidenziata la percentuale sincronizzata.
Che cos'è il failback?
Il failback è il contrario di un failover. Avviene quando è stato eseguito il commit di un failover completato in un'area secondaria che ora è l'ambiente di produzione. La riprotezione è stata completata per l'ambiente sottoposto a failover e l'ambiente di origine è ora la replica. In uno scenario di failback, Site Recovery esegue di nuovo il failover nelle macchine virtuali di origine.
Il processo di completamento di un failback è identico a quello di un failover, compreso il riutilizzo del piano di ripristino. Quando si seleziona il failover nel piano di ripristino, per l'opzione Da è impostata l'area di destinazione e per l'opzione A l'area di origine.
Gestire i failover
Site Recovery consente di eseguire i failover su richiesta. I failover di test sono isolati e non influiscono quindi sui servizi di produzione. Questa flessibilità consente di eseguire un failover senza interrompere gli utenti del sistema. La flessibilità si applica anche ai failback, che possono essere eseguiti su richiesta, come parte di un test pianificato o di un processo di ripristino di emergenza richiamato.
I piani di ripristino in Site Recovery consentono anche la personalizzazione e la sequenziazione del failover e del failback. I piani consentono di raggruppare i computer e i carichi di lavoro.
La flessibilità si applica anche alla modalità di attivazione del processo di failover. I failover manuali sono facili da eseguire tramite il portale di Azure. Usando script di PowerShell o runbook in Automazione di Azure è anche possibile fornire opzioni di automazione.
Correggere i problemi di un failover
Anche se Site Recovery è un servizio automatizzato, possono verificarsi errori. L'elenco seguente illustra i tre problemi più comuni osservati. Per un elenco completo dei problemi e per informazioni su come risolverli, vedere il collegamento nell'unità Riepilogo.
Problemi di quota delle risorse di Azure
Site Recovery deve creare risorse in aree diverse. Se la sottoscrizione non consente di eseguire questa operazione, la replica ha esito negativo. Questo errore si verifica anche se la sottoscrizione non ha limiti di quota appropriati per la creazione di macchine virtuali corrispondenti alle dimensioni delle macchine virtuali di origine.
Per risolvere il problema, contattare il servizio di supporto per la fatturazione di Azure e richiedere di creare macchine virtuali di dimensioni appropriate nell'area di destinazione necessaria.
Uno o più dischi sono disponibili per la protezione
Questo errore si verifica se è stata completata la configurazione di Site Recovery per le macchine virtuali. Successivamente sono stati aggiunti o inizializzati altri dischi.
Per correggere l'errore, è possibile aggiungere la replica per i dischi appena aggiunti oppure è possibile scegliere di ignorare l'avviso relativo ai dischi.
Certificati radice trusted
Controllare che siano installati i certificati radice più recenti per consentire a Site Recovery di comunicare e di autenticare le macchine virtuali per la replica in modo sicuro. Questo errore può verificarsi se nelle macchine virtuali non sono installati gli aggiornamenti più recenti. Affinché Site Recovery possa abilitare la replica, aggiornare le macchine virtuali Windows e Linux.
La correzione è diversa per ogni sistema operativo. Per Windows è sufficiente garantire l'attivazione della funzionalità Windows Update automatica e l'applicazione degli aggiornamenti. Per ogni distribuzione Linux è necessario seguire le indicazioni fornite dal distributore.