Esercizio: Eseguire il training di un modello di Machine Learning
Sono stati raccolti i dati dei sensori dai dispositivi di produzione integri e da quelli che hanno generato errori. Si vuole ora usare Model Builder per eseguire il training di un modello di Machine Learning che predice se un computer genererà errori o meno. Grazie all'apprendimento automatico per automatizzare il monitoraggio di questi dispositivi, è possibile risparmiare denaro aziendale fornendo una manutenzione più tempestiva e affidabile.
Aggiungere un nuovo elemento Modello di Machine Learning (ML.NET)
Per avviare il processo di training, è necessario aggiungere un nuovo elemento Modello di Machine Learning (ML.NET) a un'applicazione .NET nuova o esistente.
Creare una libreria di classi C#
Poiché si inizia da zero, creare un nuovo progetto di libreria di classi C# in cui si aggiungerà un modello di Machine Learning.
Avviare Visual Studio.
Nella finestra iniziale selezionare Crea un nuovo progetto.
Nella finestra di dialogo Crea un nuovo progetto immettere libreria di classi nella barra di ricerca.
Selezionare Libreria di classi dall'elenco delle opzioni. Assicurarsi che il linguaggio sia C# e selezionare Avanti.
Nella casella di testo Nome progetto immettere PredictiveMaintenance. Lasciare i valori predefiniti in tutti gli altri campi e selezionare Avanti.
Selezionare .NET 6.0 (anteprima) nell'elenco a discesa Framework e quindi selezionare Crea per eseguire lo scaffolding della libreria di classi C#.

Aggiungere l'apprendimento automatico al progetto
Dopo l'apertura del progetto di libreria di classi in Visual Studio, è possibile aggiungere l'apprendimento automatico.
Fare clic con il pulsante destro del mouse sul progetto in Esplora soluzioni di Visual Studio.
Selezionare Aggiungi>Modello di Machine Learning.

Nell'elenco dei nuovi elementi della finestra di dialogo Aggiungi nuovo elemento selezionare Modello di Machine Learning (ML.NET).
Nella casella di testo Nome usare il nome PredictiveMaintenanceModel.mbconfig per il modello e selezionare Aggiungi.


Dopo alcuni secondi, al progetto viene aggiunto un file denominato PredictiveMaintenanceModel.mbconfig.
Scegliere lo scenario
La prima volta che si aggiunge un modello di Machine Learning a un progetto, si apre la schermata di Model Builder. È ora possibile selezionare lo scenario.
Per il caso d'uso, si sta tentando di determinare se un computer è danneggiato o meno. Poiché sono disponibili solo due opzioni e si vuole determinare lo stato di un computer, lo scenario di classificazione dei dati è il più appropriato.
Nel passaggio Scenario della schermata Model Builder, selezionare lo scenario Classificazione dei dati. Dopo aver selezionato questo scenario, si arriva immediatamente al passaggio Ambiente.

Scegliere l'ambiente
Per gli scenari di classificazione dei dati, sono supportati solo gli ambienti locali che usano la CPU.
- Nel passaggio Ambiente della schermata Model Builder, l'opzione Locale (CPU) è selezionata per impostazione predefinita. Lasciare selezionato l'ambiente predefinito.
- Selezionare Passaggio successivo.

Caricare e preparare i propri dati
Dopo aver selezionato lo scenario e l'ambiente di training, è possibile caricare e preparare i dati raccolti usando Model Builder.
Preparare i dati
Aprire il file in un editor di testo a scelta.
I nomi di colonna originali contengono caratteri speciali sotto forma di parentesi quadre. Per evitare problemi con l'analisi dei dati, rimuovere i caratteri speciali dai nomi di colonna.
Intestazione originale:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNFIntestazione aggiornata:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNFSalvare il file ai4i2020.csv con le modifiche apportate.
Scegliere il tipo di origine dati
Il set di dati di manutenzione predittiva è un file CSV.
Nel passaggio Dati della schermata Model Builder, selezionare File (csv, tsv, txt) per Tipo di origine dati.
Specificare il percorso dei propri dati
Selezionare il pulsante Sfoglia e usare Esplora file per specificare il percorso del set di dati ai4i2020.csv.
Scegliere la colonna di etichetta
Scegliere Errore del computer dall'elenco a discesa Colonna da prevedere (etichetta).

Scegliere le opzioni di dati avanzate
Per impostazione predefinita, tutte le colonne che non sono etichette vengono usate come funzionalità. Alcune colonne contengono informazioni ridondanti e altre non forniscono informazioni sulla previsione. Usare le opzioni di dati avanzate per ignorare tali colonne.
Selezionare Opzioni di dati avanzate.
Nella finestra di dialogo Opzioni di dati avanzate selezionare la scheda Impostazioni di colonna.
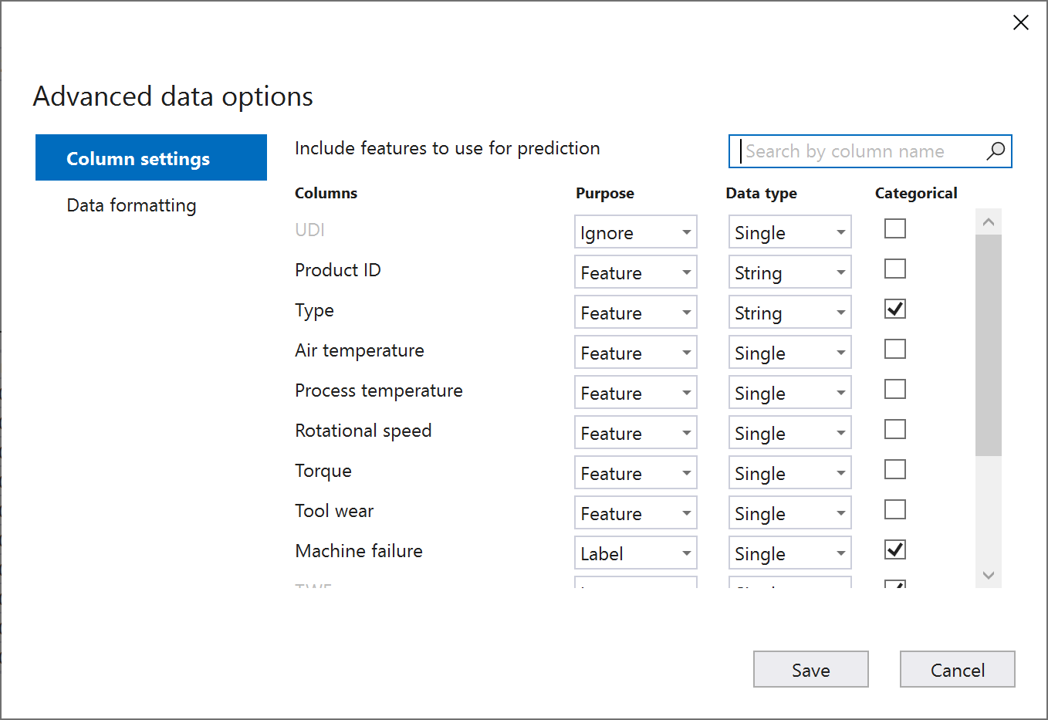
Configurare le impostazioni di colonna come descritto di seguito:
Colonne Scopo Tipo di dati Categorie UDI Ignora Singolo ID prodotto Funzionalità String Type Funzionalità String X Temperatura dell'aria Funzionalità Singolo Temperatura del processo Funzionalità Singolo Velocità rotazionale Funzionalità Singolo Coppia Funzionalità Singolo Usura degli strumenti Funzionalità Singolo Errore della macchina Etichetta Singolo X TWF Ignora Singolo X HDF Ignora Singolo X PWF Ignora Singolo X OSF Ignora Singolo X RNF Ignora Singolo X Seleziona Salva.
Nel passaggio Dati della schermata Model Builder selezionare Passaggio successivo.

Eseguire il training del modello
Usare Model Builder e AutoML per eseguire il training del modello.
Impostare il tempo di training
Model Builder imposta automaticamente la durata del training in base alle dimensioni del file. In questo caso, per consentire a Model Builder di esplorare più modelli, fornire un numero maggiore per il tempo di training.
- Nel passaggio Training della schermata Model Builder impostare Tempo di training (secondi) su 30.
- Seleziona Esegui il training.
Tenere traccia del processo di training

Dopo l'avvio del processo di training, Model Builder esplora vari modelli. Il processo di training viene tracciato nei risultati del training e nella finestra di output di Visual Studio. I risultati del training forniscono informazioni sul modello migliore che è stato trovato durante il processo di training. La finestra di output fornisce informazioni dettagliate, ad esempio il nome dell'algoritmo usato, il tempo necessario per il training e le metriche delle prestazioni per tale modello.
È possibile che venga visualizzato lo stesso nome di algoritmo più volte. Ciò si verifica perché, oltre a provare algoritmi diversi, Model Builder prova configurazioni di iperparametri diverse per tali algoritmi.
Valutare il modello
Usare metriche e dati di valutazione per testare le prestazioni del modello.
Esaminare il modello
Il passaggio Valuta della schermata Model Builder consente di esaminare le metriche di valutazione e l'algoritmo scelti per il modello migliore. Tenere presente che non è un problema se i risultati sono diversi da quelli indicati in questo modulo, perché l'algoritmo e gli iperparametri scelti potrebbero essere diversi.
Testare il modello
Nella sezione Prova il modello del passaggio Valuta è possibile fornire nuovi dati e valutare i risultati della previsione.

Nella sezione Dati di esempio vengono forniti i dati di input che il modello usa per eseguire previsioni. Ogni campo corrisponde alle colonne usate per eseguire il training del modello. Si tratta di un modo pratico per verificare che il modello si comporti come previsto. Per impostazione predefinita, Model Builder precompila i dati di esempio con la prima riga del set di dati.
Verrà ora testato il modello per verificare se produce i risultati previsti.
Nella sezione Dati di esempio immettere i dati seguenti. Provengono dalla riga del set di dati con UID 161.
Colonna Valore ID prodotto L47340 Type L Temperatura dell'aria 298,4 Temperatura del processo 308,2 Velocità rotazionale 1282 Coppia 60,7 Usura degli strumenti 216 Selezionare Stima.
Valutare i risultati della previsione
Nella sezione Risultati vengono visualizzati la previsione effettuata dal modello e il livello di attendibilità nella previsione.
Se si esamina la colonna Errore del computer di UID 161 nel set di dati, si noterà che il valore è 1. Corrisponde al valore previsto con la massima attendibilità nella sezione Risultati.
Se si vuole, è possibile continuare a provare il modello con valori di input diversi e valutare le previsioni.
Complimenti. È stato eseguito il training di un modello per prevedere gli errori del computer. Nell'unità successiva verranno fornite informazioni sull'utilizzo del modello.