Creazione di un proprio modello predittivo
È possibile creare un servizio Web predittivo basato su un modello pubblico denominato Esperimento di previsione per Dynamics 365 Business Central. Il modello predittivo è disponibile online in Microsoft Azure AI Gallery.
Per usare il modello predittivo, effettuare i seguenti passaggi:
Aprire un browser e accedere ad Azure AI Gallery.
Cercare Esperimento di previsione per Dynamics 365 Business Central, quindi aprire il modello nello studio di Microsoft Azure Machine Learning.
Nella pagina Esperimento di previsione per Dynamics 365 Business Central, selezionare il collegamento Apri in Studio (versione classica).
Quando richiesto, usare il proprio account Microsoft per iscriversi a un'area di lavoro, quindi copiare il modello.
Il modello è disponibile nell'area di lavoro.
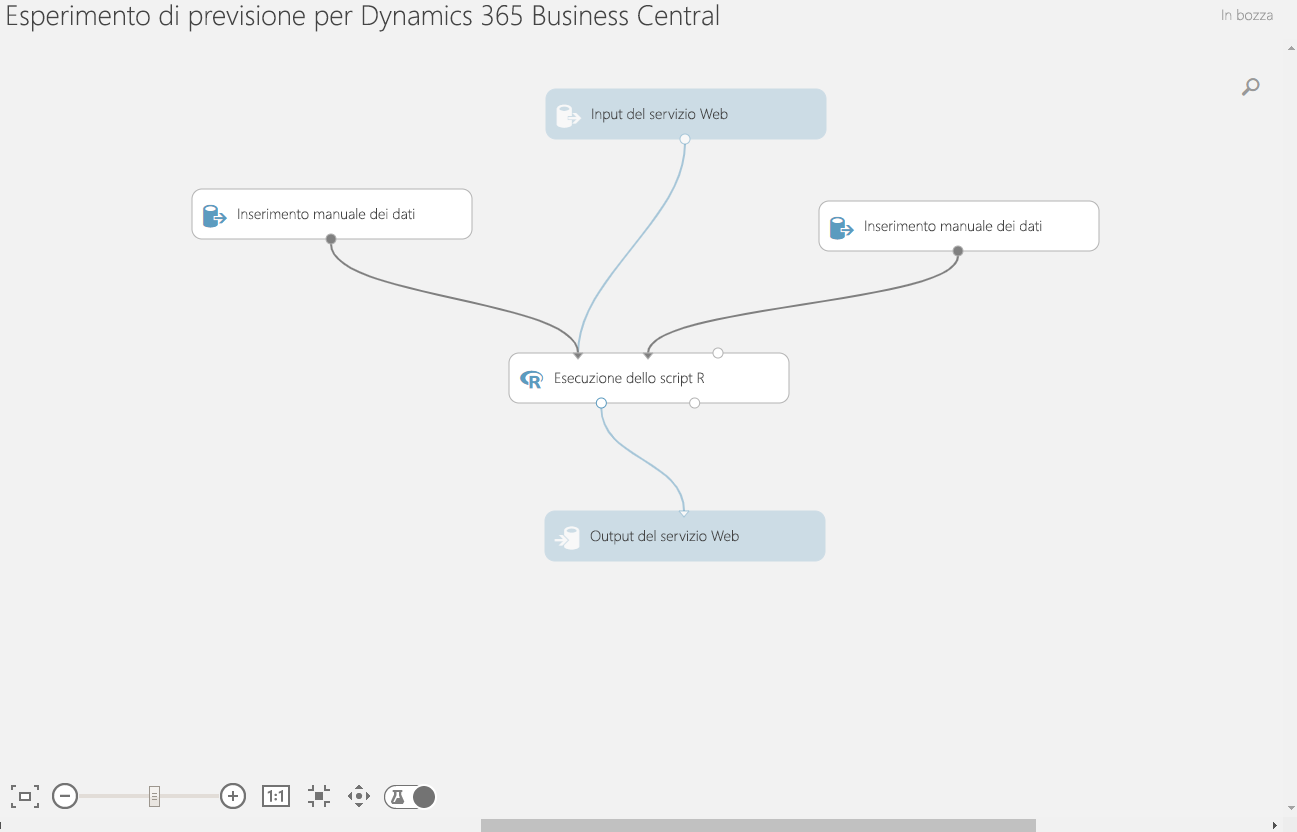
Nella parte inferiore della pagina selezionare Esegui > Esegui modello per eseguire il modello. Il completamento del processo può richiedere un paio di minuti.
Pubblicare il proprio modello come servizio Web selezionando Distribuisci servizio Web.
Una volta, il servizio Web dovrebbe avere un aspetto simile allo screenshot seguente.
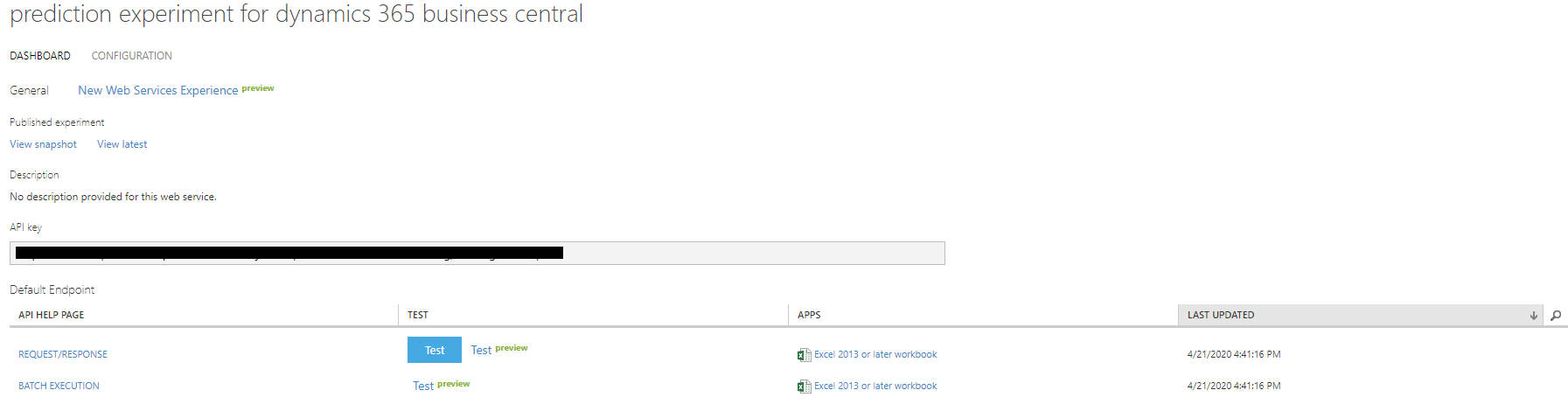
Prendere nota delle informazioni riportate nei campi URI API e Chiave API. Si possono usare queste credenziali per la configurazione di un flusso di cassa.
Selezionare l'icona Cerca una pagina, che apre la funzionalità Dimmi. Immettere Impostazione previsione pagamento ritardato, quindi selezionare il collegamento correlato.
Selezionare l'opzione Utilizza sottoscrizione di Azure personale.
Nella Scheda dettaglio Credenziali modello personale immettere l'URI API (selezionare RICHIESTA/RISPOSTA e copiare l'URI della richiesta) e la Chiave API per il modello.





Il modello di previsione per Microsoft Dynamics 365 Business Central consente di eseguire il training dei modelli nonché di valutarli e di visualizzarli a scopo di previsione. Il modello usa il modulo Esegui script R per eseguire gli script R che eseguono tutte le attività. I due moduli di input definiscono la struttura prevista dei set di dati di input. Il primo modulo definisce la struttura del set di dati, flessibile e in grado di accettare fino a 25 caratteristiche, mentre il secondo definisce i parametri.
Quando si chiama l'API, è necessario passare alcuni parametri:
method (stringa): parametro obbligatorio. Specifica la procedura di Machine Learning da usare. Il modello supporta i metodi indicati di seguito.
train (il sistema decide se usare la classificazione o la regressione in base al set di dati)
trainclassification
trainregression
predict
evaluate
plotmodel
In base al metodo selezionato, possono essere necessari ulteriori parametri:
train_percent (numerico): obbligatorio per i metodi train, trainclassification e trainregression. Specifica come dividere un set di dati in set di training e convalida. Il valore 80 indica che l'80% del set di dati viene usato per il training e il 20% per la convalida del risultato.
model (stringa; Base64): obbligatorio per i metodi predict, evaluate e plotmodel. Questo parametro è un modello serializzato di contenuto ed è codificato con Base64. il parametro model può essere ottenuto come risultato dei metodi train, trainclassification o trainregression.
captions (stringa): parametro facoltativo usato con il metodo plotmodel che contiene didascalie separate da virgole per le caratteristiche. Se non viene passato, viene usato Feature1..Feature25.
labels (stringa): parametro facoltativo usato con il metodo plotmodel che contiene didascalie alternative separate da virgole per le etichette. Se non viene passato, vengono usati i valori effettivi.
dataset: obbligatorio per i metodi train, trainclassification, trainregression, evaluate e predict ed è costituito dai parametri indicati di seguito.
Feature1..25: le caratteristiche sono gli attributi descrittivi (noti anche come dimensioni) che descrivono la singola osservazione (record nel set di dati). Il tipo può essere intero, decimale, booleano, opzione, codice o stringa.
Label: parametro obbligatorio che deve essere vuoto per il metodo predict. Il parametro label indica ciò che si tenta di prevedere.
L'output del servizio include i parametri seguenti:
model (stringa; Base64): risultato dell'implementazione dei metodi train, trainclassification e trainregression. Questo parametro contiene il modello serializzato ed è codificato con Base64.
quality (numerico): risultato dell'implementazione dei metodi train, trainclassification, trainregression ed evaluate. Nell'esperimento corrente, è possibile usare il punteggio Balanced Accuracy come misura della qualità di un modello.
plot (applicazione/pdf; Base64): risultato dell'implementazione del metodo plotmodel. Questo parametro contiene la visualizzazione del modello in formato PDF, codificato con Base64.
dataset: risultato dell'implementazione del metodo predict ed è costituito dai parametri indicati di seguito.
Feature1..25: questo parametro corrisponde all'input.
Label: valore previsto.
Confidence: probabilità che la classificazione sia corretta.